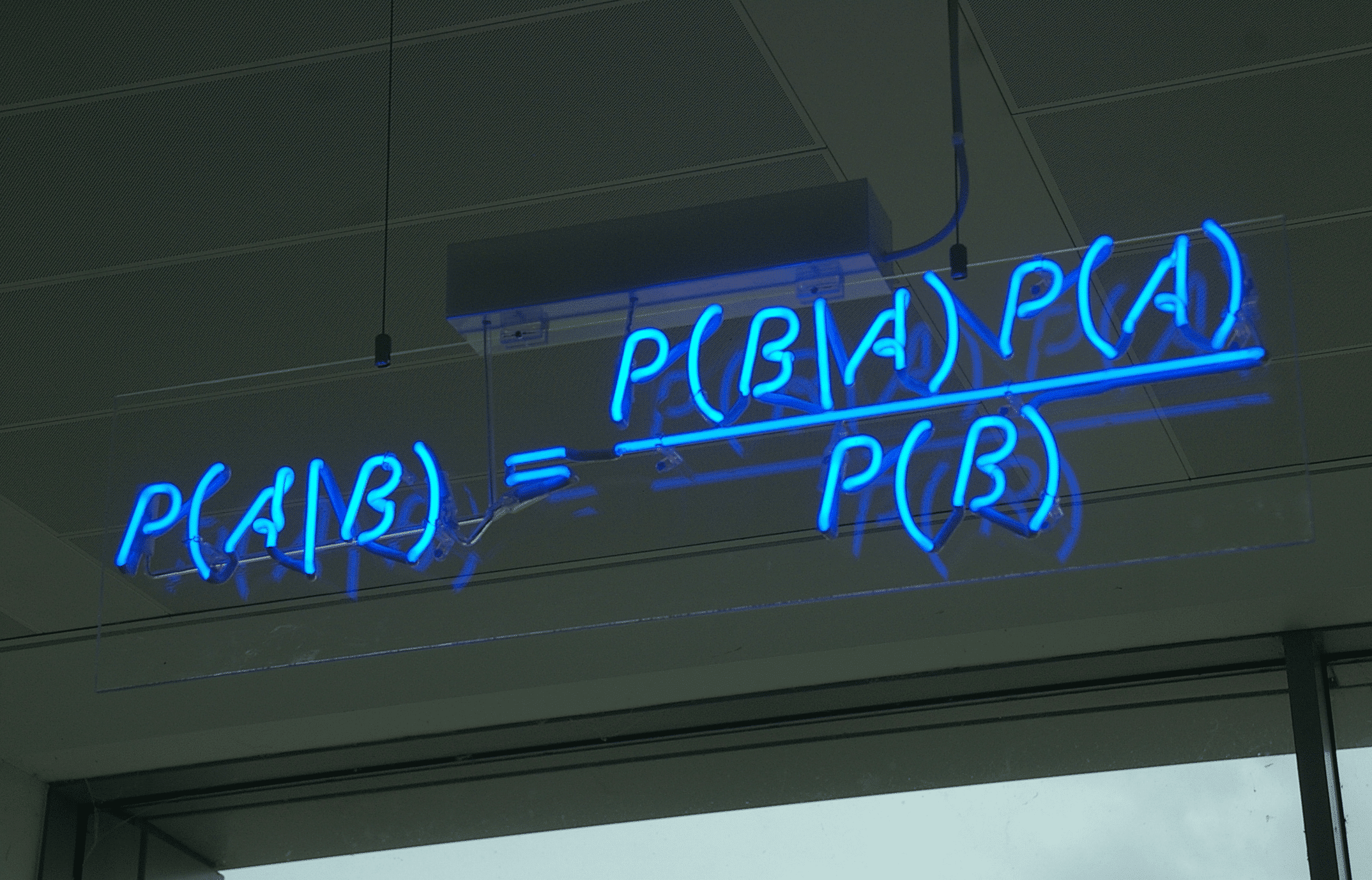

Trong phần trước, tôi đã giới thiệu các bạn lý thuyết và cách hoạt động của phân loại Naive Bayes.
Trong phần này, tôi sẽ giới thiệu các bạn về code phân loại Naive Bayes với thư viện Sklearn – một thư viện mạnh về các thuật toán trên Python.
Ví dụ
Trong bài này, chúng ta sẽ xây dựng mô hình train phân loại một email là Spam hay không Spam. Bộ dữ liệu gồm 702 email chia làm 02 lớp là Spam và không Spam. Tiếp đó, ta kiểm định mô hình với bộ dữ liệu gồm 260 cái email và dự đoán một email bất kì có phải là Spam hay không.
Các thư viện chuẩn bị
- Install Python.
- Install pip.
- Install sklearn trên python : pip install scikit-learn
- Install numpy: pip install numpy
- Install SciPy: pip install scipy
Dữ liệu
Bạn có thể download dữ liệu tại đây (phần chapter 1).
Khuyến nghị: bạn nên theo sát hướng dẫn và tự viết code. Trong trường hợp gặp lỗi, bạn có thể tham khảo tại đây.
Bước 1: Làm sạch và chuẩn bị dữ liệu
Chúng ta có 02 folder test-mails và train-mails. Dữ liệu sẽ có dạng như dưới đây:
Subject: re : 2 . 882 s - > np np > deat : sun , 15 dec 91 2 : 25 : 2 est > : michael < mmorse @ vm1 . yorku . ca > > subject : re : 2 . 864 query > > wlodek zadrozny ask " anything interest " > construction " s > np np " . . . second , > much relate : consider construction form > discuss list late reduplication ? > logical sense " john mcnamara name " tautologous thus , > level , indistinguishable " , , here ? " . ' john mcnamara name ' tautologous support those logic-base semantics irrelevant natural language . sense tautologous ? supplies value attribute follow attribute value . fact value name-attribute relevant entity ' chaim shmendrik ' , ' john mcnamara name ' false . tautology , . ( reduplication , either . )
Dòng đầu tiên mô tả là “chủ đề” và từ dòng thứ 03 trở đi mô tả “nội dung”.
Trong trường hợp bạn muốn truy cập bất cứ train-mails hoặc test-mails, bạn sẽ thấy tên của file dưới hai dạng:
number-numbermsg[number].txt : example 3-1msg1.txt (this are non spam emails) OR spmsg[Number].txt : example spmsga162.txt (these files are of spam emails).
Bước đầu tiên sẽ là làm sạch và chuẩn bị dữ liệu cho mô hình. Trong bước làm sạch, chúng ta sẽ loại bỏ các từ hoặc kí hiệu không cần thiết khỏi văn bản.
Ta xét ví dụ:
“Hi, this is Alice. Hope you are doing well and enjoying your vacation.”
Ở đây, những từ như :”is, this, are,…” là những từ không thực sự có ý nghĩa phân tích. Những từ đó được gọi là stop words. Do đó, trong bộ dữ liệu này, chúng ta sẽ chỉ xét 3000 từ có tần suất xuất hiện lớn nhất.
Sau khi làm sạch mỗi email, ta sẽ xây dựng một ma trận biểu diễn tần suất xuất hiện của mỗi từ.
Ví dụ: với đoạn văn bản: “Hi, this is Alice. Happy Birthday Alice” , sau khi làm sạch, chúng ta sẽ có được như sau:
word : Hi this is Alice Happy Birthday frequency : 1 1 1 2 1 1
Chúng ta sẽ xây dựng ma trận tần suất này với mọi văn bản. Hàm extract_features sẽ giúp ta tìm ra những common words cho mỗi văn bản.
def make_Dictionary(root_dir):
all_words = []
emails = [os.path.join(root_dir,f) for f in os.listdir(root_dir)]
for mail in emails:
with open(mail) as m:
for line in m:
words = line.split()
all_words += words
dictionary = Counter(all_words)
# if you have python version 3.x use commented version.
# list_to_remove = list(dictionary)
list_to_remove = dictionary.keys()
for item in list_to_remove:
# remove if numerical.
if item.isalpha() == False:
del dictionary[item]
elif len(item) == 1:
del dictionary[item]
# consider only most 3000 common words in dictionary.
dictionary = dictionary.most_common(3000)
return dictionary
Hàm make_Dictionary giúp ta đọc tất cả các email và xây dựng một bộ từ điển của tất cả các email. Do đây là bộ dữ liệu tiếng anh nên bước tiếp theo, ta xóa đi một số từ đơn (có độ dài bằng 1)
Và cuối cùng, ta trích xuất ra 3000 từ phổ biến nhất.
Bước 2: Trích xuất các Feature và ma trận nhãn tương ứng
Tiếp theo, dựa theo bộ từ vựng chúng ta xây dựng được ở bước trên, chúng ta tạo dựng nhã và bảng ma trận tần suất xuất hiện các từ.
word : Hi this is Alice Happy Birthday frequency : 1 1 1 2 1 1 word : Hi this is Alice Happy Birthday frequency : 1 1 1 2 1 1
def extract_features(mail_dir):
files = [os.path.join(mail_dir,fi) for fi in os.listdir(mail_dir)]
features_matrix = np.zeros((len(files),3000))
train_labels = np.zeros(len(files))
count = 0;
docID = 0;
for fil in files:
with open(fil) as fi:
for i,line in enumerate(fi):
if i == 2:
words = line.split()
for word in words:
wordID = 0
for i,d in enumerate(dictionary):
if d[0] == word:
wordID = i
features_matrix[docID,wordID] = words.count(word)
train_labels[docID] = 0;
filepathTokens = fil.split('/')
lastToken = filepathTokens[len(filepathTokens) - 1]
if lastToken.startswith("spmsg"):
train_labels[docID] = 1;
count = count + 1
docID = docID + 1
return features_matrix, train_labels
Bước 3: Training mô hình và dự đoán với thư viện sklearn Naive Bayes
Tài liệu của sklearn Naive Bayes sẽ hướng dẫn bạn chi tiết về ý nghĩa các tham số mô hình.
Về cơ bản, sklearn Naive Bayes cung cấp ba lựa chọn tham số cho mô hình:
- Gaussian: được sử dụng để phân loại và giả định rằng, tất cả các thuộc tính đều tuân theo phân phối chuẩn.
- Multinomial: (Đa thức) Được sử dụng cho các biến số rời rạc. Ví dụ, ta cần phân loại một văn bản. Ở đây, ta có thể xem xét phép thử bernoulli và tính tổng số lần xuất hiện của từ trong văn bản đang được xem xét.
- Bernoulli: Mô hình phân lớp nhị phân là hữu ích nếu các vector đặc trưng cũng phân lớp nhị phân (tức là được đánh số 0 và 1). Phân loại văn bản sẽ được dựa trên một “bag of word”, trong đó, mỗi từ vựng sẽ được đánh số là 0 – với những từ không có trong văn bản đang xem xét và 1 – với những từ xuất hiện trong văn bản đang xem xét.
Với ví dụ này, chúng tôi sẽ sử dụng Gaussian.
TRAIN_DIR = "../train-mails" TEST_DIR = "../test-mails" dictionary = make_Dictionary(TRAIN_DIR) # using functions mentioned above. features_matrix, labels = extract_features(TRAIN_DIR) test_feature_matrix, test_labels = extract_features(TEST_DIR) from sklearn.naive_bayes import GaussianNB model = GaussianNB() #train model model.fit(features_matrix, labels) #predict predicted_labels = model.predict(test_feature_matrix)
Bước 4: Accuracy Score
Tiếp theo, ta sẽ so sánh độ chính xác của mô hình dự đoán. Accuracy Scorechỉ tỷ lệ phần trăm dự đoán đúng. Một lần nữa, sklearn cung cấp hàm gọn gàng cho việc tính toán độ chính xác này:
from sklearn.metrics import accuracy_score accuracy = accuracy_score(test_labels, predicted_labels)
Bước 5: Tổng hợp
Trên đây là toàn bộ quy trình thực hiện một bài toán dự đoán email Spam văn bản.
Dưới đây, ta sẽ tổng hợp xây dựng một bộ code hoàn chỉnh:
import os
import numpy as np
from collections import Counter
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
def make_Dictionary(root_dir):
all_words = []
emails = [os.path.join(root_dir,f) for f in os.listdir(root_dir)]
for mail in emails:
with open(mail) as m:
for line in m:
words = line.split()
all_words += words
dictionary = Counter(all_words)
list_to_remove = dictionary.keys()
for item in list_to_remove:
if item.isalpha() == False:
del dictionary[item]
elif len(item) == 1:
del dictionary[item]
dictionary = dictionary.most_common(3000)
return dictionary
def extract_features(mail_dir):
files = [os.path.join(mail_dir,fi) for fi in os.listdir(mail_dir)]
features_matrix = np.zeros((len(files),3000))
train_labels = np.zeros(len(files))
count = 0;
docID = 0;
for fil in files:
with open(fil) as fi:
for i,line in enumerate(fi):
if i == 2:
words = line.split()
for word in words:
wordID = 0
for i,d in enumerate(dictionary):
if d[0] == word:
wordID = i
features_matrix[docID,wordID] = words.count(word)
train_labels[docID] = 0;
filepathTokens = fil.split('/')
lastToken = filepathTokens[len(filepathTokens) - 1]
if lastToken.startswith("spmsg"):
train_labels[docID] = 1;
count = count + 1
docID = docID + 1
return features_matrix, train_labels
TRAIN_DIR = "../train-mails"
TEST_DIR = "../test-mails"
dictionary = make_Dictionary(TRAIN_DIR)
print "reading and processing emails from file."
features_matrix, labels = extract_features(TRAIN_DIR)
test_feature_matrix, test_labels = extract_features(TEST_DIR)
model = GaussianNB()
print "Training model."
#train model
model.fit(features_matrix, labels)
predicted_labels = model.predict(test_feature_matrix)
print "FINISHED classifying. accuracy score : "
print accuracy_score(test_labels, predicted_labels)
Kết
Ngoài những hướng dẫn trên, bạn có thể thử một số trường hợp sau đây:
- Thử xây dựng mô hình với opption khác như Multinomial và Bernoulli, sau đó, so sánh độ chính xác giữa các mô hình
- Thử thay đổi độ lớn của bộ từ vựng với các trường hợp lớn hơn 3000 từ và nhỏ hơn 3000 từ.
Thuật toán Naive Bayes giả sử các thuộc tính đều là độc lập với nhau. Chẳng hạn, sự xuất hiện của một từ /thuộc tính là độc lập với từ khác. Nhưng trong thực tế có thể không như vậy (ví dụ trong tiếng anh từ “morning” thường đi sau từ “Good”). Tôi hy vọng phần 1 (lý thuyết và phần này) sẽ cung cấp một cái nhìn tổng quát về thuật toán Naive Bayes.
Hi vọng bài viết giúp ích cho bạn.
Hãy theo dõi https://trituenhantao.io/ để có thêm nhiều bài viết mới nhé.