
Jukebox là mạng nơ ron nhân tạo có khả năng sáng tác nhạc được giới thiệu bởi OpenAI vào tháng 4/2020. Nó có khả năng sinh âm thanh thô giống WaveNet và sáng tác được âm nhạc với các thể loại khác nhau.
Bên trên là một đoạn được sáng tác bởi Jukebox, bạn có thể xem thêm toàn bộ các bản nhạc tại đây.
Động lực để các nhà khoa học tại OpenAI phát triển Jukebox đó là xây dựng một nhạc sỹ AI đúng nghĩa, có khả năng viết lời, viết nhạc và phát ra được âm thanh thô như giọng hát của con người. Đây là điều vượt xa giới hạn của các nghiên cứu trước đây, vốn chỉ có thể làm việc trên các ký hiệu tượng trưng như hợp âm hay nốt nhạc.
Jukebox được phát triển qua hai pha chính là nén âm thanh thành tín hiệu rời rạc và sử dụng Transformer để học và sinh các mã âm thanh.
Việc rời rạc hóa âm thanh được thực hiện thông qua mô hình mang tên VQ-VAE. Các tác giả nén âm thanh 44kHz với tốc độ lần lượt 8x, 32x, 128x sử dụng tập mã có độ lớn 2048. Nén và rời rạc hóa âm thanh làm mất đi một số chi tiết, mặc dù vậy, các thông tin về cao độ, âm sắc và âm lượng vẫn được bảo toàn.
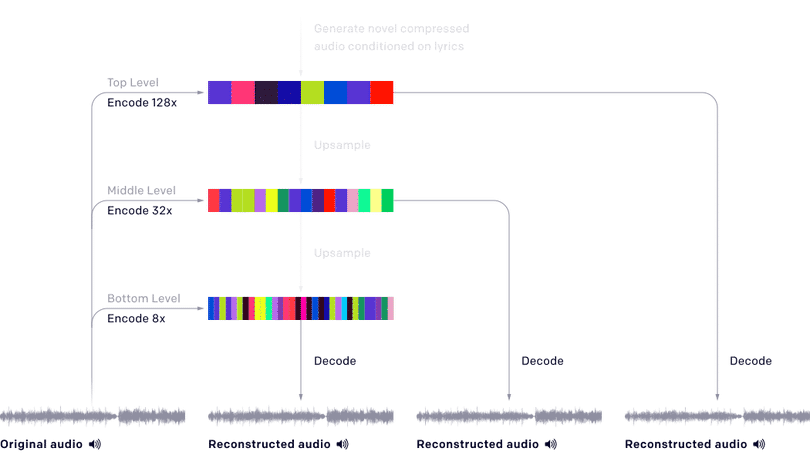
Tiếp theo, mô hình được huấn luyện để học ra các phân phối xác xuất của các mã âm thanh được mã hóa bởi VQ-VAE và từ đó sinh âm nhạc trong không gian rời rạc này. Giống như VQ-VAE, các tác giả sử dụng 3 cấp độ với mức độ nén giảm dần.
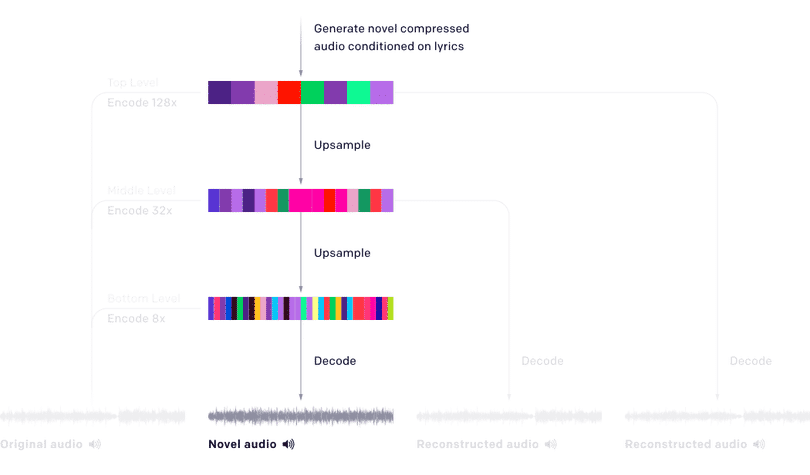
Cấp đầu tiên có mức độ nén cao nhất, đồng nghĩa với chất lượng âm thanh kém nhất. Mặc dù vậy, nó giúp bắt được các ngữ nghĩa ở mức độ trừu tượng cao như ca khúc và giai điệu. Ở mức độ nén thấp, các thông tin về âm sắc được bổ sung, giúp tăng đáng kể chất lượng âm thanh.
Các tác giả huấn luyện các mô hình tự hồi quy với phiên bản đơn giản của Sparse Transformers. Mỗi mô hình có 72 lớp self-attention trên ngữ cảnh có 8192 mã, tương ứng với khoảng 24 giây, 6 giây và 1.5 giây trên các cấp độ nén khác nhau.
Sau khi các mô hình được huấn luyện, các mã âm thanh được sinh ra và được giải mã về âm thanh thô sử dụng bộ giải mã VQ-VAE.
Các tác giả crawl và lựa chọn dữ liệu từ 1,2 triệu bài hát (600K bài là tiếng Anh), khớp với lời bài hát và siêu dữ liệu từ LyricWiki. Siêu dữ liệu bao gồm nhạc sỹ, album, năm sáng tác, tâm trạng giai điệu, các từ khóa gắn với bài hát. Mô hình được huấn luyện trên nhạc 32-bit, 44.1 kHz và được augment bằng cách downmix các kênh âm thanh.
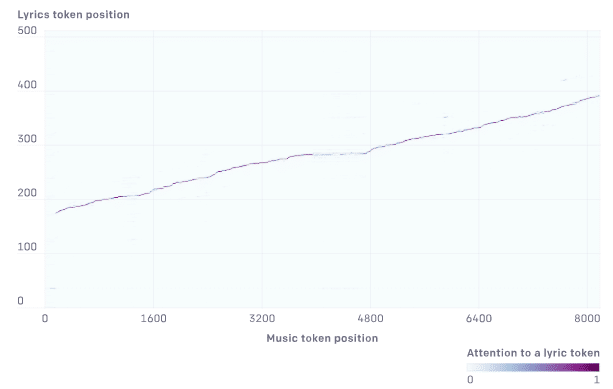
Lớp phía trên của Transformer được huấn luyện với nhiệm vụ dự đoán từ các chuỗi âm thanh, do đó cung cấp được các thông tin bổ sung như nhạc sỹ, dòng nhạc. Để khớp lời và nhạc, các tác giả sử dụng bộ mã hóa lyric kết hợp với bộ giải mã âm thanh thông qua attention.
Măc dù vẫn còn một khoảng cách khá xa giữa Jukebox và các bản nhạc được viết bởi con người, Jukebox mở ra những khả năng và tương lai mới cho ngành sản xuất âm nhạc tự động.
Nếu bạn thích chủ đề này, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io, tham gia các cộng đồng của chúng tôi trên các mạng xã hội hoặc đăng ký bản tin để có được những thông tin cập nhật nhất về Trí tuệ nhân tạo.