Tìm hiểu về Deep learning chắc hẳn các bạn sẽ gặp nhiều thuật ngữ đặc thù. Để có thể hiểu sâu sắc các khía cạnh kỹ thuật của Deep learning, bạn cần phải hiểu về Gradient (độ dốc) – một khái niệm trong tính toán không gian véc tơ.
Gradient (độ dốc) là khái niệm rất gần với khái niệm đạo hàm mà chúng ta đã học thời cấp 3, nó biểu diễn cho tốc độ thay đổi của hàm. Gradient là một vectơ trong khi đạo hàm là giá trị vô hướng (hiểu nôm na là các giá trị số). Véc tơ này chỉ ra hướng mà tại đó giá trị của hàm thay đổi nhiều nhất và trở thành véc tơ 0 khi hàm đạt giá trị cực đại hoặc cực tiểu địa phương.
Một cách diễn đạt trực quan, tưởng tượng như ta đang ở trên một quả núi. Tại chân núi, các chỗ trũng của thung lũng và tại đỉnh núi, độ dốc bằng không. Tùy vào hình dạng của quả núi và vị trí ta quan sát, độ dốc sẽ có những giá trị khác nhau. Khi đang ở đỉnh núi thì đi về hướng nào cũng là “đường xuống núi” cả.

Quay trở lại khái niệm đạo hàm mà ta học thời cấp 3. Đại lượng này cho chúng ta tốc độ thay đổi của hàm dựa trên một biến số duy nhất, thường được đặt là x. Ví dụ, dF/dx cho chúng ta biết hàm F thay đổi bao nhiêu khi x thay đổi 1 đơn vị. Đối với một hàm có nhiều biến, chẳng hạn như x và y, nó sẽ có nhiều đạo hàm: các giá trị dF/dx và dF/dy cho ta biết giá trị của hàm sẽ thay đổi thế nào nếu ta thay đổi một biến số (với giả định các biến số khác không thay đổi).
Chúng ta có thể biểu diễn các tỷ lệ này trong một vectơ nhiều thành phần, với một thành phần là một đạo hàm. Do đó, một hàm có 3 biến sẽ có một gradient với 3 thành phần:
- F (x) có một biến và một đạo hàm duy nhất: dF / dx
- F (x, y, z) có ba biến và ba đạo hàm: (dF / dx, dF / dy, dF / dz)
Giống như đạo hàm thông thường, gradient chỉ ra hướng thay đổi mạnh nhất của hàm. Do đó nó có thể được sử dụng thể tìm ra các cực đại và cực tiểu địa phương. Trong một hàm đơn biến, để thay đổi giá trị của hàm, chúng ta chỉ có hai hướng “tiến” và “lùi” dựa trên sự thay đổi trên trục x. Đối với hàm đa biến, mọi việc không đơn giản như vậy. Với hàm hai biến, chúng ta có thể tưởng tượng đó là vô số các hướng trong một mặt phẳng, với hàm ba biến, đó có thể là bất kỳ hướng nào trong không gian 3 chiều. Với hàm 100 biến (như đầu vào của mạng nơ ron sử dụng word embedding 100 chiều), nó vượt ra khỏi sức tưởng tượng của chúng ta. Mặc dù vậy, gradient là công cụ toán học tuyệt vời để ta có thể khảo sát sự biến thiên của những hàm này.
Gradient được ký hiệu bằng chữ delta (Δ) ngược và được gọi là “del”. Với ví dụ trên, ta có:
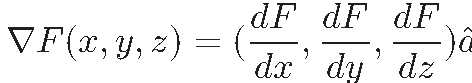
Thành phần của gradient là đạo hàm riêng đối với x, y và z. Đối với một hàm một biến gradient chính là đạo hàm của hàm này.
Ứng dụng phổ biến của gradient là tìm kiếm các giá trị cực đại và cực tiểu của hàm. Đây là nhiệm vụ quan trọng để tối ưu các trọng số trong mạng Deep learning.
Hi vọng thông qua bài viết này các bạn đã hiểu hơn về Gradient. Đây là khái niệm quan trọng nếu như bạn muốn hiểu các sâu sắc các khía cạnh kỹ thuật của Deep learning, từ đó có thể thiết kế được các mô hình tốt hơn.
Hãy theo dõi trituenhantao.io để nhận được thông báo ngay khi có bài viết mới nhé!