
Transformer là một dòng mạng nơ ron nhân tạo đang ngày càng trở nên phổ biến. Trong bài này, hãy cùng trituenhantao.io tìm hiểu cách thức hoạt động của chúng. Transformer được sử dụng bởi GPT-2 của OpenAI hay trong AlphaStar của DeepMind — một chương trình có khả năng đánh bại những người chơi đỉnh cao của Starcraft.
Transformers được phát triển để giải bài toán chuyển đổi chuỗi hoặc dịch máy. Tức là nó có thể hoạt động với mọi bài toán chuyển một chuỗi đầu vào thành một chuỗi đầu ra. Các bài toán như nhận dạng giọng nói, chuyển văn bản thành giọng nói và nhiều ứng dụng khác của AI đều thuộc lớp bài toán này.

Để mô hình có thể thực hiện chuyển đổi chuỗi, nó cần có một dạng bộ nhớ nào đó. Ví dụ như mô hình cần dịch câu nói “Hồ Chí Minh là vị cha già kính yêu của dân tộc Việt Nam, những gì Người để lại sẽ mãi là tấm gương cho chúng con noi theo“. Để thu nhận và chuyển đổi được chuỗi văn bản này, nó cần biết được Người và Hồ Chí Minh có mỗi quan hệ đồng nhất với nhau.
Để có thể dịch được câu như vậy, mô hình cần tìm ra được mối liên hệ ràng buộc và phụ thuộc giữa các thực thể trong câu. Mạng nơ ron hồi quy (RNN) và mạng nơ ron tích chập (CNN) có những đặc điểm phù hợp để giải quyết vấn đề này. Trước khi tìm hiểu về Transformer, hãy cùng ôn lại một chút về hai kiến trúc này.
Recurrent Neural Networks
RNN chứa một vòng lặp thông tin trong kiến trúc của nó.
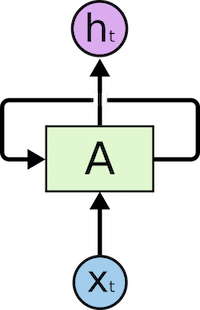
x_tTrong hình trên, chúng ta thấy một phần của mạng RNN, A, xử lý đầu vào x_t và cho đầu ra h_t. Vòng lặp cho phép thông tin lưu chuyển từ bước này đến bước sau.
Nếu gỡ vòng lặp này ra, ta có thể dễ dàng quan sát cách RNN xử lý thông tin. Một RNN có thể được coi như nhiều bản sao của cùng một mạng A. Mỗi mạng truyền một thông điệp đến mạng kế tiếp:
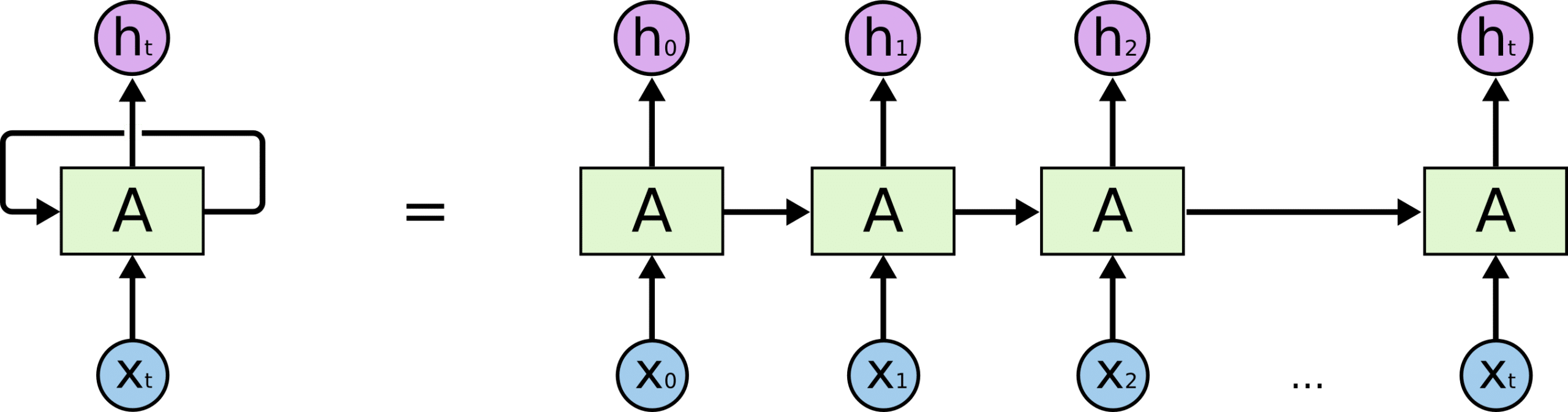
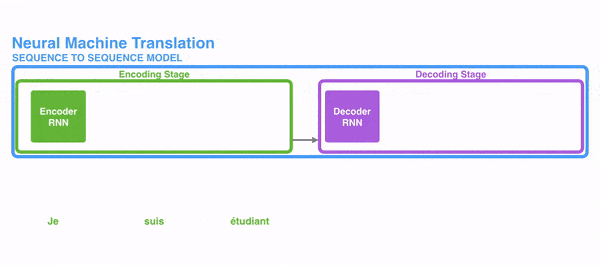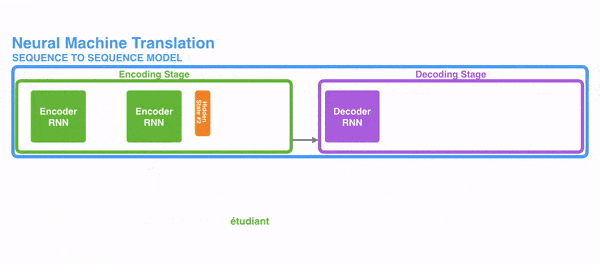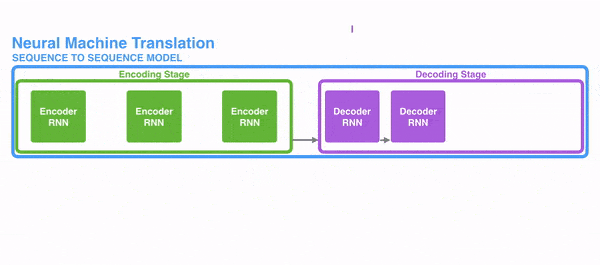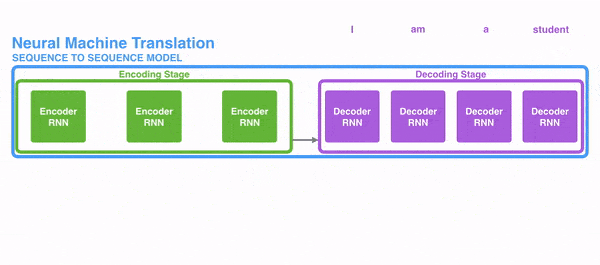
Tính chất này giúp cho RNN có thể xử lý các đầu vào liên quan đến chuỗi hoặc danh sách. Theo cách này, nếu ta muốn dịch một băn bản, đầu vào sẽ là các từ xuất hiện trong văn bản đó. Thông tin từ đầu chuỗi có thể được truyền và sử dụng khi xử lý các từ tiếp theo.
Hình dưới đây thể hiện cách RNN xử lý thông tin dạng chuỗi, các từ được xử lý riêng lẻ và câu kết quả được sinh ra bằng cách đưa trạng thái ẩn làm đầu vào cho decoder.
Long-Short Term Memory (LSTM)
Mặc dù RNN là một ý tưởng tuyệt vời trên lý thuyết nhưng trên thực tế, nó gặp vấn đề với các câu dài. Do phải lặp qua nhiều phần tử của chuỗi, kiến trúc này gặp phải hiện tượng mang tên vanishing gradient. Mạng không thể cập nhật các trọng số khi thông tin hiệu chỉnh không truyền được về những lớp đầu tiên. LSTM là bản cải tiến của RNN giải quyết vấn đề đó.
Trong cuộc sống hàng ngày, khi sắp xếp công việc, chúng ta thường ưu tiên những việc quan trọng. Các việc không phục vụ mục tiêu của chúng ta có thể bỏ qua được. Nhưng RNN không làm như vậy, toàn bộ câu đầu vào được xử lý, điều này khiến nó phải cáng đáng quá nhiều thông tin.
LSTM sử dụng một vài phép nhân chia trong kiến trúc của mình để giải quyết vấn đề này. Với LSTM, thông tin được truyền qua một cơ chế mang tên ô nhớ. Nó có thể lựa chọn các thông tin quan trọng và quên đi các thông tin khác.
Kiến trúc của LSTM trông như sau:
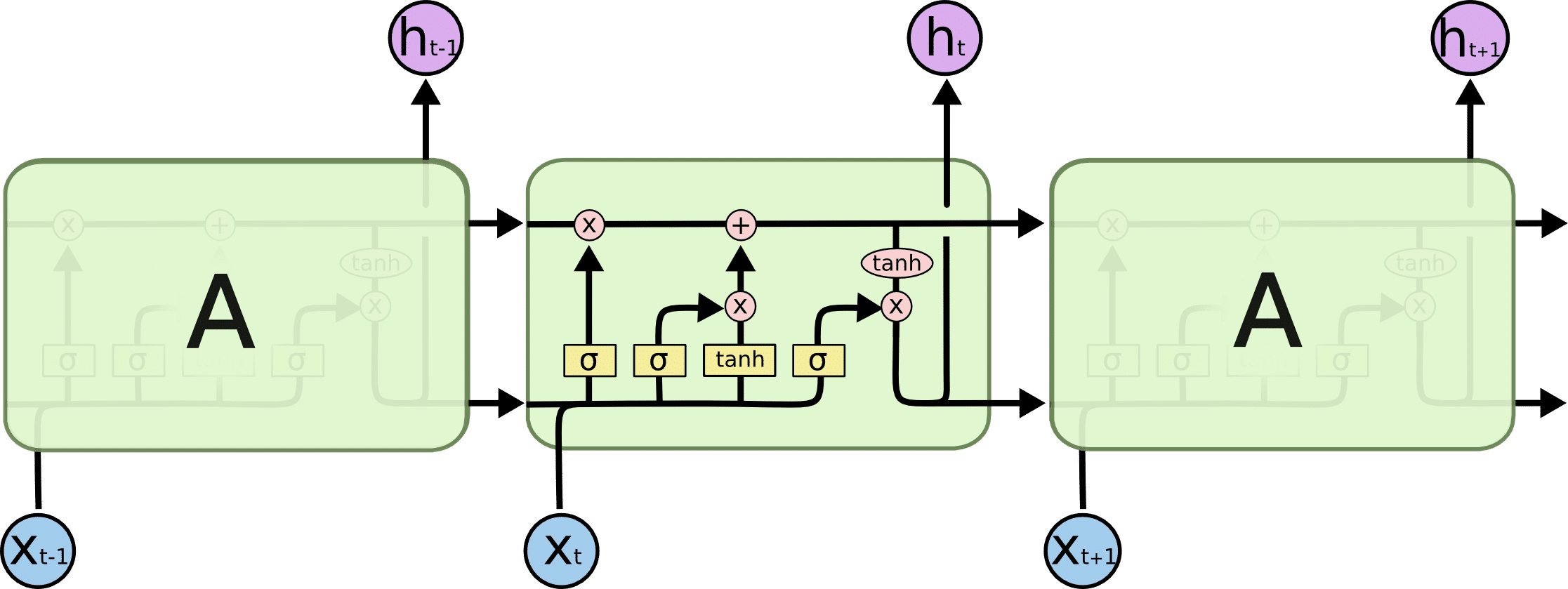
Dù LSTM là bước cải tiến lớn so với RNN, nhưng với những câu quá dài, nó vẫn phải dừng bước. Việc giữ được ngữ cảnh trong một từ nằm cách xa từ đang xử lý là một khó khăn lớn. Xác suất để hai từ có ràng buộc với nhau tỉ lệ nghịch với khoảng cách của chúng theo hàm mũ.
Một vấn đề nữa đối với RNN hay LSTM là chúng xử lý các từ một cách tuần tự. Đó là một rào cản nếu như muốn tính toán song song.
Attention
Để giải quyết vấn đề đó, các nhà nghiên cứu tạo ra một cơ chế giúp mô hình tập trung chú ý vào các từ cụ thể. Điều này khá phù hợp với cách làm việc của con người. Cơ chế này mang tên Attention.
Với RNN, thay vì mã hóa toàn bộ câu vào một trạng thái ẩn, mỗi từ có một trạng thái ẩn riêng. Sau khi mã hóa, tất cả chúng được truyền vào decoder. Hình dưới đây thể hiện chi tiết quá trình đó.
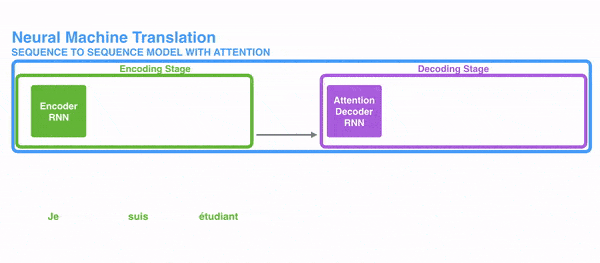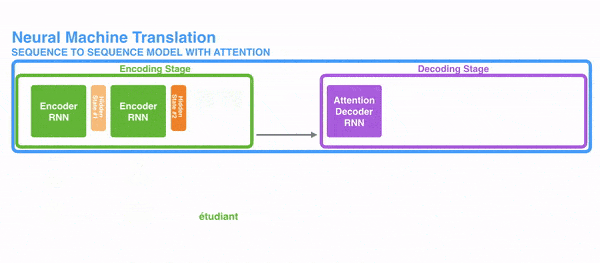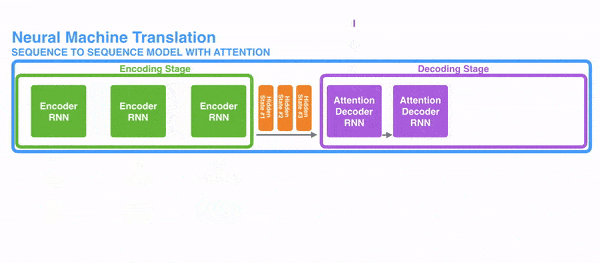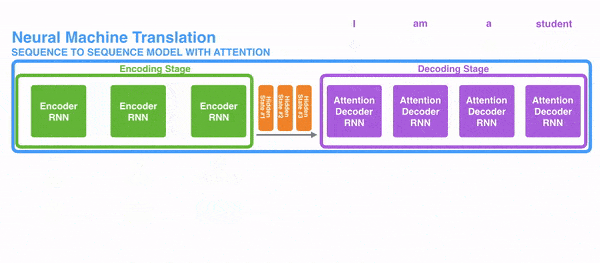
Ý tưởng đằng sau kỹ thuật này là thông tin liên quan có thể xuất hiện ở bất kỳ vị trí nào trong câu, không phụ thuộc vào khoảng cách. Do đó để giải mã một cách chính xác, nó cần tính đến tất cả các từ và sử dụng attention. Hình ở dưới thể hiện cách decoder tập trung vào các từ với các mức độ chú ý khác nhau.

Ví dụ khi dịch câu “Je suis étudiant” sang tiếng Anh, mô hình cần nhìn vào các từ khác nhau để dịch nó.
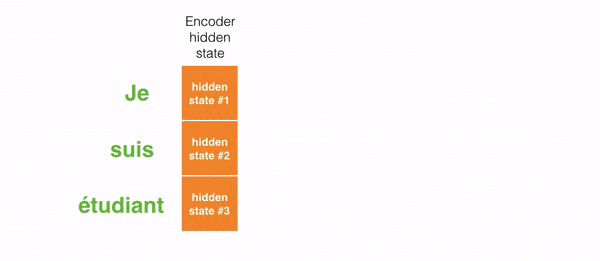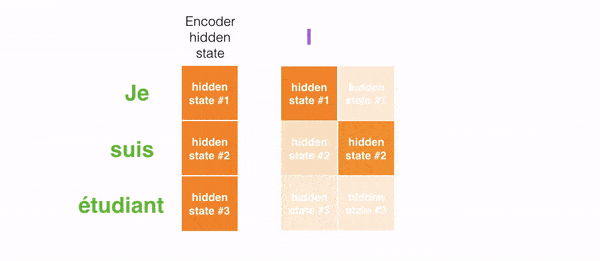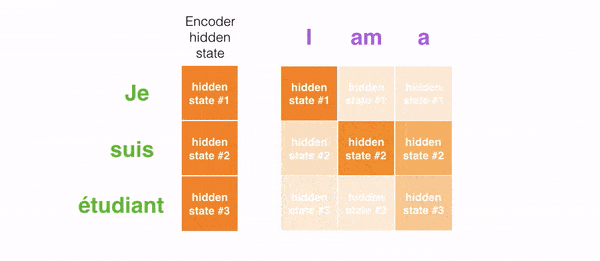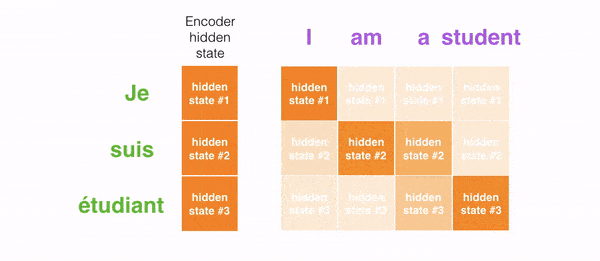
Hình phía dưới thể hiện mức độ chú ý của mô hình khi dịch “L’accord sur la zone économique européenne a été signé en août 1992.” từ tiếng Pháp sang tiếng Anh.
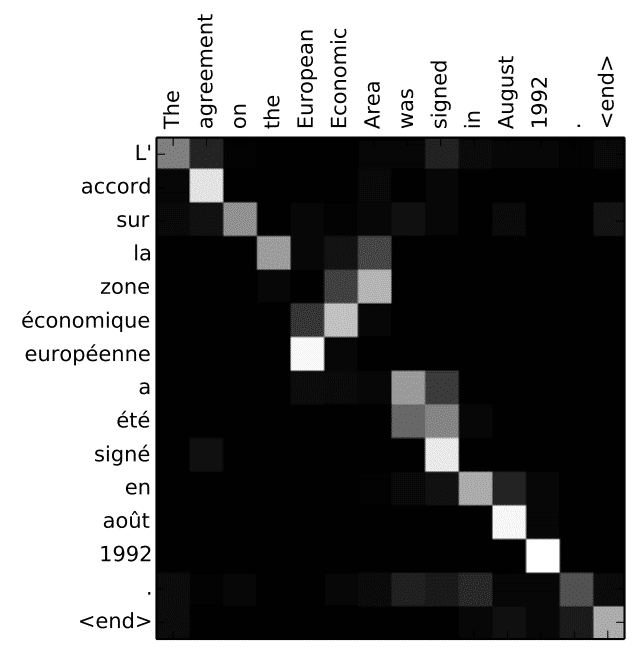
Mặc dù Attention đã giải quyết được vấn đề phụ thuộc giữa các từ trong RNN, nó vẫn chưa giúp tính toán song song. Đây là bất lợi đáng kể khi làm việc với các tập dữ liệu lớn.
Convolutional Neural Network
Mạng tích chập CNN là giải pháp cho tính toán song song. Một số mạng nổi tiếng trong biến đổi chuỗi sử dụng CNN có thể kể đến như Wavenet và Bytenet.
Lý do CNN có thể tính toán song song là các từ được xử lý cùng lúc và không cần chờ đợi nhau. Không chỉ có vậy, khoảng cách giữa một từ đầu ra với một từ đầu vào là log(N), thay vì N như trong RNN. Bạn có thể thấy rõ trong mô hình của Wavenet tại hình dưới đây.

Vấn đề của CNN là nó không giải quyết bài toán phụ thuộc trong câu. Đó là lý do Transformer được tạo ra, kiến trúc này kết hợp CNN với Attention.
Transformer
Như đã giới thiệu ở trên, Transformer kết hợp sức mạnh của CNN và Attention. Cụ thể hơn, kiến trúc này sử dụng self-attention. Trong kiến trúc của mình, Transformer chứa 6 encoder và 6 decoder.
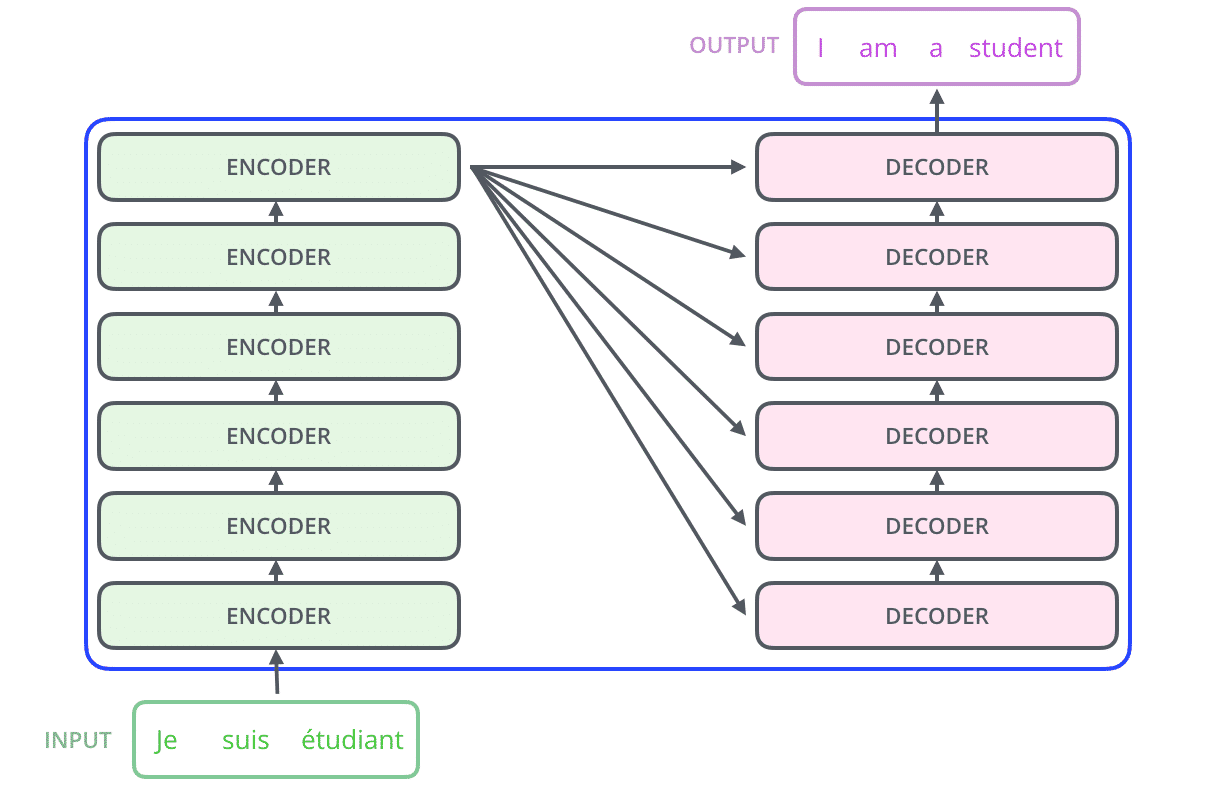
Các encoder đều rất giống nhau, có cùng kiến trúc. Mỗi encoder chứa hai lớp: Self-attention và mạng truyền thẳng (FNN).
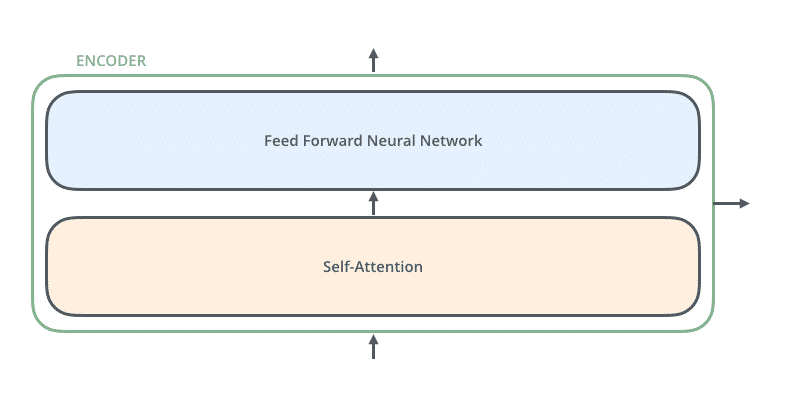
Self-attention giúp encoder nhìn vào các từ khác trong lúc mã hóa một từ cụ thể. Các decoder cũng có kiến trúc giống như vậy nhưng giữa chúng có một lớp attention để nó có thể tập trung vào các phần liên quan của đầu vào.
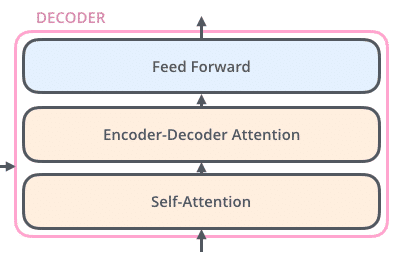
Self-Attention
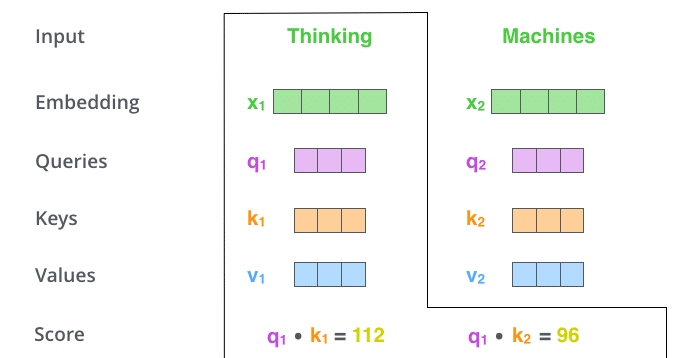
Bước đầu tiên để tính self-attention là tạo ra bộ 3 véctơ từ các véctơ đầu vào của encoder. Tại encoder đầu tiên, véctơ đầu vào là word embedding của từ. Như vậy với mỗi từ, ta sẽ có 3 véctơ Query, Key và Value. Các véctơ này được tạo nên bởi phép nhân ma trận giữa véctơ đầu vào và 3 ma trận trọng số chúng ta sử dụng trong quá trình huấn luyện. 3 véctơ này đóng vai trò khác nhau và đều quan trọng đối với attention.
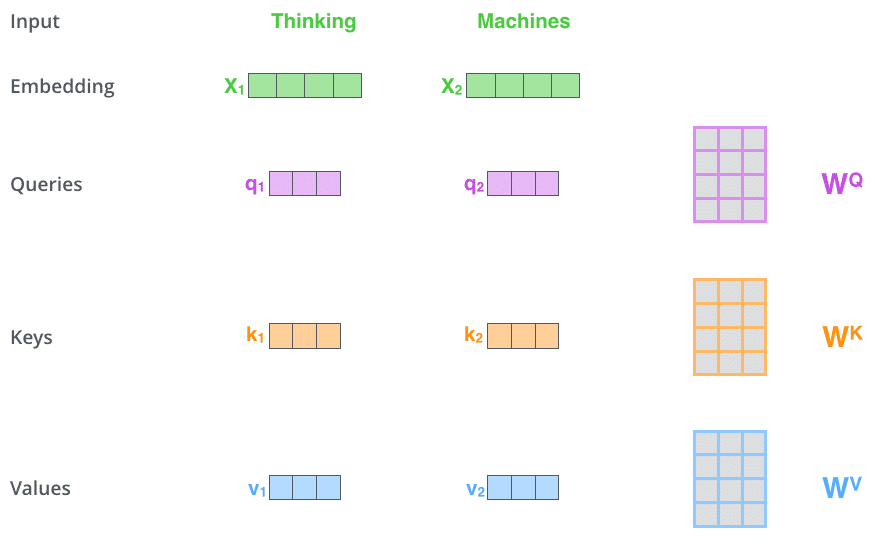
Bước thứ hai là tính điểm. Với mỗi từ, ta cần tính điểm của các từ khác trong câu đối với từ này. Giá trị này giúp quyết định từ nào cần chú ý và chú ý bao nhiêu khi mã hóa một từ.
Điểm được tính bằng tích vô hướng giữa véctơ Query của từ đang xét với lần lượt các véctơ Key của các từ trong câu. Ví dụ, khi ta tính self-attention trên từ có vị trí 1, điểm của nó với chính nó là q1.k1, điểm của nó với từ thứ hai là q1.k2, v..v..
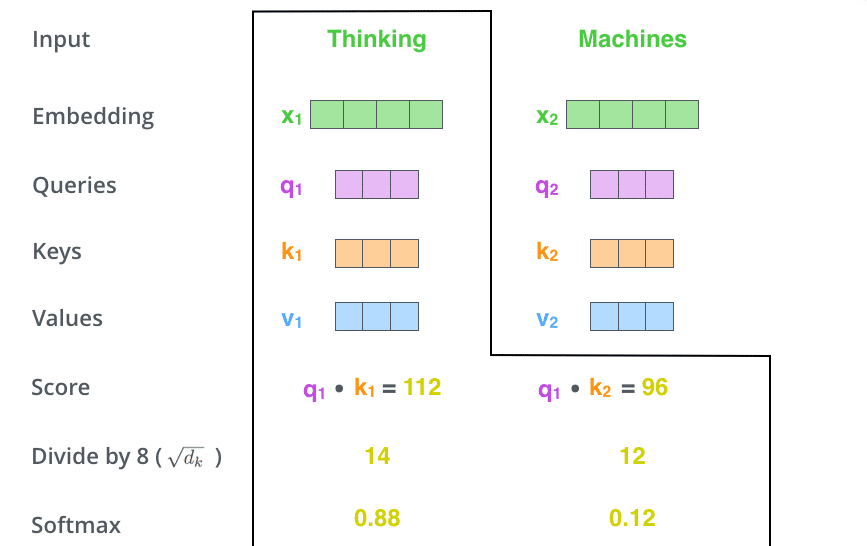
Bước tiếp theo là chuẩn hóa điểm. Trong bài báo gốc, điểm được chia cho 8 (căn bậc 2 của 64 – số chiều của véctơ Key). Điều này giúp cho độ dốc trở nên ổn định hơn. Tiếp theo, giá trị này được truyền qua hàm softmax để đảm bảo các giá trị điểm đều dương và có tổng không vượt quá 1.
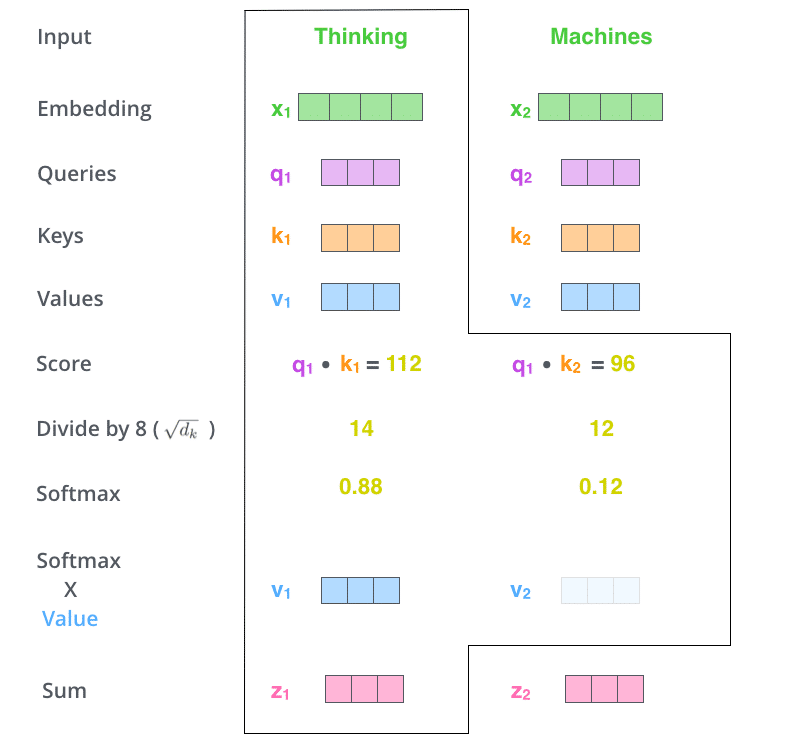
Bước tiếp theo là nhân véctơ Value với mỗi giá trị điểm đã tính phía trên rồi cộng lại với nhau. Ý đồ của việc này là bảo toàn giá trị véctơ của các từ cần được chú ý và loại bỏ véctơ của các từ không liên quan (bằng cách nhân nó với một số rất nhỏ, ví dụ như 0.001).
Multihead attention
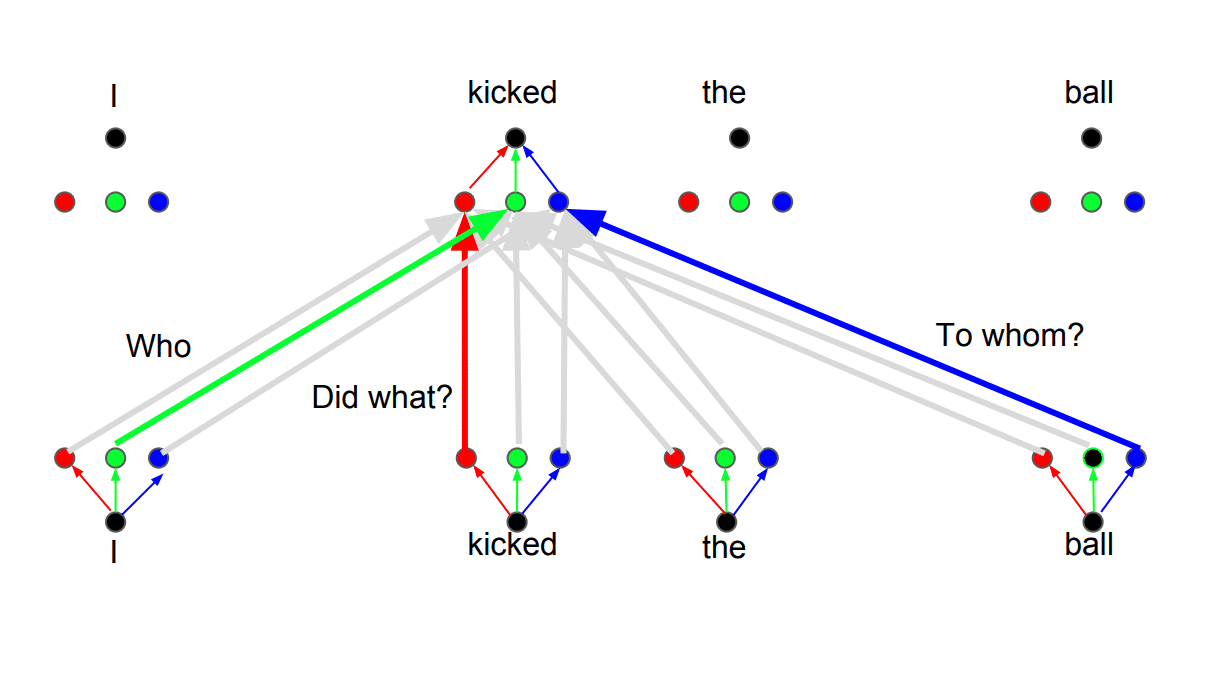
Đọc đến đây, bạn đã có được những thông tin cơ bản để hiểu cách hoạt động của Transformer. Trên thực tế, có một vài chi tiết nữa giúp cho kiến trúc này hoạt động hiệu quả hơn. Ví dụ như thay vì sử dụng một bộ giá trị self-attention, mô hình có thể sử dụng nhiều bộ QKV khác nhau. Kỹ thuật này mang tên Multihead attention.
Ý tưởng đằng sau kỹ thuật này là một từ có thể có nhiều nghĩa hoặc nhiều cách thể hiện khác nhau khi dịch ra một ngôn ngữ khác. Ngoài ra, mức độ liên hệ giữa các từ có thể thay đổi khi ta quan tâm đến các khía cạnh khác nhau của một câu nói.
Positional Encoding
Một chi tiết quan trọng khác của Transformer là mã hóa vị trí (positional encoding). Encoder của Transformer không có sự lặp lại tuần tự như RNN, chúng ta phải đưa thông tin về vị trí vào véctơ đầu vào. Các tác giả của Transformer thực hiện một mánh rất thông minh sử dụng sin và cos.
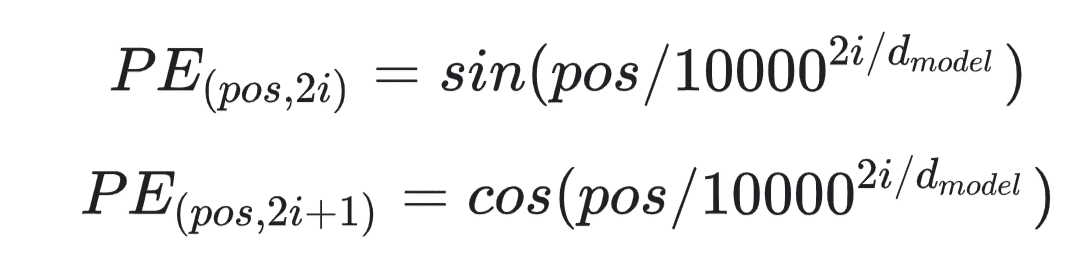
Chúng ta không đi sâu vào khía cạnh toán học của kỹ thuật này, nhưng về cơ bản, với các bước thời gian lẻ, ta dùng hàm cos, với bước thời gian chẵn, ta dùng hàm sin. Sau đó ta cộng các véctơ vào embedding của đầu vào. Việc này giúp mô hình nhận biết được vị trí của mỗi véctơ. Kết hợp của hàm sin và cos có những thuộc tính tuyến tính mà mô hình có thể dễ dàng học được.
Hi vọng thông qua bài viết này, các bạn đã có thêm kiến thức để hiểu được cách thức hoạt động của Transformer, dòng các mô hình đình đám nhất hiện nay. Ngoài ra, bạn có thể xem bài viết Minh họa Transformer để hình dung tốt hơn về kiến trúc này. Hãy chia sẻ bài viết với những người quan tâm và hãy thường xuyên truy cập trituenhantao.io hoặc đăng ký (dưới chân trang) để luôn nhận được các bài viết sớm nhất!