Retrieval Augmented Generation (RAG) là một kỹ thuật mạnh mẽ trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), kết hợp ưu điểm của các mô hình ngôn ngữ được đào tạo trước với hệ thống truy xuất thông tin. Mục đích chính của RAG là nâng cao khả năng của mô hình ngôn ngữ lớn (LLM), đặc biệt là trong các nhiệm vụ đòi hỏi sự hiểu biết sâu sắc và tạo ra câu trả lời phù hợp với ngữ cảnh.
Tổng quan về RAG
RAG bao gồm hai thành phần chính: trình truy xuất tài liệu và mô hình ngôn ngữ lớn (LLM). Trình truy xuất tài liệu chịu trách nhiệm tìm kiếm thông tin liên quan từ một số lượng lớn tài liệu dựa trên truy vấn đầu vào. Thông tin này sau đó được chuyển đến LLM, để tạo ra phản hồi.
RAG được thiết kế để giải quyết những hạn chế của các mô hình ngôn ngữ truyền thống. Điểm độc đáo của RAG là cách nó kết hợp hai thành phần này, cho phép mô hình xem xét nhiều tài liệu đồng thời khi tạo ra câu trả lời, dẫn đến đầu ra chính xác và phù hợp với ngữ cảnh hơn.
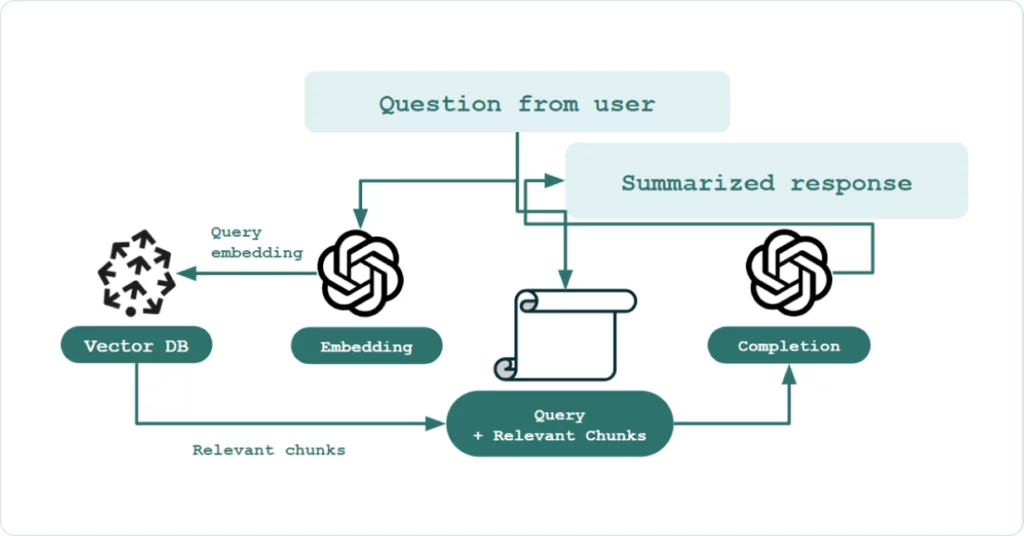
Nó đặc biệt hiệu quả đối với các nhiệm vụ yêu cầu sự hiểu biết sâu sắc về ngữ cảnh và khả năng tham chiếu nhiều nguồn thông tin, chẳng hạn như trả lời câu hỏi.
Áp dụng RAG cho mô hình ngôn ngữ lớn (LLMs)
Áp dụng RAG cho LLMs đại diện cho một bước tiến quan trọng trong lĩnh vực xử lý ngôn ngữ tự nhiên. RAG giúp nâng cao khả năng tạo ra câu trả lời chính xác hơn và giảm hiện tượng hallucination của mô hình.
Thành phần truy xuất tài liệu và tạo câu trả lời
Trình truy xuất tài liệu trong RAG-LLM thường là một trình truy xuất vector, như Dense Passage Retriever (DPR) để có kết quả truy xuất chính xác hơn. Trong khi đó, trình tổng hợp câu trả lời là một mô hình biến đổi lớn như GPT3.5, GPT4, Llama2, Falcon, PaLM và BERT.
Huấn luyện mô hình RAG-LLM
Để huấn luyện mô hình này, công việc điều chỉnh cả bộ trích xuất và bộ tạo dựa trên dữ liệu trả lời câu hỏi.
Ví dụ: Nếu chúng ta có một văn bản và một câu hỏi liên quan đến văn bản đó, trình truy xuất sẽ tìm kiếm phần nào của văn bản liên quan nhất đến câu hỏi. Sau đó, trình tổng hợp câu trả lời sẽ xem xét phần văn bản được chọn và câu hỏi, để tạo ra câu trả lời phản hồi phù hợp.
Ứng dụng của RAG trong LLMs
RAG kết hợp với LLMs có nhiều ứng dụng trong lĩnh vực AI sinh tổng hợp và xử lý ngôn ngữ tự nhiên (NLP):
- Trả lời câu hỏi: RAG tốt trong việc trả lời câu hỏi, nhờ khả năng truy xuất tài liệu và tạo câu trả lời chính xác, phù hợp với ngữ cảnh.
- Tóm tắt văn bản: RAG có thể dùng để tạo tóm tắt cho các tài liệu dài, thông qua việc tìm ra những phần quan trọng nhất của tài liệu.
- Hoàn thành văn bản: Mô hình RAG có thể dùng để hoàn thành các đoạn văn bản dựa trên nội dung và ngữ cảnh hiện có, như viết thư điện tử hoặc hoàn thiện mã nguồn.
- Dịch: Dù không phải là mục đích chính, RAG cũng có thể được sử dụng cho nhiệm vụ dịch thuật, thông qua việc truy xuất các bản dịch liên quan từ dữ liệu và tạo ra bản dịch phù hợp với những ví dụ đã có.
Ưu điểm của RAG-LLM
RAG-LLM cho phép mô hình tận dụng kiến thức ngoài từ một kho dữ liệu văn bản lớn, giúp câu trả lời chính xác và mang tính thông tin hơn. Ngoài ra, RAG còn giúp giảm bớt sự hallucination trong câu trả lời và tiết kiệm chi phí.
Hãy chia sẻ bài viết này và thường xuyên truy cập trituenhantao.io cũng như các kênh thông tin khác của chúng tôi để cập nhật kiến thức mới nhất về các lĩnh vực liên quan.