
LoRA là gì? Có thể bạn đã nghe đến thuật ngữ này nhiều lần. Nó thực sự là một khái niệm quan trọng nếu bạn muốn finetune GPT. Trong bài viết này, hãy cùng trituenhantao.io tìm hiểu về phương pháp fine-tuning LoRA (viết tắt của “Low-Rank Adaptation of Large Language Models”). Đầu tiên, hãy bắt đầu với kỹ thuật LoRA, kiến trúc và những ưu điểm của nó. Chúng ta cũng sẽ tìm hiểu những kiến thức nền tảng liên quan, chẳng hạn như các khái niệm về “low-rank” và “adaptation”. Bài viết sẽ đặc biệt đề cập đến bản chất của việc tiêu thụ GPU trong fine-tuning Mô hình ngôn ngữ lớn (LLM). Sau đó, ta sẽ đi sâu hơn về các phương pháp xử lý thực tế đã được trinh bày dưới dạng thư viện Python “bitsandbytes” và “accelerate”. Sau khi hoàn thành bài viết này, bạn sẽ có thể hiểu rõ:
- Khi nào chúng ta vẫn cần fine-tuning?
- Những thách thức trong việc thêm nhiều layer hơn – Độ trễ inference
- “Rank” trong “low-rank” của LoRA là gì?
- Kiến trúc LoRA
- Ưu điểm LoRA
- Fine-tuning vẫn tiêu tốn nhiều GPU
- Các kỹ thuật để giảm việc sử dụng GPU
- Ví dụ mã
Tại sao chúng ta vẫn cần fine-tuning?
Các Mô hình ngôn ngữ lớn được đào tạo trước (LLM) đã được đào tạo với các loại dữ liệu khác nhau cho các nhiệm vụ khác nhau như tóm tắt văn bản, tạo văn bản, câu hỏi và trả lời, v.v. Tại sao chúng ta vẫn cần fine-tuning LLM? Lý do đơn giản là để đào tạo LLM thích ứng với dữ liệu miền của bạn nhằm thực hiện các tác vụ cụ thể. Giống như một người đầu bếp đã được đào tạo bài bản để có thể nấu món Ý hoặc món Hoa, sau đó người đầu bếp chỉ cần sử dụng kiến thức nấu nướng cơ bản và mài giũa kỹ năng của mình để chế biến các món ăn khác. Thuật ngữ “transfer learning” và “fine-tuning” đôi khi được sử dụng thay thế cho nhau trong NLP.
Những thách thức trong việc thêm nhiều layer hơn – Độ trễ inference
Vì độ lớn của LLM đang tăng lên một cách chưa từng có nên chúng ta sẽ cố gắng không đề cập đến các tham số đã được đào tạo mà sẽ thêm các layer vào LLM hoặc thêm giá trị vào các tham số. Các layer được thêm vào thường được gọi là “adapters” và kỹ thuật fine-tuning được gọi là “adapter-tuning”. Nó liên quan đến việc thêm các mô-đun adapter nhỏ vào mô hình được đào tạo trước và chỉ đào tạo các tham số trong mô-đun adapter.
Tuy nhiên, người ta phát hiện ra rằng các layer bổ sung gây ra độ trễ trong quá trình dự đoán, được gọi là “Độ trễ Inference”. Sẽ không dễ chịu nếu bạn phải đợi hơn 20 giây để LLM đưa ra câu trả lời. Sự cố này dường như không thể tránh khỏi vì các adapter layer được thêm tuần tự vào LLM, chúng phải được xử lý tuần tự và không có cách nào để xử lý song song. Bạn có thể sẽ thắc mắc tại sao không sử dụng batching để chia dữ liệu nhằm đạt tốc độ nhanh hơn. Ý kiến đó hay đấy. Nhưng trong quá trình sử dụng hoặc suy luận theo thời gian thực, người dùng thường nhập lần lượt từng prompt hoặc câu hỏi, do đó batch size là 1 và không có nhiều dữ liệu được batching. Giải pháp là gì? Một điều đáng chú ý là LoRA không thêm layer mà thêm giá trị vào tham số. Giải pháp này sẽ không gây ra độ trễ inference. Ta sẽ sớm đi sâu vào kiến trúc của LoRA, nhưng tại thời điểm này, tất cả những gì bạn cần nhớ là: có các chiến lược fine-tuning khác nhau và chiến lược adapt-tuning có thể gây ra độ trễ inference.
Tiêu đề của LoRA là “Low-Rank Adaptation of Large Language Models”. Bây giờ chúng ta đã biết “adaptation” có nghĩa là fine-tuning dữ liệu và tác vụ miền. Nó không được gọi là “adapter” vì nó không thêm adapter. Nó được gọi là “adaption” để mô tả quá trình thích ứng của nó.
Bây giờ chúng ta đã sẵn sàng để bắt đầu phần kiến trúc, hãy tiếp tục với “low-rank” trong LoRA.
“Rank” trong “low-rank” của LoRA là gì?
Định nghĩa về “rank” của ma trận là số cột độc lập tuyến tính tối đa của ma trận. Dưới đây, chúng ta thể hiện hiển thị ma trận 2 * 3 V và ma trận chuyển vị của nó với chiều 3 * 2. Lưu ý rằng hai hàng của V hoàn toàn đối nhau. Chúng không độc lập tuyến tính. Hàng độc lập tuyến tính duy nhất là hàng đầu tiên. Vì vậy, cấp của V là 1. Tương tự như vậy, cấp chuyển vị của nó cũng là 1.
V = \begin{bmatrix} 1 & 2 & 1 \\ -1 & -2 & -1 \end{bmatrix} V^T = \begin{bmatrix} 1 & -1 \\ 2 & -2 \\ 1 & -1 \end{bmatrix}Các hàng hoặc cột bổ sung không có độc lập tuyến tính và có thể được xây dựng lại bởi các hàng hoặc cột khác. Với thuộc tính này, mặc dù ma trận có thể rất lớn nhưng thông tin thực sự của nó chỉ nằm trên các hàng hoặc cột độc lập.
Bây giờ, hãy bắt đầu với kiến trúc của LoRA.
Kiến trúc LoRA
LoRA đào tạo và lưu trữ các thay đổi trọng số bổ sung trong ma trận, trong khi đóng băng tất cả các trọng số mô hình được đào tạo trước đó. Thiết kế này nằm trong mỗi layer của kiến trúc Transformer. Bạn có thể đặt câu hỏi ngay rằng số lần thay đổi trọng số vẫn bằng số lượng tham số trong mô hình được đào tạo trước, vì vậy chúng ta vẫn đang đào tạo số lượng lớn tham số đó. Hãy sử dụng ký hiệu để mô tả điều này ngắn gọn hơn nhằm giải thích giải pháp của LoRA. Đặt tất cả các tham số của LLM trong ma trận W_0 và trọng số bổ sung thay đổi trong ma trận \Delta W, các trọng số cuối cùng trở thành W_0 + \Delta W. Các tác giả của LoRA [1] đề xuất rằng sự thay đổi trong ma trận thay đổi trọng số \Delta W có thể phân tách thành hai ma trận cấp thấp A và B. LoRA không đào tạo trực tiếp các tham số trong \Delta W mà đào tạo các tham số trong A và B. Vì vậy số lượng tham số có thể đào tạo được sẽ thấp hơn rất nhiều. Giả sử kích thước của A là 100 \times 1 và B là 1 \times 100 thì số tham số trong \Delta W sẽ là 100 \times 100 = 10000. Chỉ có 100 + 100 = 200 để đào tạo ở A và B, thay vì 10000 để đào tạo ở \Delta W.
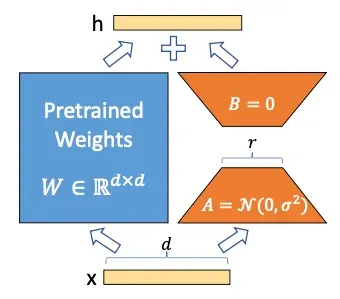
Hình trên là bản in lại hình ảnh trong bài viết [1]. Giả sử ma trận trọng số được đào tạo trước là W_0. Kích thước của nó là d * k. Nó sẽ bị đóng băng trong quá trình đào tạo mô hình. Ma trận được cập nhật là \Delta W với thứ nguyên d * k. Ma trận cập nhật \Delta W có thể được phân tách thành A và B. Kích thước của A là r * k và kích thước của B là d * r. Sau khi hoàn thành quá trình đào tạo, W_0 và \Delta W sẽ được lưu trữ riêng. Khi một đầu vào x mới đi vào mô hình tinh chỉnh LoRA, x sẽ được nhân riêng với W và \Delta W. Giả sử kích thước của x là 1 * d. Vậy chiều của x nhân với W trở thành 1 * k, và chiều của x nhân với \Delta W cũng là 1 * k. Hai vectơ đầu ra được tính tổng theo tọa độ để trở thành đầu ra cuối cùng h.
Hãy vẽ lại để giải thích giải pháp low-rank một cách tốt hơn. Ma trận mới \Delta W là tích của hai ma trận cấp thấp A và B.
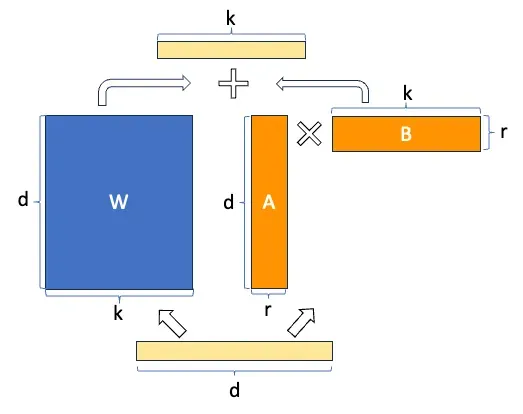
Hãy tập trung vào việc lựa chọn chiều r. Thứ nguyên r xác định cấp của A và B có thể nhỏ đến mức nào. Nó là một siêu tham số. Một r nhỏ sẽ dẫn tới ít tham số cần điều chỉnh hơn. Mặc dù nó sẽ rút ngắn thời gian đào tạo nhưng cũng có thể dẫn đến mất thông tin và giảm hiệu suất của mô hình khi r trở nên nhỏ hơn.
Bạn có thể nhận thấy ý tưởng trên là một loại kỹ thuật phân rã ma trận. Vậy Phân rã vectơ đơn (Singular Vector Decomposition (SVD)) là gì? Nó nói rằng một ma trận lớn có thể được phân tách thành ba ma trận nhỏ hơn. Ba ma trận nhỏ hơn có thể “tái tạo” ma trận lớn mà không mất nhiều thông tin. Hình 3 minh họa ý tưởng của \text{SVD}. Ma trận A có thể được phân tách thành ba ma trận. Chúng ta có thể sắp xếp lại các hàng của ma trận U theo thứ tự giảm dần. Vùng màu xanh trong ma trận U biểu thị các cột có giá trị và vùng màu trắng biểu thị các cột có giá trị rất nhỏ. Mặc dù kích thước của ma trận U là m \times n, nhưng nó có thể được rút gọn thành ma trận m \times k (k < n). Các phép toán ma trận tương tự áp dụng cho hai ma trận còn lại. Chúng ta sẽ chọn giá trị của k sao cho càng nhỏ càng tốt nhưng cố gắng không để mất quá nhiều thông tin.
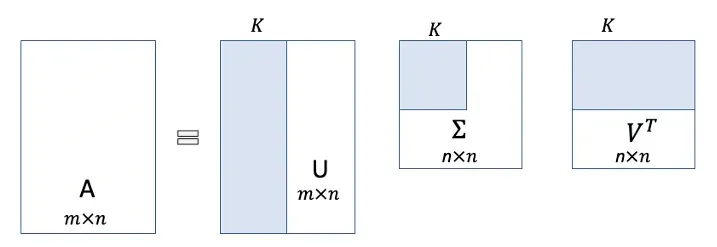
Tại sao bạn lại cần quan tâm đến SVD? Lựa chọn k nhỏ làm cho SVD có cấp thấp. Tương tự, khi tinh chỉnh \text{LoRA}, chúng ta chọn giá trị r để giảm kích thước của ma trận A và B, r lớn có nghĩa là có nhiều tham số cần tinh chỉnh hơn, tức là một mô hình phức tạp và r nhỏ sẽ không học được nhiều thông tin như vậy. Do đó việc lựa chọn r cần phải cân bằng giữa độ phức tạp và hiệu suất của mô hình.
Ưu điểm của LoRA
Bên cạnh việc không có độ trễ inference như đã giải thích ở trên, hãy cùng xem xét thêm các ưu điểm của LoRA.
Đầu tiên là giảm số lượng tham số đào tạo. Các tác giả của [1] đã ghi lại rằng “so với GPT-3 175B được tinh chỉnh với Adam, LoRA có thể giảm số lượng tham số đào tạo 10.000 lần và giảm yêu cầu bộ nhớ GPU đi 3 lần.” Một lợi thế liên quan là thiết kế cấp thấp của nó. Bởi vì nó chỉ tối ưu hóa các ma trận cấp thấp nên mang lại hiệu quả cho việc đào tạo mô hình.
Ưu điểm tiếp theo là tính mô-đun. Bạn có thể xây dựng nhiều mô-đun LoRA nhỏ cho các nhiệm vụ khác nhau. Ưu điểm của tính mô-đun này tương tự như lợi thế của việc điều chỉnh tiền tố. Ví dụ: bạn có thể xây dựng mô-đun LoRA trên LLM cơ sở để tóm tắt văn bản và một mô-đun LoRA khác trên cùng LLM cơ sở cho câu hỏi và câu trả lời. Khi hai mô hình tinh chỉnh được triển khai để suy luận theo thời gian thực, bạn chỉ cần tải cùng một mô hình cơ sở một lần. Với kích thước vật lý của LLM ở mức hơn 100 GB, không thể bỏ qua lợi thế này.
Có lẽ bây giờ bạn cũng đang muốn làm việc trên LoRA giống như tôi. Nhưng chờ đã, hãy để tôi đưa ra một thử thách thực tế cho tất cả các tác vụ tinh chỉnh – hạn chế về bộ nhớ và GPU.
Fine-tuning vẫn tiêu tốn nhiều GPU
Tuy chúng ta hài lòng với chiến lược không chạm tới hàng tỷ tham số trong mô hình được đào tạo trước nhưng các thách thức vẫn chưa kết thúc. Việc tinh chỉnh LLM cũng cần nhiều GPU. Như một bài viết đã nói, chỉ để sử dụng (hoặc gọi là suy luận) mô hình BLOOM-176B sẽ yêu cầu GPU A100 8x 80GB. Nếu chúng ta muốn tinh chỉnh BLOOM-176B, chúng ta sẽ cần 72 GPU này. Các mô hình lớn hơn nhiều như PaLM thậm chí còn đòi hỏi nhiều tài nguyên hơn.
Có rất nhiều nỗ lực chung nhằm giảm việc sử dụng GPU trong suy luận và tinh chỉnh mô hình. Một bước phát triển quan trọng là suy luận Int8 có thể giảm một nửa yêu cầu bộ nhớ mà không làm giảm hiệu năng của mô hình. Vì vậy hãy để tôi mô tả nó.
Các kỹ thuật để giảm việc sử dụng GPU
Chúng ta đều biết kích thước của một mô hình được xác định bởi số lượng tham số của nó, thực tế rằng độ chính xác của một tham số cũng quyết định rất lớn đến kích thước của mô hình. Một tham số thường được lưu trữ và trình bày trong float32. Float32 (FP32) là viết tắt của biểu diễn dấu phẩy động 32-bit IEEE được tiêu chuẩn hóa. Hình dưới biểu diễn dấu phẩy động 32 bit cho giá trị 0.15625. Biểu diễn 32 bit cho tất cả các tham số làm cho kích thước mô hình rất lớn.

Chúng ta có thể làm gì? Cộng đồng nghiên cứu đã đưa ra một định dạng mới, bfloat16 (BF16). Định dạng BF16 yêu cầu 2 byte so với định dạng FP32 yêu cầu 4 byte. Vì lý do này, định dạng FP32 được gọi là độ chính xác đầy đủ (4 byte) và định dạng BF16 có độ chính xác một nửa (2 byte).
Làm cách nào chúng ta có thể duy trì độ chính xác của các tham số và giảm yêu cầu về GPU? Chiến lược là áp dụng cách tiếp cận có độ chính xác hỗn hợp. Nó giữ các tham số của mô hình được đào tạo trước trong FP32 làm trọng số chính trong khi thực hiện tính toán trong BP16. Trong quá trình tinh chỉnh, việc tính toán độ dốc được thực hiện trong FP16, sau đó được sử dụng để cập nhật các tham số chính.
Tuy nhiên, việc sử dụng BP16 với định dạng FP32 vẫn không làm giảm kích thước của mô hình xuống mức dễ quản lý hơn. Để khắc phục thách thức này, bài viết của Tim Dettmers, Mike Lewis, Younes Belkada và Luke Zettlemoyer [3] giới thiệu phương pháp lượng tử hóa 8 bit (Int8). Bởi vì nó là 8 bit, tức 1/4 của 32 bit, nên nó có khả năng giảm kích thước của mô hình xuống còn 1/4. Rõ ràng, điều này không dễ dàng như vậy, nó sẽ gây ra sự xuống cấp của mô hình, việc dự đoán mô hình cũng sẽ bị ảnh hưởng. Biện pháp khắc phục là gì? Họ phát hiện ra rằng trong phép tính nhân ma trận, các giá trị outlier quan trọng hơn các giá trị non-outlier. Vì vậy, các giá trị outlier có thể được lưu trữ trong FP16 trong khi các giá trị non-outlier ở định dạng 8 bit hoặc được gọi là int8. Sau đó, các giá trị outlier và non-outlier được ghép với nhau để nhận kết quả đầy đủ trong FP16. Quá trình này đã được phát triển trong thư viện bitandbytes.
Tất cả các chức năng quản lý GPU ở trên đã được đưa vào thư viện accelerate và bitandbytes. Ở phần sau của mã, chúng ta sẽ thực hiện cài đặt pip để cài đặt các thư viện này.
Ví dụ mã
Mô hình cơ sở và tập dữ liệu trong ví dụ này giống với mô hình trong bài trước “Fine-tune a GPT — Prefix-tuning”. Ví dụ này sẽ tinh chỉnh mô hình được đào tạo trước “bigscience/bloomz-7b1” với tập dữ liệu Twitter đặc biệt có các nhận xét và nhãn tweet cho “khiếu nại” và “không phải khiếu nại”.
(1) Tải thư viện
Đầu tiên, hãy cài đặt các thư viện sau. Như đã giải thích trước đó, thư viện accelerate và bitandbytes được phát triển để quản lý việc sử dụng GPU.
!pip install -q bitsandbytes accelerate loralib datasets loralib !pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
(2) Mô hình nguồn
Open Pre-trained Transformers (OPT) được Meta AI phát hành lần đầu tiên vào ngày 3 tháng 5 năm 2022. OPT là một Transformer được đào tạo trước chỉ dành cho bộ giải mã có các tham số từ 125M đến 175B. Nó được đào tạo như một mô hình ngôn ngữ nhân quả. OPT thuộc cùng dòng mô hình chỉ có bộ giải mã như GPT-3. Chúng ta sẽ sử dụng 6.7 tỷ tham số “opt-6.7b” làm mô hình cơ sở.
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-6.7b",
load_in_8bit=True,
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-6.7b")
Để sử dụng mô hình cơ sở này, chúng ta vẫn cần chuẩn bị nó để có thể tinh chỉnh.
(3) Chuẩn bị mô hình để tinh chỉnh
Thư viện left có lớp prepare_model_for_kbit_training() để chuẩn bị tinh chỉnh mô hình. (Lớp prepare_model_for_kbit_training() được mở rộng từ lớp prepare_model_for_int8_training() không được dùng nữa.)
from peft import prepare_model_for_kbit_training model = prepare_model_for_kbit_training(model)
Khối mã dưới đây có tác dụng tương tự nhưng nó thể hiện chi tiết hơn những gì đã được đóng gói, bạn vẫn có thể sử dụng một dòng mã ở trên.
for param in model.parameters():
param.requires_grad = False # freeze the model - train adapters later
if param.ndim == 1:
# cast the small parameters (e.g. layernorm) to fp32 for stability
param.data = param.data.to(torch.float32)
model.gradient_checkpointing_enable() # reduce number of stored activations
model.enable_input_require_grads()
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float32)
model.lm_head = CastOutputToFloat(model.lm_head)
Đầu tiên, nó đưa tất cả các mô-đun không phải int8 đến độ chính xác hoàn toàn (fp32) như tôi đã giải thích trong Phần trước “Các thư viện để giảm việc sử dụng GPU”. Sau đó, nó thêm forward_hook vào lớp nhúng đầu vào. Điều này cho phép tính toán và kiểm tra gradient.
Các mô tả ở trên yêu cầu nhiều thông tin cơ bản hơn và có thể không hấp dẫn bạn. Mặc dù vậy, nó sẽ không ngăn cản bạn sử dụng LoRA. Vậy hãy tiếp tục nào!
(4) Áp dụng LoRA
Trước tiên hãy hiểu có bao nhiêu tham số có thể đào tạo được. Hàm dưới đây đếm số lượng tham số có thể đào tạo.
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
param.requires_grad là hàm PyTorch cho biết một tham số có thể đào tạo được hay không. Nếu đúng thì tham số có thể đào tạo được. Hàm này cũng đếm có bao nhiêu tham số có thể đào tạo được. Chúng ta sẽ sử dụng hàm này cùng với LoRA để xem số lượng tham số có thể đào tạo và tổng tham số.
Huggingface có thư viện “Tinh chỉnh hiệu quả tham số (Parameter-Efficient Fine-Tuning)” (PEFT) bao gồm Tinh chỉnh tiền tố và LoRA. Lớp LoraConfig trước tiên sẽ xác định kỹ thuật LoRA. Lớp get_peft_model sẽ gói LoRA vào mô hình và trả về mô hình LoRA. (Bạn có thể tìm thêm chi tiết trong github).
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
Hãy cùng xem các siêu tham số trên trong lớp LoraConfig().
- r là chiều tập trung của Lora. Nó được đặt thành 16. Mặc định là 8.
- lora_alpha là tham số alpha để chia tỷ lệ Lora. Nó được đặt thành 32. Mặc định là 8.
- lora_dropout là xác suất dropout của các lớp Lora. Mặc định là 0.0. Ở đây được đặt thành 0.05 hoặc 5%.
- bias là loại thiên vị. Nó có thể là “không có”, “tất cả” hoặc “lora_only”. Mặc định là “không có”.
- task_type là loại mô hình. Ở đây chúng ta đang sử dụng mô hình ngôn ngữ nhân quả nên giá trị là “CAUSAL_LM”. Nếu bạn đang chạy mô hình Phân loại trình tự (Sequence-Classification), giá trị sẽ là “SEQ_CLS”. Nếu đó là Mô hình ngôn ngữ theo trình tự (Sequence-to-Sequence-Language-Model), giá trị sẽ là “SEQ_2_SEQ_LM”. Nếu đó là mô hình phân loại mã thông báo (Token-classification), chẳng hạn như gắn thẻ Nhận dạng thực thể được đặt tên (NER) và Gán nhãn từ loại (Part-of-Speech/PoS), thì đó phải là “TOKEN_CLS”.
- target_modules là danh sách tên mô-đun.
Đầu ra là: trainable params: 8388608 || all params: 6666862592 || trainable%: 0.12582542214183376. Kỹ thuật LoRA cho phép chúng ta đào tạo một tập tham số chỉ bằng 12.5% số tham số ban đầu.
Chúng ta đã làm rõ LoRA và mô hình. Bây giờ hãy chuyển sang phần dữ liệu.
(5) Nguồn dữ liệu tinh chỉnh
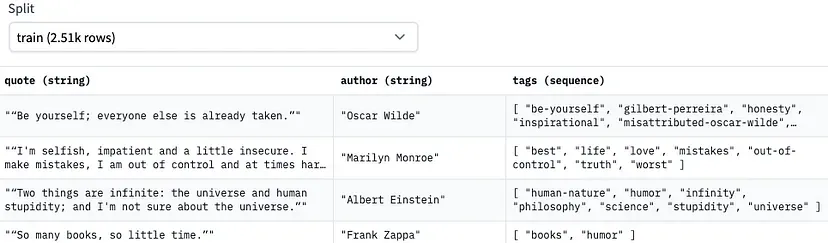
Chúng ta sẽ sử dụng tập dữ liệu “Abirate/english_quotes” có sẵn trên trang Huggingface, nó chứa tất cả các trích dẫn được lấy từ goodreads qoutes. Tập dữ liệu này là lý tưởng để đào tạo một mô hình tạo văn bản. Dưới đây là ảnh chụp nhanh về định dạng dữ liệu. Nó có cột trích dẫn, cột tác giả và cột thẻ cho nhiều nhãn. Do có cột thẻ nên tập dữ liệu cũng là lý tưởng để đào tạo mô hình phân loại văn bản nhiều nhãn.
(6) Tiền xử lý dữ liệu
Dữ liệu sẽ được mã hóa để đào tạo mô hình. Chúng ta sẽ sử dụng lớp load_dataset rất hữu ích trong thư viện datasets. Thư viện này có nhiều công cụ có thể định hình tập dữ liệu, tạo cột bổ sung hoặc chuyển đổi giữa các tính năng và định dạng. Chúng ta sẽ sử dụng hàm .map() của nó để áp dụng cho tập dữ liệu.
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples['quote']), batched=True)
Đoạn mã trên áp dụng mã thông báo cho các mẫu. Lưu ý rằng có một tham số xử lý hàng loạt batched=True . Nó cho phép các hoạt động (trong trường hợp của chúng ta là mã thông báo) được thực hiện theo đợt. Nếu nó được đặt thành sai, các hoạt động xử lý trước dữ liệu sẽ được thực hiện cho từng mẫu riêng lẻ và sẽ mất nhiều thời gian hơn.
(7) Đào tạo mô hình
Đào tạo mô hình đòi hỏi nhiều tham số kỹ thuật. Lớp Trainer và lớp TrainingArguments cho phép bạn chỉ định mọi thứ trong đào tạo mô hình. Trainer() chỉ định
- mô hình được đào tạo trong “model=”,
- nguồn dữ liệu trong “train_dataset=”,
- tất cả các tham số mô hình quan trọng trong “args=”,
- xử lý dữ liệu trong “data_collator=”.
Hãy đọc mã sau:
import transformers
trainer = transformers.Trainer(
model=model,
train_dataset=data['train'],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
max_steps=200,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir='outputs'
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
TrainingArguments là một lớp lớn cho phép bạn chỉ định quy trình đào tạo của một mô hình. Nó chứa hơn 80 chức năng. Các tham số trên đều nhằm mục đích đẩy nhanh quá trình đào tạo mô hình.
Trợ giúp per_device_train_batch_size là một siêu tham số quan trọng giúp tăng tốc độ tính toán. Kích thước batch là số lượng mẫu được chuyển qua mô hình cùng một lúc. Giả sử có 100.000 ảnh được gộp thành 32 ảnh mỗi đợt thì sẽ có 100.000/32 = 3.125 đợt. Một kỳ sẽ trải qua tất cả 3.125 đợt. Nếu bạn đào tạo mô hình mà không chia dữ liệu thành các đợt, mô hình phải lưu trữ tất cả các giá trị lỗi cùng nhau trong bộ nhớ. Để hiểu rõ hơn về kích thước batch, bạn có thể xem “Transfer Learning for Image Classification — (6) Build and Fine-tune the Transfer Learning Model” hoặc cuốn sách “Transfer learning for image classification”.
gradient_accumulation_steps giúp tăng tốc độ tính toán. Trong một mô hình mạng thần kinh điển hình, độ dốc được tính toán cho toàn bộ batch cùng một lúc, do đó rất tốn thời gian. Chúng ta có thể tính toán độ dốc lặp đi lặp lại theo các batch nhỏ hơn bằng cách thực hiện phương pháp forward and backward trên mô hình và tích lũy độ dốc. Sau khi tích lũy đủ độ dốc, chúng ta sẽ chạy quy trình tối ưu hóa. Điều này giúp tăng batch size tổng thể để tăng tốc.
warmup_steps chỉ định số bước trong quá trình “khởi động” trình tối ưu hóa. Trong một số bước đầu tiên của trình tối ưu hóa, mô hình sẽ được điều chỉnh để tìm hiểu dữ liệu. Tại đây nó được đặt ở mức 100. Siêu tham số này thông báo cho mô hình rằng 100 bước đầu tiên là các bước khởi động. Trong các bước khởi động, tốc độ học tập khá thấp.
Sau 100 bước đầu tiên, tốc độ học tập sẽ đi theo bất kỳ learning rate cụ thể nào. Siêu tham số này đi cùng với learning_rate.
learning_rate là một siêu tham số kiểm soát tốc độ thuật toán cập nhật các tham số hoặc tìm hiểu các giá trị của tham số. Nhiều độc giả đã quen thuộc với tốc độ học. Nếu muốn được giải thích thêm, bạn có thể xem tìm xem bài viết “My lecture notes on random forest, gradient boosting, regularization, and H2O.ai”.
fp16 còn được gọi là “độ chính xác một nửa”. Nó là một định dạng số máy tính dấu phẩy động chiếm 16 bit. Khi fp16 đúng, nó cho mô hình biết rằng chúng ta không yêu cầu độ chính xác cực cao và không cần lưu trữ quá nhiều dấu thập phân. Điều này có thể làm giảm đáng kể kích thước của một mô hình.
Tiếp theo, hãy tìm hiểu về DataCollator. Các bộ thu thập dữ liệu tạo thành các batch cho dữ liệu. DataCollator có nhiều lớp chuẩn bị dữ liệu cho các loại mô hình khác nhau. Các lớp này bao gồm “DefaultDataCollator()”, “DataCollatorWithPadding()”, “DataCollatorForTokenClassification()”, “DataCollatorForSeq2Seq()”, “DataCollatorForLanguageModeling()”, “DataCollatorForWholeWordMask()”, v.v. Theo tên của chúng, chúng ta biết chúng đang hình thành các batch dữ liệu cho các loại dữ liệu và nhiệm vụ lập mô hình khác nhau.
Có một siêu tham số mlm thú vị về việc có nên sử dụng mô hình ngôn ngữ mask hay không. Nếu nó được đặt thành False thì nhãn mục tiêu giống với thông tin đầu vào và padding token bị bỏ qua (padding token được đặt thành -100). Trong trường hợp của chúng ta, vì không đào tạo mô hình ngôn ngữ mask nên nó được đặt thành False.
trainer.train() thực thi việc xây dựng mô hình. Đây sẽ là một bước tốn thời gian. Hãy cùng thư giãn và chờ kết quả.
(8) Lưu mô hình
Cuối cùng chúng ta sẽ lưu lại mô hình để sử dụng cho lần sau. Hãy lưu mô hình bằng cách đẩy nó vào Huggingface. Bạn cũng có thể lưu mô hình đã được tinh chỉnh cục bộ.
from huggingface_hub import notebook_login
notebook_login()
model.push_to_hub("ybelkada/opt-6.7b-lora", use_auth_token=True)
(9) Load mô hình
Khi tải mô hình, chúng ta sẽ tải mô hình cơ sở và các tham số LoRA.
import torch from peft import PeftModel, PeftConfig from transformers import AutoModelForCausalLM, AutoTokenizer peft_model_id = "ybelkada/opt-6.7b-lora" config = PeftConfig.from_pretrained(peft_model_id) model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, return_dict=True, load_in_8bit=True, device_map='auto') tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path) # Load the Lora model model = PeftModel.from_pretrained(model, peft_model_id)
Dòng mã config=PeftConfig.from_pretrain(peft_model_id) biểu thị đây là mô hình được tinh chỉnh LoRA. Dòng model=… tải mô hình cơ sở và dòng tokenizer=… tải tokenizer Cuối cùng, dòng model=PeftModel.from_pretrain(model, peft_model_id) đặt mô hình cơ sở và các tham số LoRA lại với nhau.
(10) Mô hình dự đoán
Bây giờ chúng ta có thể sử dụng mô hình tinh chỉnh theo thời gian thực. Mô hình được tinh chỉnh theo tất cả các quote và có thể hoàn thành các qoute. Giả sử bạn gõ “Two things are infinite:” (“Có hai thứ là vô hạn:”) để yêu cầu mô hình hoàn thành nó.
Mô hình trả về:
“Two things are infinite: the universe and human stupidity; and I’m not sure about the universe. I’m not sure about the universe either.” (“Có hai thứ là vô hạn: vũ trụ và sự ngu ngốc của con người; và tôi không chắc chắn về vũ trụ. Tôi cũng không chắc chắn về vũ trụ.”)
Không hoàn hảo nhưng cũng không tệ, phải không?
Hy vọng điều này sẽ giúp bạn hiểu LoRA và cách áp dụng nó để tinh chỉnh mô hình.
Tổng kết
Bài đăng này giải thích việc tinh chỉnh, kiến trúc của LoRA và các ưu điểm của nó. Chúng ta đã biết tại sao việc tinh chỉnh vẫn đòi hỏi nhiều GPU và các giải pháp mới nhất. Chúng ta cũng đã xem qua một ví dụ về mã để xây dựng mô hình tinh chỉnh LoRA. Nếu bạn thích bài viết, hãy chia sẻ với những người quan tâm và trituenhantao.io xin hẹn gặp lại bạn trong các bài viết tiếp theo.
Tham khảo
- [1] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, & Weizhu Chen. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685
- [2] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, & Sylvain Gelly. (2019). Parameter-Efficient Transfer Learning for NLP. arXiv:1902.00751
- [3] Tim Dettmers, Mike Lewis, Younes Belkada, & Luke Zettlemoyer. (2022). LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. arXiv:2208.07339