
WaveNet là một mô hình học sâu giúp sinh các dữ liệu âm thanh dạng sóng âm. Đó là lý do tại sao WaveNet có thể bắt chước được giọng của con người tự nhiên hơn các hệ Text-to-Speech tốt nhất hiện nay.
Bên cạnh đó, WaveNet còn có thể tổng hợp các tín hiệu âm thanh khác như âm nhạc.
Các nhà nghiên cứu thường ngại việc mô hình hóa âm thanh thô vì nó biến thiên quá nhanh: thường tối thiểu là 16.000 mẫu trong một giây. Ngoài ra mọi tín hiệu đều phụ thuộc lớn vào các tín hiệu trước đó. Đây là một thử thách không hề dễ dàng. Mặc dù vậy, lấy cảm hứng từ các thành tựu gần đây trong việc sử dụng các mạng học sâu để mô hình hóa các cấu trúc phức tạp như ảnh hay ngôn ngữ, các nhà khoa học tại Deep Mind tiến hành xây dựng WaveNet cho âm thanh thô.

Hình ảnh bên trên minh họa cấu trúc của WaveNet. Nó là một mạng CNN với các lớp tích chập cho phép xử lý các dữ liệu có số đầu vào biến thiên theo hàm mũ.
Trong quá trình huấn luyện, chuỗi đầu vào là âm thanh được ghi từ người thật. Tại mỗi bước thời gian, mô hình cập nhật trọng số dựa trên tín hiệu đầu vào. Tìn hiệu được xử lý được sử dụng để dự đoán các đầu ra tiếp theo. Vì đặc điểm của âm thanh thô, đây là một quá trình tốn nhiều tài nguyên tính toán. Nhưng với nguồn lực của mình, Deep Mind vẫn tiến hành xây dựng WaveNet vì tính cần thiết của nó.
Để đánh giá hiệu quả của mô hình, Deep Mind so sánh Wavenet với các hệ TTS của Google, đây là các hệ thống được cho là tốt nhất thế giới. Kết quả sử dụng thang đo MOS được thể hiện ở biểu đồ phía dưới.
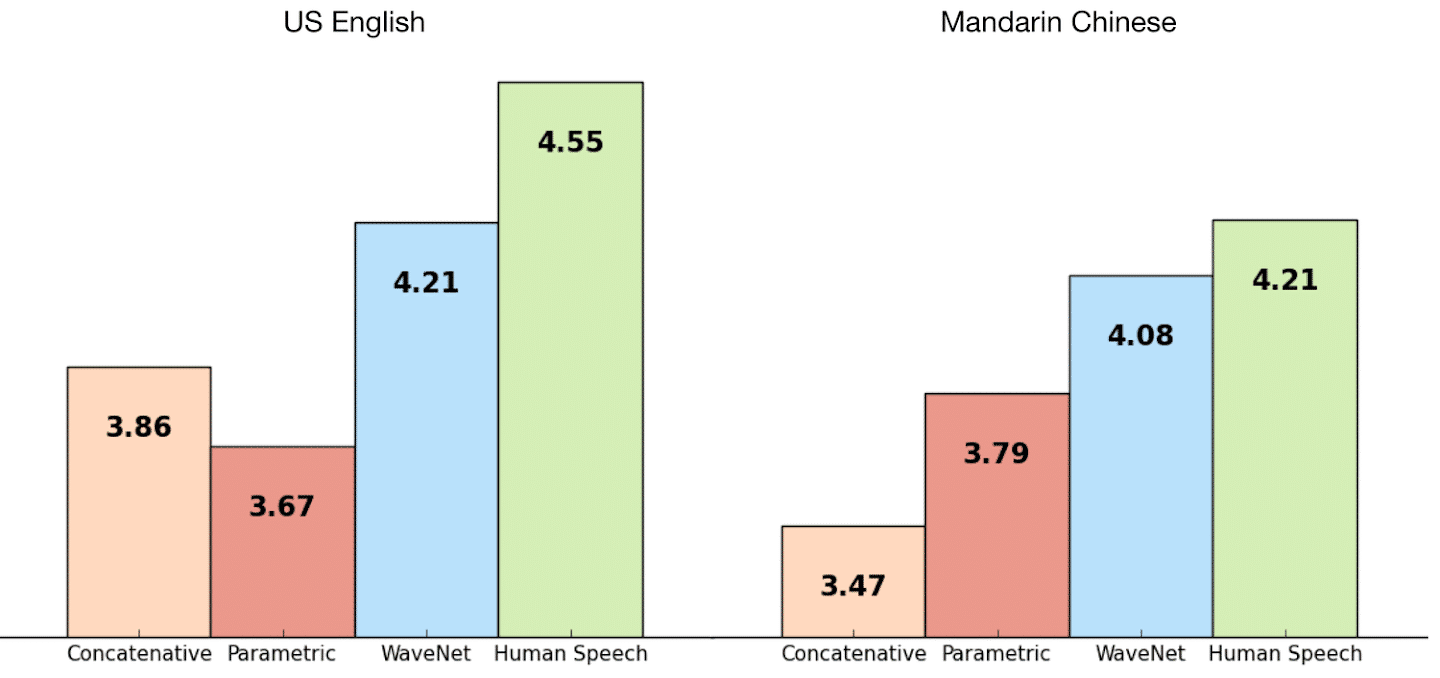
Dưới đây là một vài mẫu được sinh từ WaveNet để bạn có thể tự trải nghiệm và đánh giá
Parametric (Google TTS sử dụng LSTM-RNN)
Concatenative (Google TTS sử dụng HMM)
WaveNet
WaveNet hiểu mình nói gì
Để WaveNet có thể chuyển văn bản thành giọng nói, nó cần hiểu được nội dung của văn bản. Dữ liệu văn bản được chuyển thành các đặc trưng ngữ âm và nạp vào WaveNet. Đầu ra của mô hình này không chỉ ràng buộc bởi các mẫu âm thanh trước đó mà còn phụ thuộc vào nội dung của văn bản.
Nếu như không đưa vào thông tin văn bản, mô hình vẫn sinh được âm thanh nhưng nó phải tự bịa ra một số từ. Bạn có thể nghe âm thanh phía dưới, kết quả trở nên lủng củng với một số từ thật xen kẽ với các từ được mô hình bịa ra:
Một điểm thú vị nữa là các âm thanh ngoài lề như tiếng thở, cử động môi đôi khi cũng được WaveNet sinh ra. Điều này cho thấy tính mềm dẻo của mô hình âm thanh thô.
Ngoài ra, mô hình được huấn luyện từ nhiều giọng khác nhau, gồm cả đàn ông và phụ nữ. Điều này giúp cho mô hình có thể hoạt động tốt hơn. Mô hình có thể lựa chọn một trong số các cách phát âm tùy vào tham số được truyền vào. Bạn có thể trải nghiệm dưới đây:
Tương tự, các tham số như cảm xúc, giọng địa phương có thể truyền vào làm mô hình đa dạng và thú vị hơn.
WaveNet và Âm nhạc
Vì WaveNet có thể được đùng mô hình hóa mọi tín hiệu âm thanh, nó có thể sáng tạo âm nhạc. Trong thí nghiệm của mình, Deep Mind không đưa ra bất kỳ một ràng buộc nào và cho phép mô hình sinh bất kỳ tín hiệu gì nó muốn. Dưới đây là một số mẫu được mô hình sáng tạo khi học từ âm nhạc piano cổ điển.
WaveNet mở ra nhiều khả năng cho TTS, sáng tác nhạc và mô hình hóa âm thanh. Bạn có thể đọc bài báo gốc tại đây.
Nếu bạn thích chủ đề này, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io, tham gia các cộng đồng của chúng tôi trên các mạng xã hội hoặc đăng ký bản tin để có được những thông tin cập nhật nhất về Trí tuệ nhân tạo.