
Đây là bản dịch của bài viết The Illustrated Stable Diffusion của Jay Alammar, tác giả của Minh họa Transformer từng được trituenhantao.io giới thiệu trước đây. Bài viết được sửa đổi một phần không đáng kể phục vụ mục đích trình bày ý tưởng tốt hơn cho độc giả Việt Nam.
Ý tưởng về trí tuệ nhân tạo có thể vẽ tranh thổi bùng tâm trí của mọi người (bao gồm cả của tôi). Khả năng tạo ra những hình ảnh bắt mắt từ các mô tả văn bản đã đạt được chất lượng kỳ diệu và tạo nên sự thay đổi trong cách con người sáng tạo nghệ thuật. Sự ra mắt của Stable Diffusion là một cột mốc rõ ràng trong quá trình phát triển này vì nó cung cấp một mô hình hiệu suất cao cho đại chúng (hiệu suất xét về chất lượng hình ảnh, cũng như tốc độ và các yêu cầu về tài nguyên/bộ nhớ tương đối thấp).
Sau khi thử nghiệm với công nghệ này, bạn có thể bắt đầu tự hỏi nó hoạt động như thế nào.
Đây là một bài giới thiệu nhẹ nhàng về cách hoạt động của Stable Diffusion.

Stable Diffusion linh hoạt ở chỗ nó có thể được sử dụng theo một số cách khác nhau. Đầu tiên, hãy tập trung vào việc tạo hình ảnh chỉ từ văn bản (text2img). Hình ảnh trên minh họa một ví dụ nhập văn bản mẫu và hình ảnh được tạo ra. Ngoài văn bản thành hình ảnh, một cách sử dụng chính khác là thay đổi hình ảnh (với đầu vào là văn bản + hình ảnh).

Hãy bắt đầu tìm hiểu sâu hơn để giải thích các thành phần, cách chúng tương tác và ý nghĩa của các tùy chọn/tham số tạo hình ảnh.
Các thành phần của Stable Diffusion
Stable Diffusion là một hệ thống được tạo thành từ một số thành phần và mô hình. Nó không phải là một mô hình nguyên khối.
Khi tìm hiểu sâu bên trong, quan sát đầu tiên chúng ta có thể thực hiện là có một thành phần hiểu văn bản chuyển thông tin văn bản thành biểu diễn số để nắm bắt các ý tưởng trong văn bản.

Chúng ta bắt đầu với mức tổng quát và sẽ tìm hiểu chi tiết về machine learning ở phần sau của bài viết này. Tuy nhiên, chúng ta có thể nói rằng bộ mã hóa văn bản này là một mô hình ngôn ngữ Transformer đặc biệt (về mặt kỹ thuật: bộ mã hóa văn bản của mô hình CLIP). Nó lấy văn bản đầu vào và xuất ra một danh sách các số đại diện cho mỗi từ/token trong văn bản (một vectơ trên mỗi token).
Thông tin đó sau đó được chuyển cho Image Generator (tạm dịch: Bộ sinh ảnh), bao gồm một vài thành phần.

Bộ sinh ảnh trải qua hai giai đoạn:
1- Bộ tạo thông tin hình ảnh
Đây là vũ khí bí mật của Stable Diffusion. Là nguyên nhân mà hệ thống này có hiệu quả vượt trội so với các hệ thống trước đó.
Thành phần này chạy nhiều bước để tạo thông tin hình ảnh. Đây là tham số steps trong các thư viện và giao diện của Stable Diffusion và thường được đặt mặc định là 50 hoặc 100.
Thành phần này hoạt động hoàn toàn trong không gian của thông tin hình ảnh (là một latent space). Nó giúp cho hệ thống hoạt động nhanh hơn so với các mô hình diffusion trước đó, hoạt động trong không gian pixel. Về mặt kỹ thuật, thành phần này được tạo thành từ mạng UNet và thuật toán lập lịch.
Từ “diffusion” mô tả những gì diễn ra trong thành phần này. Nó từng bước xử lý thông tin và sinh ra ảnh chất lượng cao ở cuối quá trình thông qua image decoder (thành phần tiếp theo).
2- Image Decoder (Tạm dịch: Bộ giải mã hình ảnh)
Thành phần này vẽ ra hình ảnh từ thông tin có được từ bộ tạo thông tin hình ảnh. Nó chỉ chạy duy nhất một lần ở cuối quá trình để tạo ra ảnh trong không gian pixel.

Với hình ảnh trên ta thấy được 3 thành phần (mỗi thành phần là một mạng nơ ron) tạo nên Stable Diffusion:
- ClipText để mã hóa văn bản.
Input: văn bản.
Output: véc tơ embedding với 77 token, mỗi véc tơ 768 chiều. - UNet + Scheduler để dần dần xử lý/phân tán thông tin trong không gian ẩn.
Input: text embedding và một mảng đa chiều (danh sách số có cấu trúc, còn được gọi là tensor) được khởi tạo từ nhiễu.
Output: Một mảng thông tin đã qua xử lý - Autoencoder Decoder vẽ hình ảnh cuối cùng từ mảng thông tin đã qua xử lý ở bước trên.
Input: Mảng thông tin đã qua xử lý (Kích thước: (4,64,64))
Output: Hình ảnh cuối cùng (kích thước: (3, 512, 512) ứng với (RBG, chiều rộng, chiều cao))

Vậy thì Diffusion là gì?
Diffuision là quá trình diễn ra bên trong thành phần “tạo thông tin hình ảnh” màu hồng, có các embedding biểu diễn văn bản và một mảng thông tin hình ảnh được khởi tạo ngẫu nhiên, quá trình này tạo ra một mảng thông tin mà bộ giải mã hình ảnh sử dụng để vẽ hình ảnh cuối cùng.

Quá trình này diễn ra từng bước một. Mỗi bước lại bổ sung thêm thông tin liên quan. Để có thể hình dung về quy trình, chúng ta kiểm tra giá trị của mảng thông tin hình ảnh bằng cách chuyển nó qua bộ giải mã.
Nói cách khác, mỗi bước mô hình nhận một mảng đầu vào và tạo ra một mảng khác giống với văn bản đầu vào và các thông tin nó được huấn luyện hơn một chút.

Chúng ta có thể minh họa các mảng thông tin hình ảnh trong không gian latent.
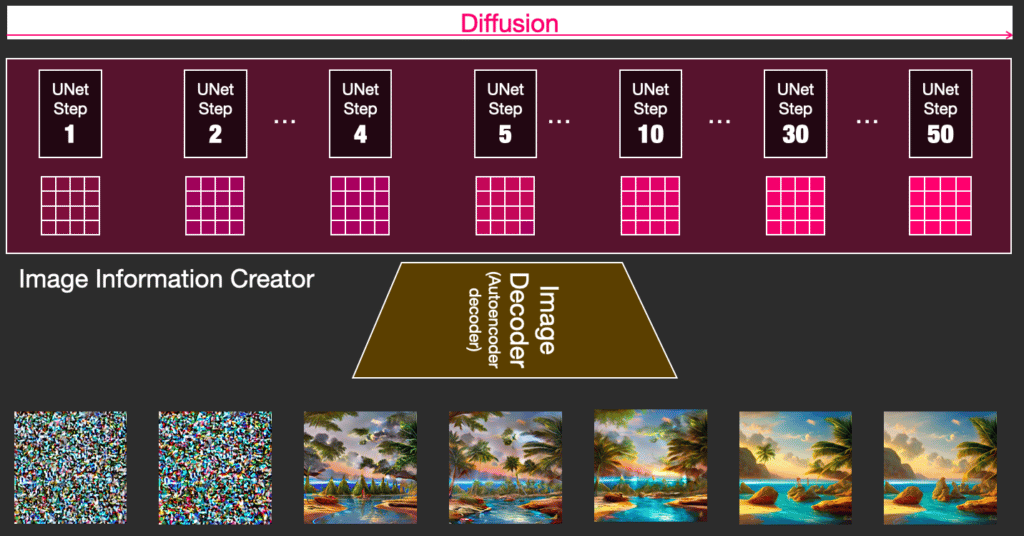
Diffusion hoạt động như thế nào?
Ý tưởng chính của việc tạo hình ảnh với các mô hình diffusion dựa trên thực tế là chúng ta có các mô hình thị giác máy tính mạnh mẽ. Với một tập dữ liệu đủ lớn, các mô hình này có thể học các phép biến đổi phức tạp. Các mô hình diffusion tiếp cận vấn đề bằng cách định hình bài toán như sau:
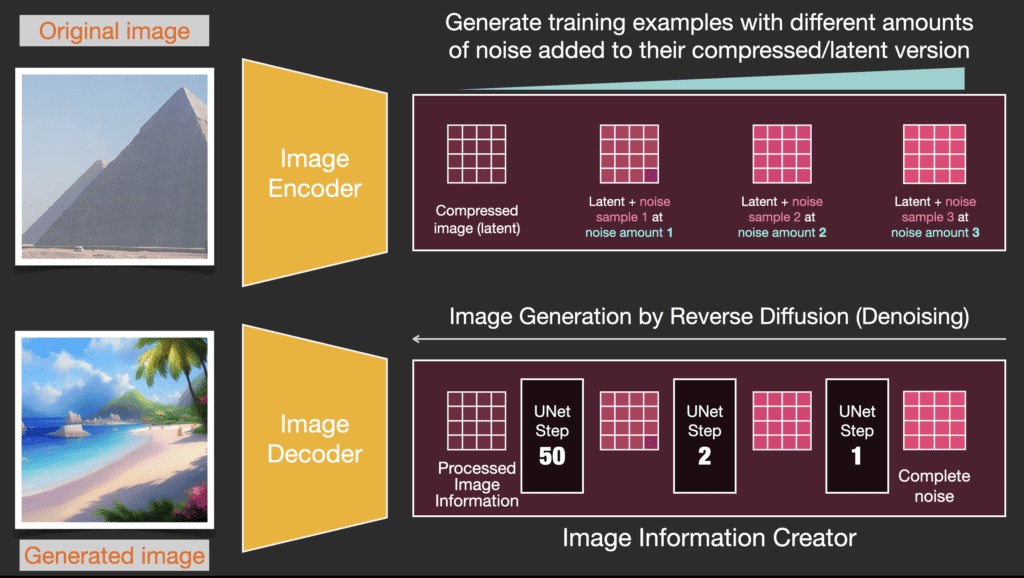
Giả sử chúng ta có một hình ảnh, chúng ta tạo ra nhiễu và thêm vào hình ảnh.

Chúng ta đã có một mẫu huấn luyện. Với cùng phương pháp, ta có thể tạo nhiều mẫu huấn luyện cho mô hình tạo ảnh của hệ thống.

Ví dụ này cho thấy một vài giá trị khác nhau về mức độ nhiễu trong hình ảnh (mức 0, không nhiễu) đến (mức 4, nhiễu cực đại), chúng ta có thể dễ dàng kiểm soát lượng nhiễu cần thêm vào ảnh và vì vậy chúng ta có thể trải rộng nó trên hàng chục bước, và tạo ra hàng chục mẫu đào tạo cho mỗi hình ảnh.
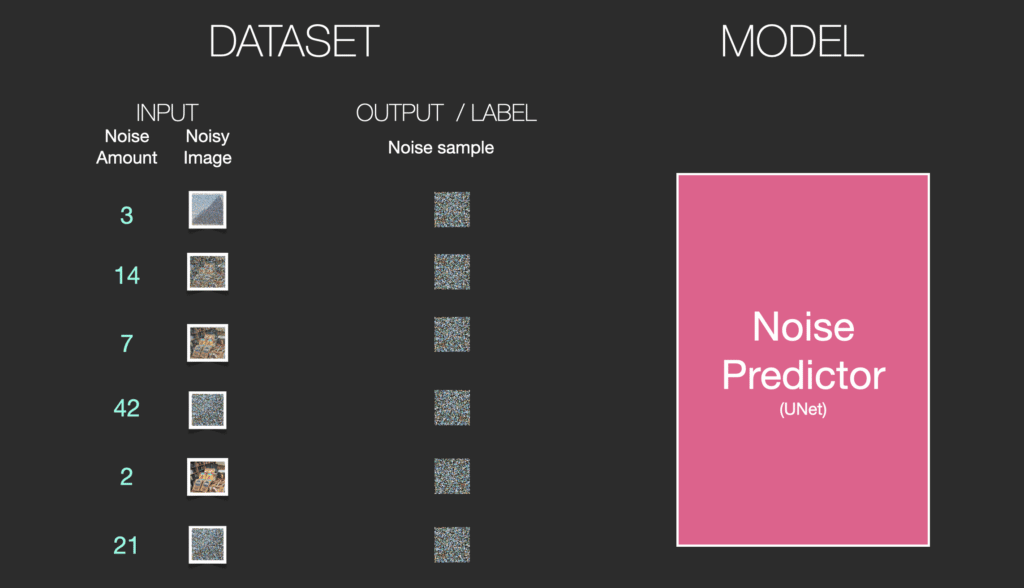
Với dataset này, chúng ta có thể huấn luyện một bộ dự đoán nhiễu và sử dụng nó để sinh ảnh với một cấu hình thích hợp. Một bước huấn luyện sẽ trông quen thuộc nếu bạn đã tiếp xúc với ML:
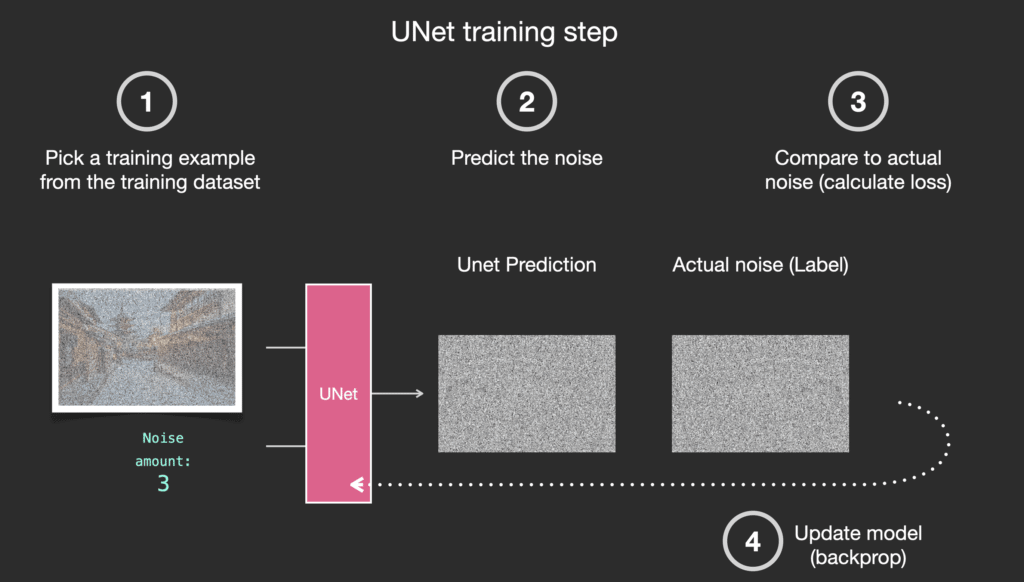
Sinh ảnh như thế nào?
Bộ dự đoán nhiễu được huấn luyện sẽ nhận vào một bức ảnh nhiễu và số lượng các bước khử nhiễu, nó sẽ trả về một lớp nhiễu.
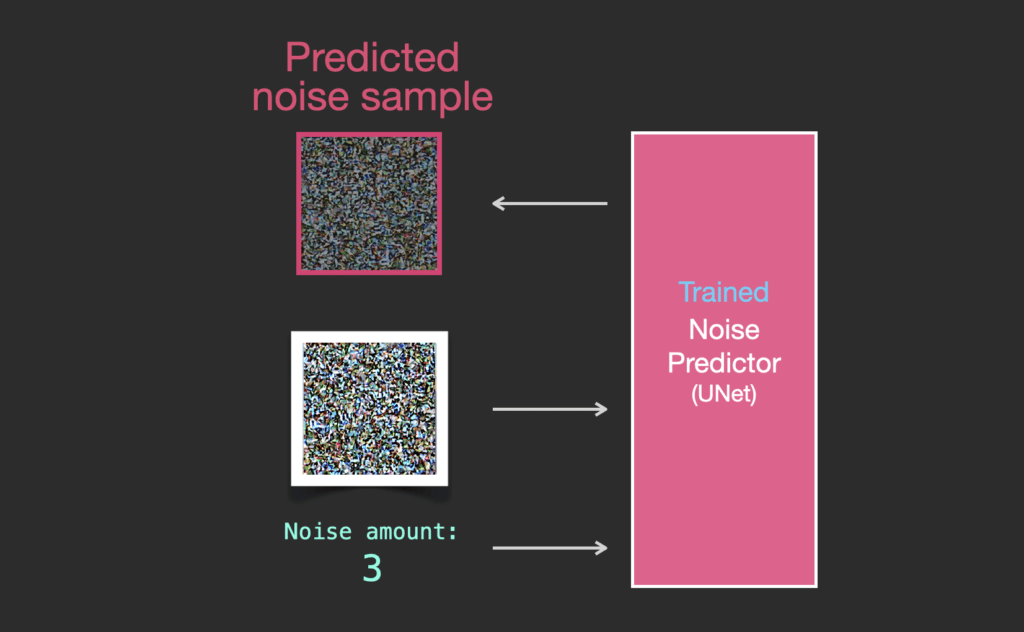
Thông tin nhiễu được dự đoán sao cho nếu chúng ta loại bỏ nó khỏi hình ảnh, chúng ta sẽ có được một hình ảnh gần giống với những hình ảnh mà mô hình đã được huấn luyện (không phải là các hình ảnh chính xác, mà là sự phân bố sắp xếp các điểm ảnh kiểu như bầu trời thì xanh dương và nằm phía trên mặt đất, người có hai mắt, mèo có tai nhọn và thờ ơ mọi thứ).
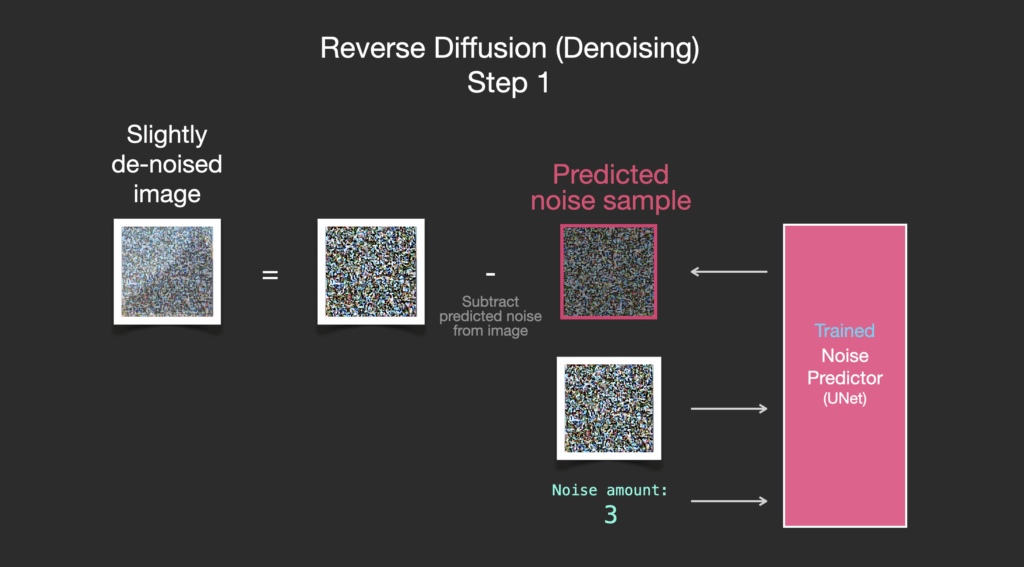
Nếu tập dữ liệu đào tạo là các hình ảnh có tính thẩm mỹ cao (ví dụ: LAION Aesthetics, mà Stable Diffusion được đào tạo trên đó), thì hình ảnh thu được sẽ có xu hướng đẹp về mặt thẩm mỹ. Nếu chúng ta đào tạo nó trên tập hình ảnh của logo, chúng ta có được một mô hình tạo logo.
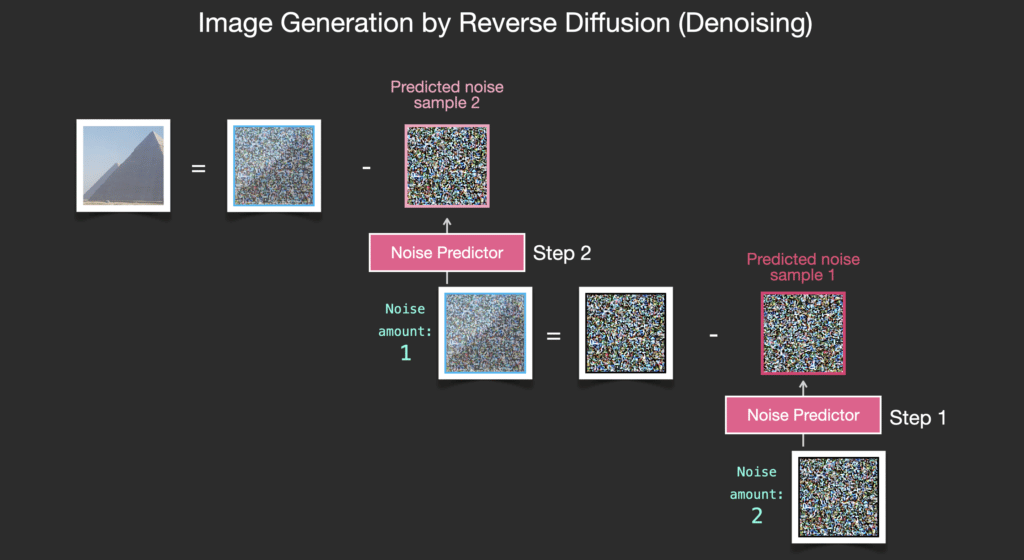
Đến đây là kết thúc quá trình sinh ảnh bằng diffusion được mô tả trong Denoising Diffusion Probabilistic Models. Bây giờ bạn đã có hình dung về diffusion, biết các thành phần chính của không chỉ Stable Diffusion mà còn cả Dall-E 2 và Imagen của Google.
Lưu ý rằng quá trình diffusion mà chúng ta đã mô tả cho đến nay sẽ tạo ra hình ảnh nhưng không sử dụng bất kỳ dữ liệu văn bản nào. Vì vậy, nếu chúng ta triển khai mô hình này, nó sẽ tạo ra những hình ảnh đẹp mắt, nhưng không có cách nào kiểm soát nếu đó là hình ảnh kim tự tháp, con mèo hay bất kỳ thứ gì khác. Trong các phần tiếp theo, chúng ta sẽ mô tả cách kết hợp văn bản để kiểm soát hình ảnh mà mô hình tạo ra.
Tăng tốc: Diffusion trên dữ liệu nén (latent) thay vì ảnh pixel
Để tăng tốc quá trình tạo hình ảnh, bài báo của Stable Diffusion chạy quá trình này không phải trên các hình ảnh pixel mà trên một phiên bản nén của chúng. Bài báo gọi đây là “Departure to Latent Space”.
Quá trình nén này (và sau đó là giải nén/vẽ) được thực hiện thông qua Autoencoder. Bộ mã hóa tự động nén hình ảnh vào latent space sử dụng bộ mã hóa của nó, sau đó tái tạo lại nó chỉ sử dụng thông tin nén bằng bộ giải mã.
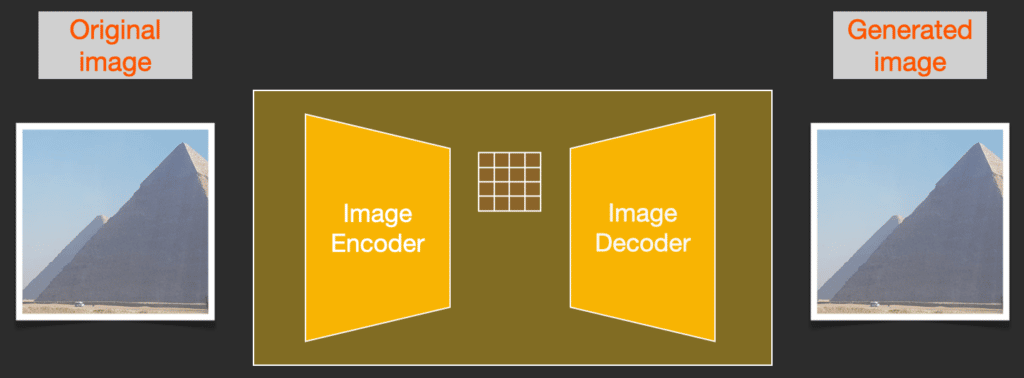
Quá trình diffusion thuận được thực hiện trên latent space, các lớp nhiễu được thêm vào trong không gian này, không phải không gian pixel. Bộ dự đoán nhiễu cũng được huấn luyện trong không gian này.
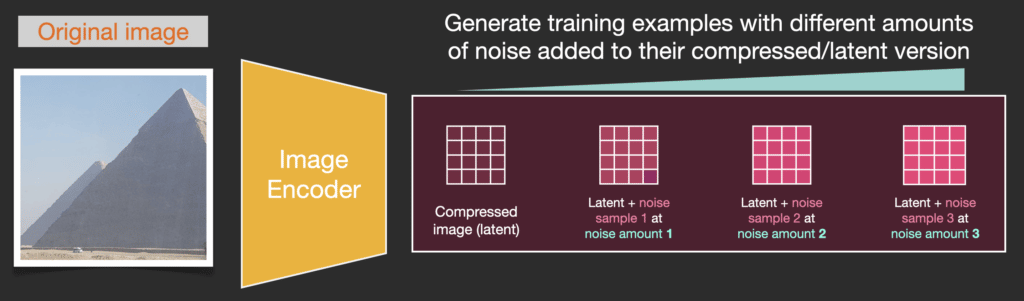
Quá trình thuận (sử dụng bộ mã hóa của Autoencoder) là cách chúng ta tạo dữ liệu để huấn luyện bộ dự đoán nhiễu. Sau khi được huấn luyện, chúng ta có thể tạo hình ảnh bằng cách chạy quá trình nghịch (sử dụng bộ giải mã của Autoencoder).
Hai luồng này là những gì được thể hiện trong Hình 3 của bài báo LDM/Stable Diffusion:
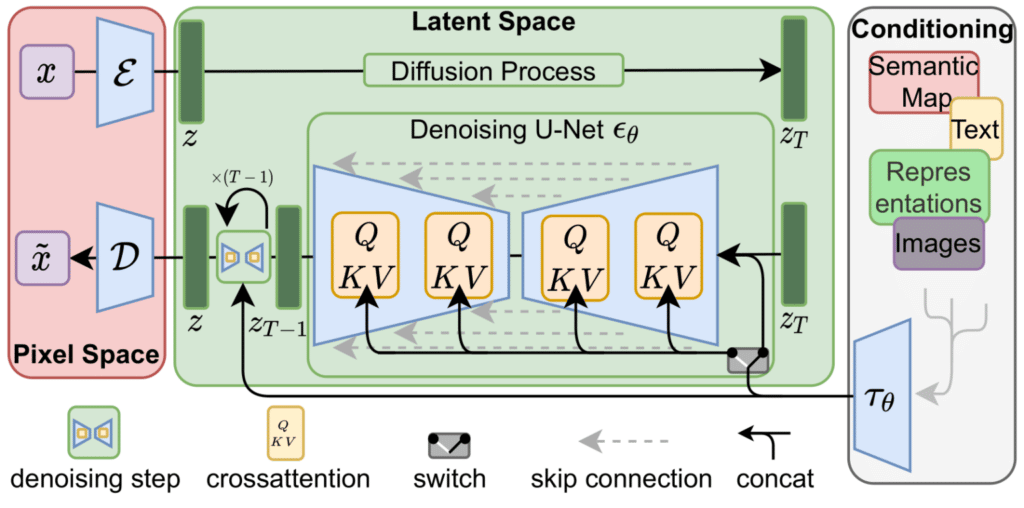
Hình này cũng hiển thị các thành phần “điều khiển”, trong trường hợp này là lời nhắc văn bản mô tả hình ảnh mà mô hình sẽ tạo ra. Vì vậy, hãy đi sâu vào các thành phần văn bản.
Bộ mã hóa văn bản: Mô hình ngôn ngữ Transformer
Mô hình ngôn ngữ Transformer được sử dụng làm thành phần hiểu ngôn ngữ nhận lời nhắc văn bản và tạo mã nhúng token. Mô hình Stable Diffusion đã phát hành sử dụng ClipText (Mô hình dựa trên GPT), trong khi bài báo sử dụng BERT.
Sự lựa chọn mô hình ngôn ngữ được bài báo Imagen chỉ ra là một điều quan trọng. Sử dụng các mô hình ngôn ngữ lớn hơn có ảnh hưởng nhiều hơn đến chất lượng hình ảnh được tạo so với việc nâng cấp các thành phần tạo hình ảnh.
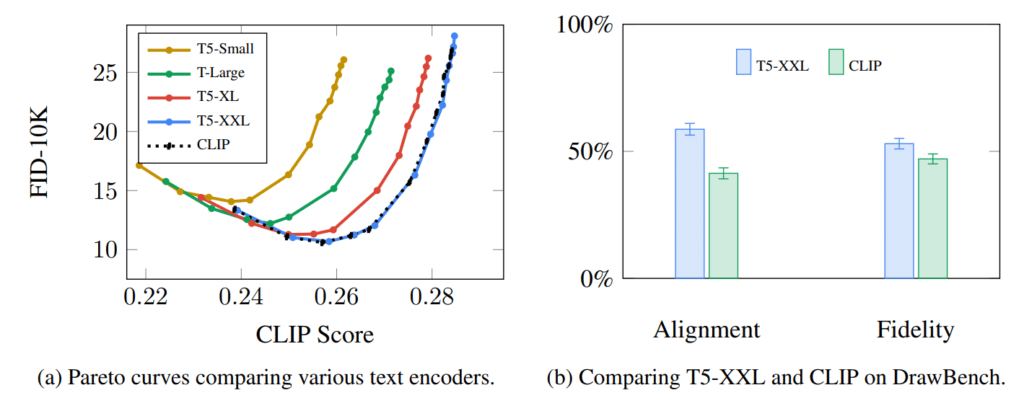
Các mô hình Stable Diffusion ban đầu chỉ đơn giản ghép thêm mô hình ClipText được đào tạo trước do OpenAI phát hành. Các mô hình sau này chuyển sang các biến thể OpenCLIP mới được phát hành và lớn hơn CLIP. Phiên bản mới bao gồm các mô hình văn bản có kích thước lên tới 354 triệu tham số, lớn hơn so với 63 triệu tham số trong ClipText.
CLIP được huấn luyện thế nào?
CLIP được huấn luyện trên tập dữ liệu hình ảnh và chú thích tương ứng. Một bộ dữ liệu trông như sau, chỉ với 400 triệu mẫu huấn luyện:

CLIP huấn luyẹn dựa trên các hình ảnh được thu thập từ web cùng với các thẻ “alt” của chúng.
CLIP là sự kết hợp của bộ mã hóa hình ảnh và bộ mã hóa văn bản. Quá trình huấn luyện nói một cách đơn giản là việc ghép ảnh và chú thích tương ứng của nó. Chúng ta mã hóa cả hai bằng bộ mã hóa hình ảnh và văn bản.
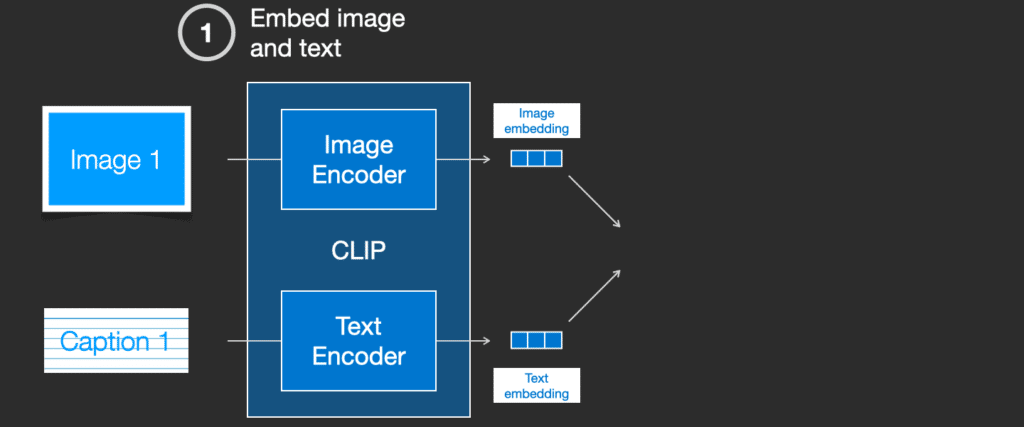
Sau đó, chúng ta so sánh các embedding cách sử dụng độ tương tự cosine. Khi bắt đầu quá trình huấn luyện, độ tương tự sẽ thấp, ngay cả khi văn bản mô tả hình ảnh là chính xác.
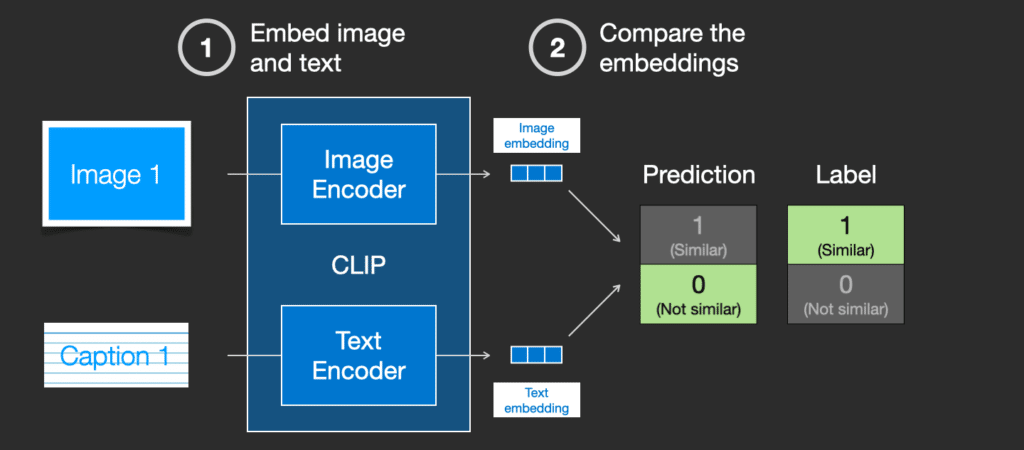
Chúng ta cập nhật hai mô hình để lần sau khi đưa cặp ảnh và mô tả này vào, các mô hình sẽ cho ra các embedding với độ tương tự lớn hơn.
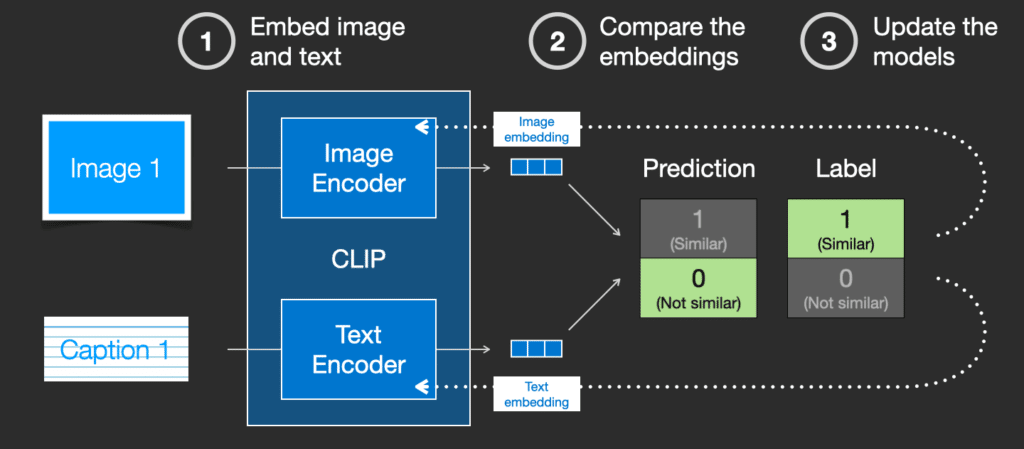
Bằng cách lặp lại điều này trên tập dữ liệu, chúng ta có được các bộ mã hóa có thể tạo ra embedding trong đó hình ảnh của một con chó và câu “hình ảnh của một con chó” là tương tự nhau. Cũng giống như trong word2vec, quá trình huấn luyện cũng cần bao gồm các phản ví dụ về hình ảnh và chú thích không khớp, mô hình cần gán cho chúng điểm tương tự thấp.
Cung cấp thông tin văn bản vào quá trình tạo hình ảnh
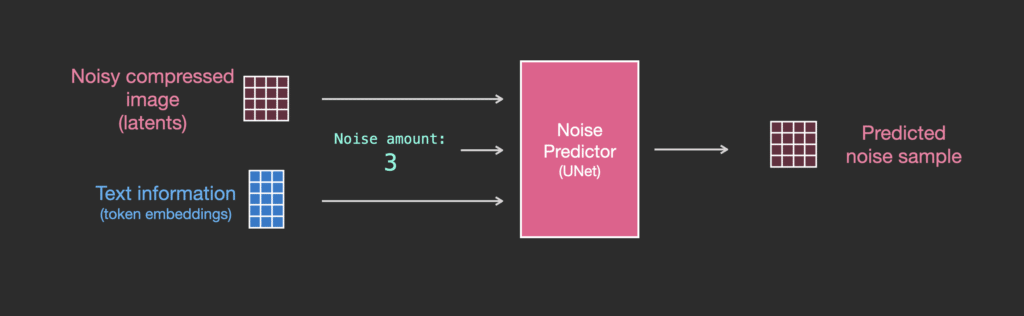
Để làm cho văn bản trở thành một phần của quá trình tạo hình ảnh, chúng ta phải điều chỉnh bộ dự đoán nhiễu để sử dụng văn bản làm đầu vào.
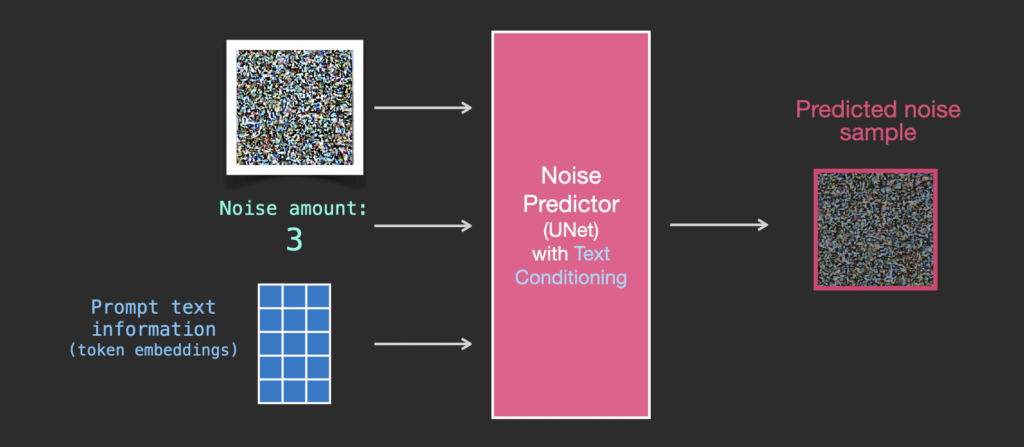
Bộ dữ liệu của chúng ta hiện bao gồm văn bản được mã hóa. Vì chúng ta đang hoạt động trong latent space nên cả hình ảnh đầu vào và nhiễu được dự đoán đều nằm trong không gian này.
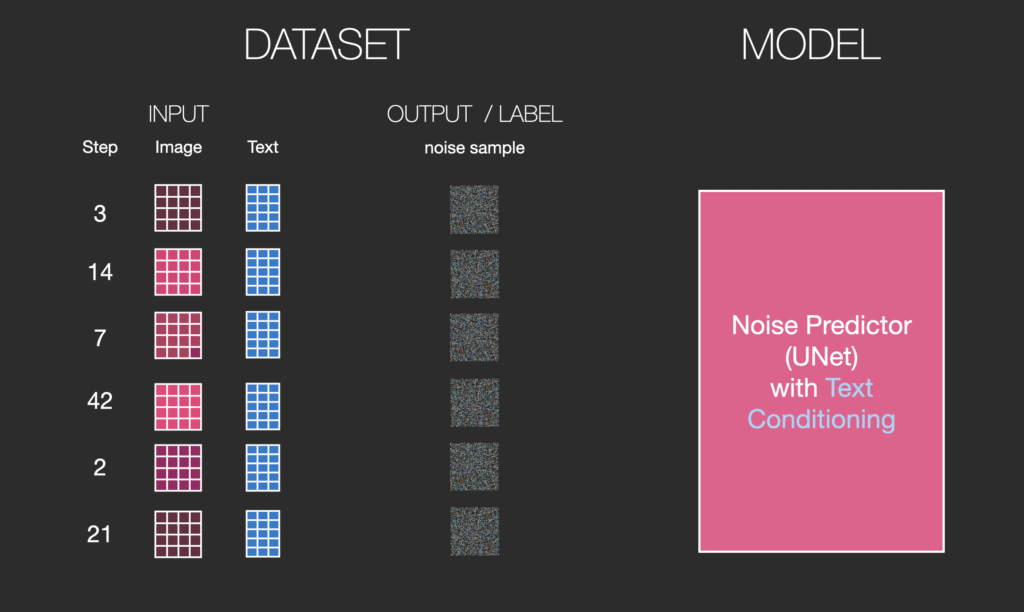
Để hiểu rõ hơn về cách các token văn bản được sử dụng trong Unet, hãy tìm hiểu sâu hơn bên trong Unet.
Các lớp của bộ dự đoán nhiễu Unet (không có văn bản)
Trước tiên chúng ta hãy xem một diffusion Unet không sử dụng văn bản. Đầu vào và đầu ra của nó sẽ trông như :
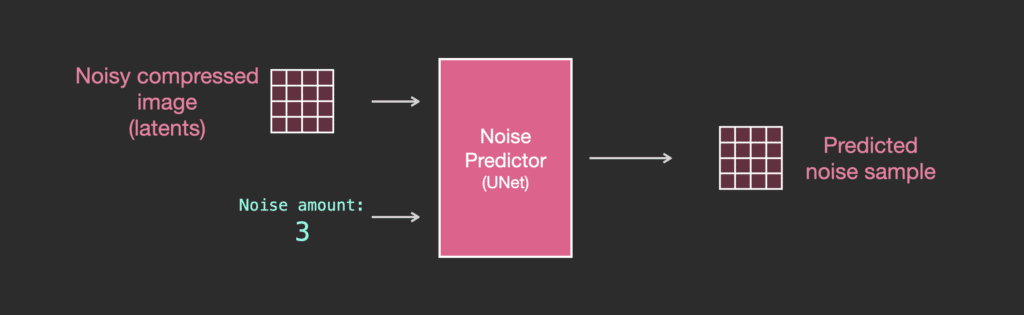
Bên trong, chúng ta thấy rằng:
- Unet là một loạt các lớp để biến đổi mảng latent
- Mỗi lớp thực hiện biến đổi trên đầu ra của lớp trước
- Một số đầu ra được chuyển tiếp (thông qua các kết nối residual) vào quá trình xử lý sau đó trong mạng
- Timestep được chuyển đổi thành một timestep embedding vector và được sử dụng trong các lớp
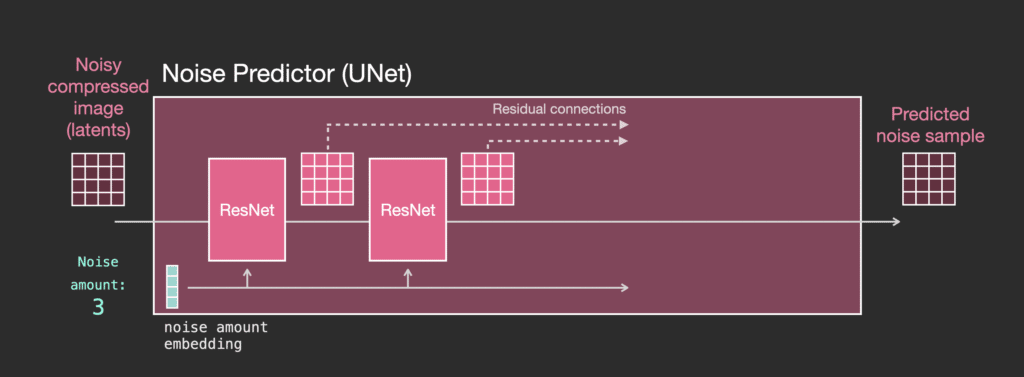
Các lớp của bộ dự đoán nhiễu Unet (có văn bản)
Bây giờ chúng ta hãy xem cách thay đổi hệ thống này để có attention vào văn bản.
Thay đổi chính mà chúng ta cần thêm để hệ thống hỗ trợ văn bản (thuật ngữ kỹ thuật: text conditioning) là thêm một lớp attention giữa các khối ResNet.
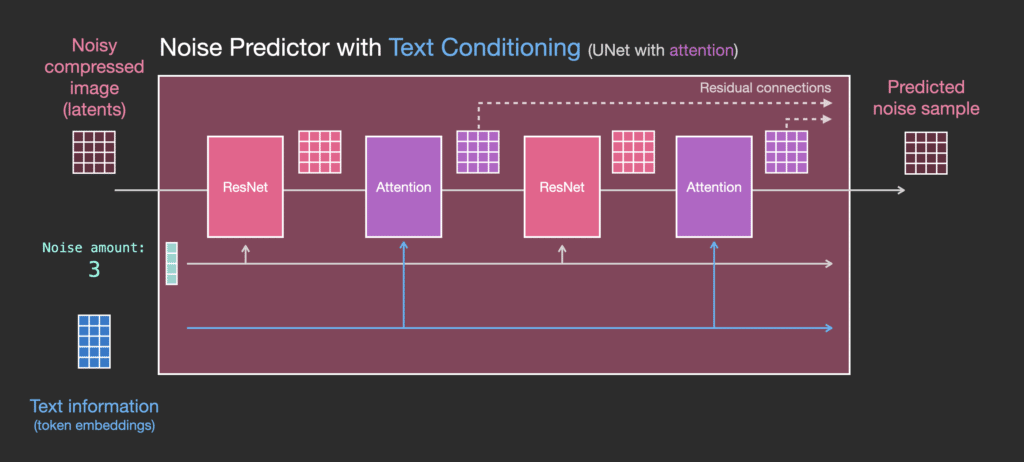
Lưu ý rằng khối ResNet không nhìn trực tiếp vào văn bản. Nhưng các lớp attention hợp nhất các biểu diễn văn bản đó trong các biểu diễn latent. Và vì thế, khối ResNet tiếp theo có thể sử dụng thông tin văn bản được kết hợp đó trong quá trình xử lý của mình.
Tổng kết
Tôi hy vọng bài viết này mang lại cho bạn một hình dung ban đầu về cách hoạt động của Stable Diffusion. Trong bài có rất nhiều khái niệm khác có liên quan, nhưng tôi tin rằng chúng sẽ dễ hiểu hơn khi bạn đã quen thuộc với các khối ở trên. Các tài nguyên bên dưới là những bước tiếp theo mà tôi cho rằng hữu ích. Vui lòng liên hệ với tôi trên Twitter nếu có bất kỳ yêu cầu chỉnh sửa hoặc phản hồi nào.
Tài nguyên
- I have a one-minute YouTube short on using Dream Studio to generate images with Stable Diffusion.
- Stable Diffusion with ???? Diffusers
- The Annotated Diffusion Model
- How does Stable Diffusion work? – Latent Diffusion Models EXPLAINED [Video]
- Stable Diffusion – What, Why, How? [Video]
- High-Resolution Image Synthesis with Latent Diffusion Models [The Stable Diffusion paper]
- For a more in-depth look at the algorithms and math, see Lilian Weng’s What are Diffusion Models?
- Watch the great Stable Diffusion videos from fast.ai
Nếu bạn thích bài viết này, hãy chia sẻ nó với những người quan tâm và hãy thường xuyên truy cập website để có những thông tin mới nhất về lĩnh vực.