
ELECTRA — Efficiently Learning an Encoder that Classifies Token Replacements Accurately — là phương pháp pretrain mới được công bố bởi Google AI vượt trội hơn các kỹ thuật hiện tại với cùng nguồn lực tính toán.
Gần đây các tiến bộ của các mô hình pretrain đối với ngôn ngữ tự nhiên đã thay đổi tạo ra những đột phá đáng kể trong lĩnh vực này. Các mô hình hiện đại có thể kể đến như BERT, RoBERTa, XLNet, ALBERT, và T5, cũng như rất nhiều các biến thể khác. Các phương pháp này, dù khác biệt trong thiết kế nhưng sử dụng chung ý tưởng sử dụng một lượng lớn các dữ liệu không nhãn để tạo ra một mô hình ngôn ngữ tổng quát trước khi tinh chỉnh cho một nhiệm vụ cụ thể như sentiment analysis hay question answering.
Các phương pháp pretrain hiện nay thường rơi vào một trong hai loại: Mô hình ngôn ngữ LM, như là GPT, xử lý đầu vào từ trái qua phải và dự đoán từ tiếp theo với ngữ cảnh đã cho, và mô hình ngôn ngữ mặt nạ (MLM), như BERT, RoBERTa, và ALBERT, sẽ dự đoán một số từ bị che đi (đeo mặt nạ) trong chuỗi đầu vào. MLM mang lại lợi thế trong việc sử dụng ngữ cảnh hai chiều thay vì chỉ đơn thuần từ trái qua phải. Mặc dù vậy, thay vì phải dự đoán tất cả các từ, các mô hình MLM chỉ cần dự đoán một tập nhỏ (khoảng 15% số token) do đó với mỗi một câu, lượng thông tin học được sẽ hạn chế hơn.

Trong bài báo mới đây của Google “ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators”, các tác giả sử dụng một cách tiếp cận sử dụng được lợi thế của BERT nhưng học hiệu quả hơn. ELECTRA — Efficiently Learning an Encoder that Classifies Token Replacements Accurately — là phương pháp pretrain mới vượt trội hơn các kỹ thuật hiện tại với cùng nguồn lực tính toán. Ví dụ, ELECTRA đạt kết quả của RoBERTa và XLNet trên bộ dữ liệu chuẩn GLUE dù sử dụng ít hơn 25% tài nguyên tính toán và đạt kết quả state-of-the-art trên bộ dữ liệu chuẩn SQuAD. Hiệu năng xuất sắc của ELECTRA cho thấy khả năng hoạt động tốt với kích thước nhỏ. Nó có thể được huấn luyện một vài ngày trên một GPU và hoạt động tốt hơn GPT, một mô hình sử dụng tài nguyên tính toán gấp 30 lần. ELECTRA đã được công bố như một mô hình mã nguồn mở trên TensorFlow.
Giúp cho quá trình pretrain nhanh hơn
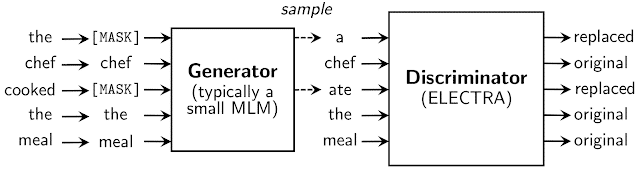
ELECTRA sử dụng một nhiệm vụ pretrain mới mang tên phát hiện token bị thay thế (RTD). Nhiệm vụ này kết hợp cả hai điểm mạnh của các mô hình LM và MLM. Lấy cảm hứng từ GAN, ELECTRA huấn luyện mô hình phân biệt giữa đầu vào “thật” và “giả”. Thay vì làm gián đoạn đầu vào với mặt nạ “[MASK]” như trong BERT, các tác giả thay thế một vài token thành các token sai nhưng có vẻ hợp lý. Ví dụ, từ “cooked” (nấu ăn) sẽ được thay thế bằng từ “ate” (ăn). Mặc dù nó cũng có ý nghĩa nhưng rõ ràng là không khớp trong ngữ cảnh này. Nhiệm vụ này yêu cầu mô hình phải xác định xem các token có bị thay thế hay không trên tất cả các token thay vì chỉ 15% như BERT.

Việc thay thế các token được thực hiện bởi một mạng nơ ron khác là generator. Các tác giả sử dụng một mô hình MLM nhỏ làm bộ sinh (như là BERT với một lượng nhỏ nơ ron lớp ẩn) được huấn luyện kết hợp với discriminator. Cả generator và discriminator sử dụng chung word embedding. Sau khi huấn luyện, generator được loại bỏ và ELECTRA chỉ bao gồm discriminator được finetune cho các nhiệm vụ cụ thể. Kiến trúc của mô hình là transformer.
Kết quả của ELECTRA
Các tác giả so sánh ELECTRA với các mô hình state-of-the-art khác trong NLP và thấy nó có sự cải thiện đáng kể.
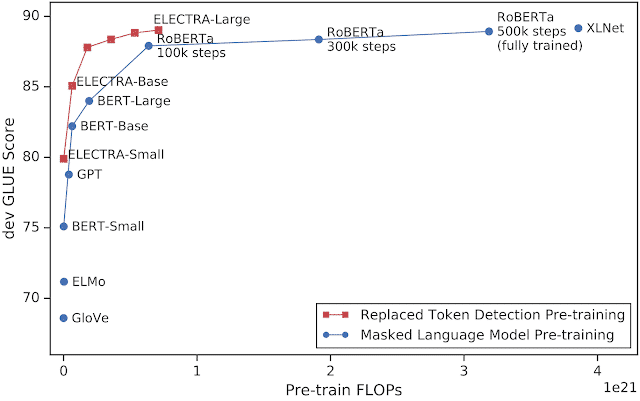
Kiểm chứng tính hiệu quả của mô hình, các tác giả huấn luyện mô hình ELECTRA thu nhỏ trên một GPU trong 4 ngày. Mặc dù không đạt được độ chính xác như mô hình yêu cầu nhiều TPU, ELECTRA-small vẫn hoạt động khác tốt, thậm chí tốt hơn GPT, một mô hình cần tài nguyên tính toán gấp 30 lần.
Cuối cùng, để thấy được ảnh hưởng của độ lớn mô hình, các tác giả huấn luyện ELECTRA với tài nguyên tương tự huấn luyện RoBERTa và bằng 10% của T5). Mô hình này đạt SOTA trên SQuAD 2.0, tốt hơn RoBERTa, XLNet, và ALBERT trên GLUE. Mặc dù T5-11b có kết quả cao hơn trên GLUE, ELECTRA nhỏ hơn 30 lần và chỉ cần 10% nguồn lực tính toán.
| Mô hình | Squad 2.0 test set |
| ELECTRA-Large | 88.7 |
| ALBERT-xxlarge | 88.1 |
| XLNet-Large | 87.9 |
| RoBERTa-Large | 86.8 |
| BERT-Large | 80.0 |
Công bố ELECTRA
Các tác giả đã công bố mã nguồn cho cả pretrain và finetune ELECTRA. Các nhiệm vụ hiện được hỗ trợ là phân loại văn bản, trả lời câu hỏi và gán nhãn chuỗi. Code hỗ trợ huấn luyện ELECTRA trên GPU. Các trọng số của ELECTRA-Large, ELECTRA-Base, và ELECTRA-Small cũng được công bố.
Nếu bạn thích bài viết này, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập website hoặc tham gia các cộng đồng của chúng tôi trên các mạng xã hội để có được những thông tin mới nhất về lĩnh vực.