Kết quả tìm kiếm cho: machine learning
ALBERT: Bé hạt tiêu của dòng họ Transformer

Trung tâm nghiên cứu của Google và Viện công nghệ Toyota đã cùng nhau xuất bản bài báo giới thiệu về một mô hình được coi là người kế vị của BERT, một mô hình hiệu quả hơn với số lượng tham số ít hơn nhiều. Mô hình này có tên là ALBERT (A Lite … Đọc tiếp
Hướng dẫn Fine-Tuning BERT với PyTorch
Bài viết này sẽ hướng dẫn bạn cách sử dụng BERT với thư viện PyTorch để fine-tuning (tinh chỉnh) mô hình một cách nhanh chóng và hiệu quả. Ngoài ra, bài viết sẽ chỉ cho bạn ứng dụng thực tế của transfer learning trong NLP để tạo ra các mô hình hiệu suất cao với … Đọc tiếp
Phần 2: Phân loại Naive Bayes (Coding)
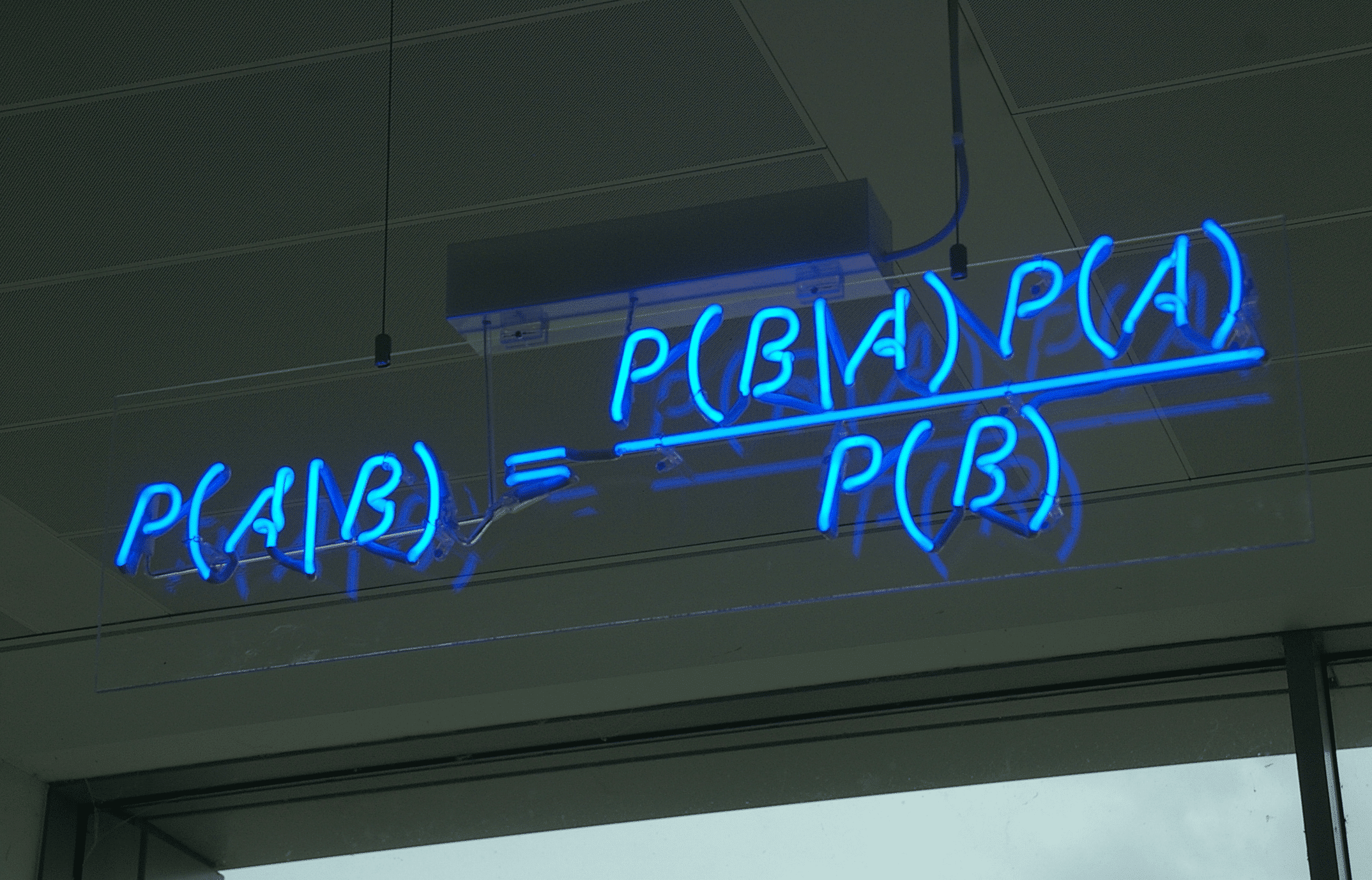
Trong phần trước, tôi đã giới thiệu các bạn lý thuyết và cách hoạt động của phân loại Naive Bayes. Trong phần này, tôi sẽ giới thiệu các bạn về code phân loại Naive Bayes với thư viện Sklearn – một thư viện mạnh về các thuật toán trên Python. Ví dụ Trong bài … Đọc tiếp
Sự thú vị của NLP – Phần 3

Qua phần 1 ta đã biết xử lý ngôn ngữ tự nhiên có thể hiểu đơn giản là ngôn ngữ của con người. Máy tính được lập trình để xử lý tốt đối với dữ liệu có cấu trúc như các bảng số hay database. Nhưng ngôn ngữ của con người lại được thể hiện … Đọc tiếp
Hướng dẫn sử dụng GloVe
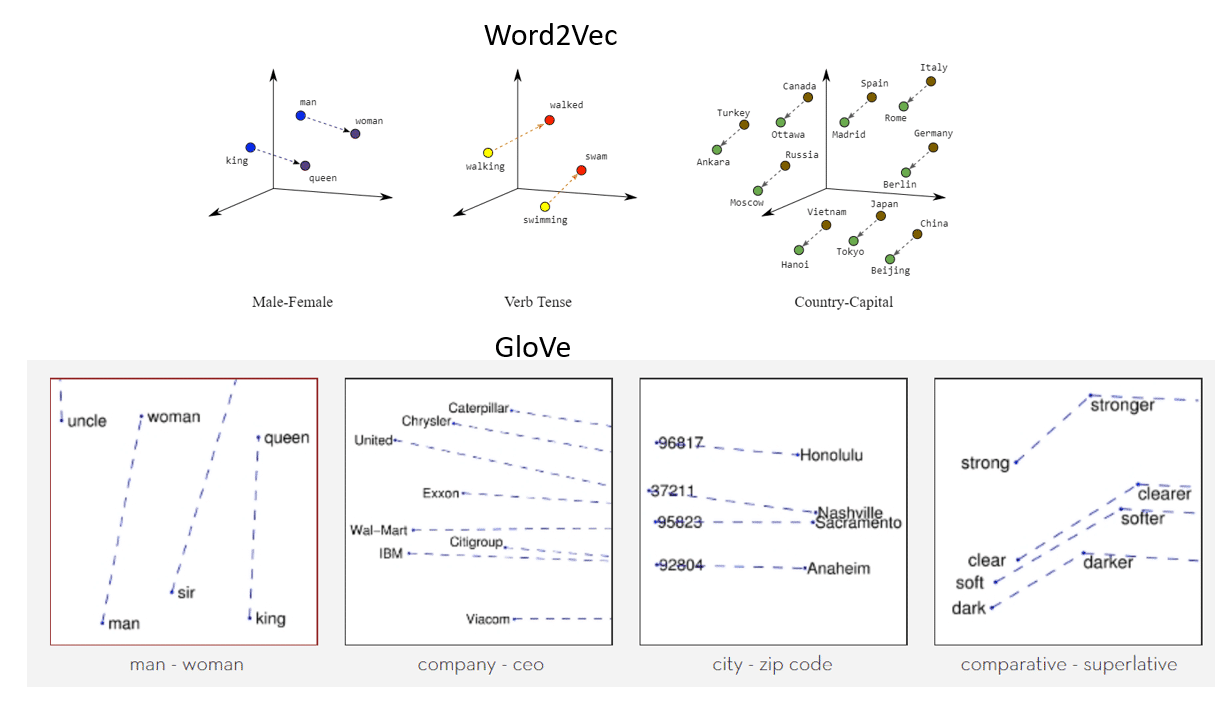
Chúng tôi đã có nhiều bài viết về Word Embedding hay các phương pháp Véc tơ hóa văn bản (các bạn có thể xem tại đây). Bài viết này sẽ hướng dẫn cách nạp các véc tơ đã được huấn luyện của GloVe để có thể sử dụng trong các mô hình học máy. GloVe … Đọc tiếp
Sự thú vị của NLP – Phần 2

Các bước xử lý NLP bao gồm những gì? Trong phần 1, chúng ta đã có những hiểu biết cơ bản về NLP. Trong bài này, hãy cùng tìm hiểu các bước xử lý bài toán xử lý ngôn ngữ tự nhiên. Chúng ta hãy xem xét một ví dụ về đoạn text trên Wikipedia … Đọc tiếp
Word Embedding – Vector hóa văn bản
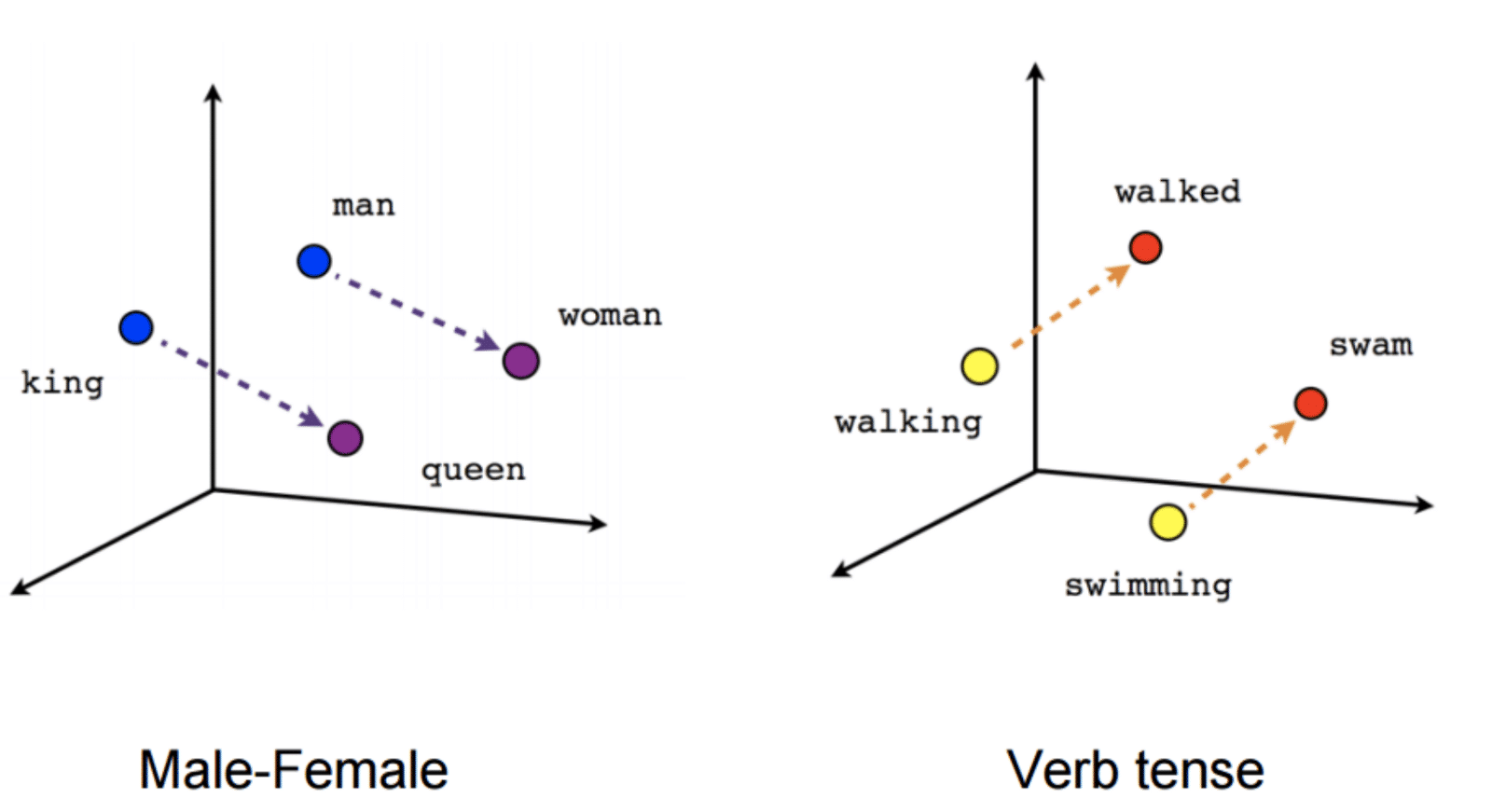
Word Embedding là một bước quan trọng trong bài toán Text Mining bất kì. Trong bài này, tôi sẽ đưa ra lần lượt theo sự phát triển và cải tiến của các thuật toán Word Embeddings phổ biến hiện nay.
Topic Modeling với Scikit Learn (Phần 2)
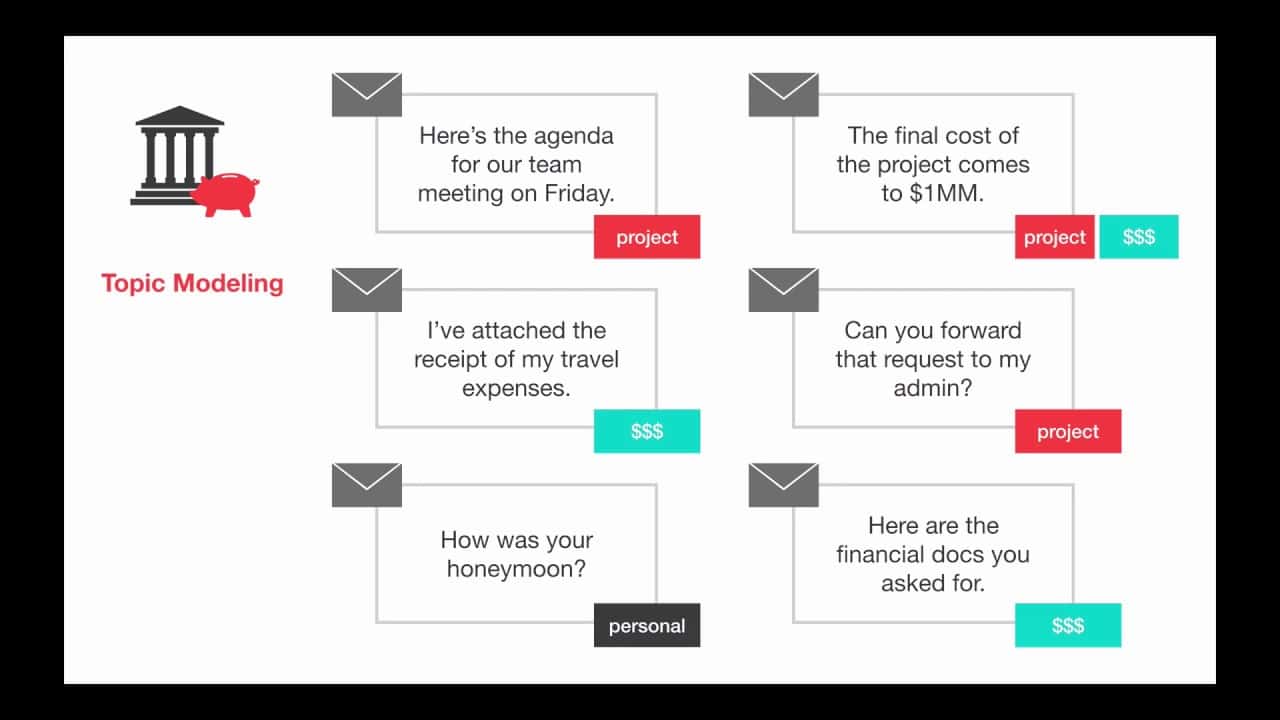
Ở bài trước, ta thấy cả 2 thuật toán Topic Modeling đều đưa ra kết quả có những dữ liệu nhiễu hay những chủ đề khó có thể tìm được tên. Vậy ta sẽ thực hiện cải thiện mô hình. Ý tưởng của phần này, chúng ta sẽ xem xét kĩ lại hai ma trận … Đọc tiếp
Cách làm dự án học máy của bạn bung bét (Phần 2)

Trong bài trước, chúng tôi đã hướng dẫn các bạn những cách cơ bản để làm một dự án học máy bung bét. Nếu các bạn vẫn hứng thú với chủ đề này, mời các bạn tiếp tục đọc phần 2 của bài viết. Chúng ta tiếp tục với cách thứ 5: 5. Cộng tác … Đọc tiếp