
Trung tâm nghiên cứu của Google và Viện công nghệ Toyota đã cùng nhau xuất bản bài báo giới thiệu về một mô hình được coi là người kế vị của BERT, một mô hình hiệu quả hơn với số lượng tham số ít hơn nhiều. Mô hình này có tên là ALBERT (A Lite BERT).
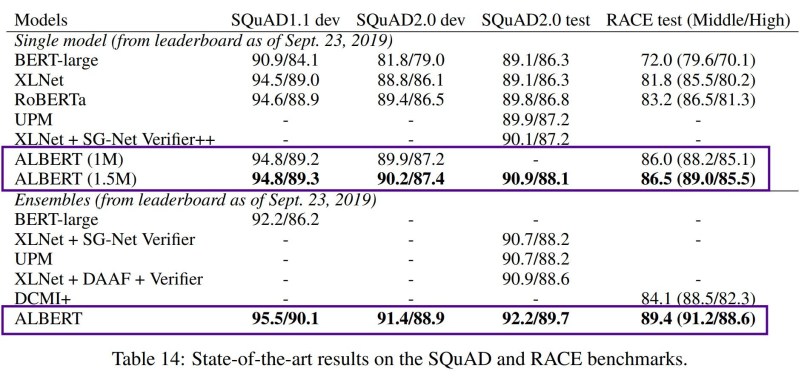
ALBERT cho những kết quả ấn tượng với các bộ dữ liệu chuẩn như GLUE, RACE, SQuAD. Nhưng điều khiến chúng ta thật sự sửng sốt là sự nhỏ gọn về mặt tham số của ALBERT so với tiền bối của nó. Kết quả này đến từ những nâng cấp trong kiến trúc và cách huấn luyện mô hình. Nhìn vào bảng dưới ta có thể thấy các phiên bản của ALBERT đều nhỏ gọn hơn BERT. Phiên bản xlarge của ALBERT chỉ xấp xỉ một nửa số tham số của phiên bản base và nhỏ hơn 21.5 lần so với phiên bản xlarge của BERT, đây là một con số ấn tượng.
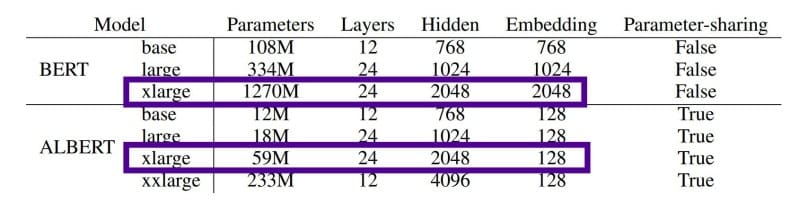
Trong NLP, mô hình lớn hơn chưa chắc đã tốt hơn
Trong những năm vừa qua, cùng với sự ra đời của các mô hình Transformer có kích thước ngày một lớn hơn, ta chứng kiến được sự cải thiện từng ngày về độ chính xác của các mô hình trong các bài toán NLP. Trong bài báo gốc của BERT, các tác giả chứng minh rằng với càng nhiều nơ ron, càng nhiều lớp ẩn, càng nhiều đầu attention thì kết quả càng tốt.
Chạy theo xu hướng đó, mô hình NLP lớn nhất cho đến nay là của NVIDIA với tên gọi Megatron, mô hình này chứa 8 tỷ tham số, gấp 24 lần BERT và 6 lần GPT-2. Mô hình này được huấn luyện trong 9 ngày với 512 GPU.
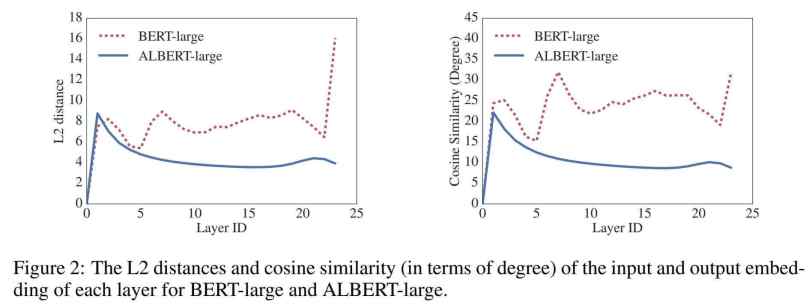
Hiện tượng bão hòa là hiện tượng phổ biến trong tự nhiên và nó cũng xảy ra với câu chuyện của chúng ta. Tác giả của ALBERT chỉ ra trong thực nghiệm của họ trên RACE, rằng phiên bản xlarge của BERT thực tế đã giảm hiệu quả đến 20% so với phiên bản large của mô hình này dù có số lượng tham số gấp 4 lần.

Điều này tương tự với hiệu quả của việc tăng độ sâu trong thị giác máy. Tăng cường độ sâu ban đầu có thể giúp tăng kết quả dự đoán nhưng nếu tiếp tục tăng, kết quả sẽ bắt đầu giảm. Ví dụ, một mạng ResNet với 1000 lớp không hiệu quả hơn một mạng ResNet với 152 lớp dù số lớp gấp đến 6.5 lần. Nói một cách khác, tại điểm bão hòa của dữ liệu, kết quả dự đoán sẽ không tăng dù cho năng lực của mạng được tăng cường.
Với quan sát đó, tác giả của ALBERT muốn tạo ra kết quả tốt hơn dựa trên kiến trúc của mô hình và phương pháp huấn luyện, hơn là chỉ tạo ra một phiên bản lớn hơn của BERT. Và bé hạt tiêu ALBERT của chúng ta ra đời như thế đó.
ALBERT là gì?
Kiến trúc lõi của ALBERT giống với BERT, đều sử dụng kiến trúc của encoder của transformer với hàm kích hoạt GELU. Trong bài báo, các tác giả cũng sử dụng vocabulary có kích thước 30K giống với BERT. So với BERT, ALBERT có 3 điểm khác biệt quan trọng (2 cải tiến trong kiến trúc và 1 cải tiến trong phương pháp huấn luyện):
Hai cải tiến trong kiến trúc
Embedding có trọng số
Các tác giả của ALBERT chỉ ra rằng, đối với BERT, XLNet và RoBERTa, kích thước của WordPiece Embedding (E) bị ràng buộc với kích thước lớp ẩn (H). Mặc dù vậy, theo họ, embedding của đầu vào được thiết kế để học các biểu diễn không phụ thuộc vào ngữ cảnh trong khi đó các lớp ẩn có nhiệm vụ học các biểu diễn phụ thuộc vào ngữ cảnh.
Sức mạnh của BERT phần lớn nằm ở khả năng học các biểu diễn phụ thuộc ngữ cảnh bởi lớp ẩn. Nếu H và E bị ràng buộc với nhau, với một bài toán yêu cầu vocabulary (V) lớn, kích thước lớp ẩn cũng vì thế mà tăng lên. Kết quả là ta sẽ có một mô hình có hàng tỷ tham số mà phần lớn trong số đó hiếm khi được cập nhật trong quá trình huấn luyện. Do đó, ràng buộc hai thành phần có các mục đích khác nhau làm giảm hiệu quả của các tham số.
Cải thiện điều này, ALBERT thực hiện embedding với hai ma trận con. Thay vì ánh xạ các véc tơ embedding trực tiếp đến các lớp ẩn (tức là E = H). Thì chúng được ánh xạ đến một ma trận ít chiều hơn, sau đó mới ánh xạ ma trận này tới các lớp ẩn. Như vậy, số tham số được giảm từ O(V*H) xuống còn O(V*E+E*H).
Chia sẻ tham số giữa các lớp
Cải tiến thứ hai của ALBERT là phương thức chia sẻ các tham số giữa tất cả các lớp. Cụ thể, các tham số được dùng chung là các tham truyền thẳng và tham số attention. Các tác giả cho rằng việc dùng chung các tham số như vậy giúp thông tin lưu chuyển giữa các lớp thông suốt hơn và giúp mạng trở nên ổn định hơn.
Thay đổi cách huấn luyện – SOP (Sentence Order Prediction)
Hai cơ chế trong cách huấn luyện của BERT giúp mô hình này tạo ra sự khác biệt là MLM và NSP. ALBERT kế thừa MLM của BERT nhưng thay thế NSP với một cơ chế khác mang tên SOP (Sentence Order Prediction – Dự đoán thứ tự câu)
Tại sao không sử dụng NSP? Có một điểm cần chú ý rằng, các tác giả của RoBERTa chỉ ra rằng việc không sử dụng NSP trong huấn luyện cũng không làm giảm hiệu quả mô hình. Các tác giả của ALBERT đã lập luận để chứng minh tại sao NSP không hiệu và phát triển SOP.
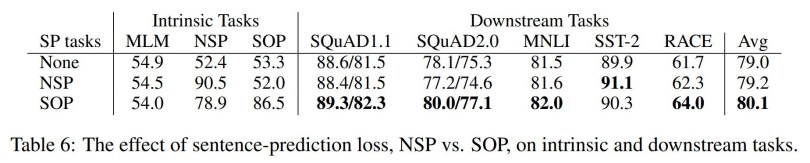
Các tác giả của ALBERT lập luận rằng NSP đã vô tình kết hợp năng lực dự đoán chủ đề và năng lực đánh giá tính mạch lạc của mô hình. Cụ thể, NSP cố gắng phát hiện hai câu liền nhau trong cùng một tài liệu với các phản ví dụ là các cặp câu ở hai tài liệu khác nhau.
Trái lại, các tác giả của ALBERT cho rằng tính mạch lạc giữa các câu là quan trọng hơn việc phát hiện chủ đề và SOP được phát triển để giúp mô hình có năng lực dự đoán thứ tự các câu. Các cặp câu được lấy ra từ cùng một tài liệu và phản ví dụ là trường hợp các câu này được đổi chỗ cho nhau. Nhờ đó, mô hình sẽ không dựa vào thông tin chủ đề mà chỉ tập trung vào tính liên kết giữa hai câu để học ra thứ tự giữa chúng.
Một số phân tích
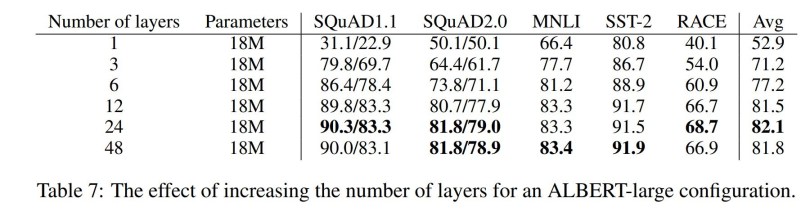
Như đã trình bày, khi đạt tới điểm bão hòa, tăng kích thước mô hình cũng không có ý nghĩa gì. Các tác giả ALBERT đã thực nghiệm và tìm ra điểm tối ưu của số lớp ẩn và kích thước lớp ẩn. Theo đó, 12 lớp là số lớp khuyến nghị cho ALBERT.

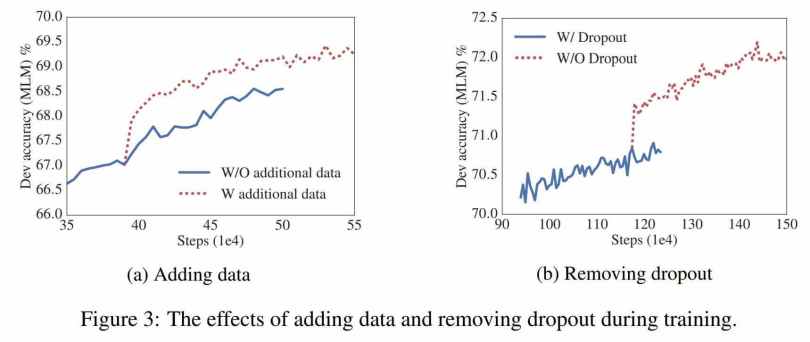
Ngoài ra, các tác giả cũng thực nghiệm để so sánh ALBERT trong trường hợp được bỏ dropout và trường hợp huấn luyện với dữ liệu bổ sung.
Với những thông tin từ bài viết này, có thể thấy ALBERT là một bước tiến lớn với những cải tiến hợp lý từ tiền bối của nó – BERT.
Nếu bạn thấy bài viết này hữu ích, đừng ngại chia sẻ nó với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io hoăc đăng ký (dưới chân trang) để nhận được thông tin về những xu hướng mới nhất của Trí tuệ nhân tạo trên thế giới.