")
Topic Modeling là một kiểu mô hình thống kê giúp khai phá các chủ đề ẩn trong tập dữ liệu. Trong bài này, tôi sẽ không đi sâu vào giới thiệu về Topic Modeling, mà tôi sẽ giới thiệu thuật toán Latent Dirichlet Allocation (LDA) và Non-negative Matrix Factorization (NMF), những thuật toán phổ biến trong bài toán Topic Modeling.
Có rất nhiều mã nguồn mở hiện nay cung cấp cho thuật toán LDA, điển hình như thư viện Gensim trên Python. Đây là một thư viện hữu ích cung cấp môi trường thực hiện trên quy mô tập văn bản lớn. Tuy nhiên, Gensim lại không hỗ trợ thuật toán Non-negative Matrix Factorization (NMF).
NMF đươc hỗ trợ trong Scikit Learn từ lâu. Và những năm gần đây, Scikit Learn đã hỗ trwoj thêm LDA. Điểm mạnh của Scikit Learn là có sự nhất quán trong API, điều này giúp cho việc thực hiện Topic Modeling cả bằng NMF và LDA rất dễ dàng.
LDA và NMF hoạt động như thế nào?
Nền tảng toán học của hai thuật toán LDA và NMF là khác nhau, nhưng kết quả cuối cùng cả hai thuật toán đều trả về các tài liệu thuộc về một chủ đề trong kho văn bản và các từ thuộc về một chủ đề. LDA dự trên mô hình phân phối xác xuất trong khi NMF dựa trên mô hình đại số tuyến tính. Đầu vào của thuật toán là Bag of Word matrix (nghĩa là mỗi tài liệu được biểu diễn dưới dạng một hàng, với mỗi cột là số lượng từ trong kho). Mục đích của phương thức này là tạo ra 2 ma trận nhỏ hơn: một ma trận theo tài liệu và một ma trận từ theo chủ đề. Khi nhân 2 ma trận với nhau, ta sẽ được túi ma trận với sai số thấp nhất.
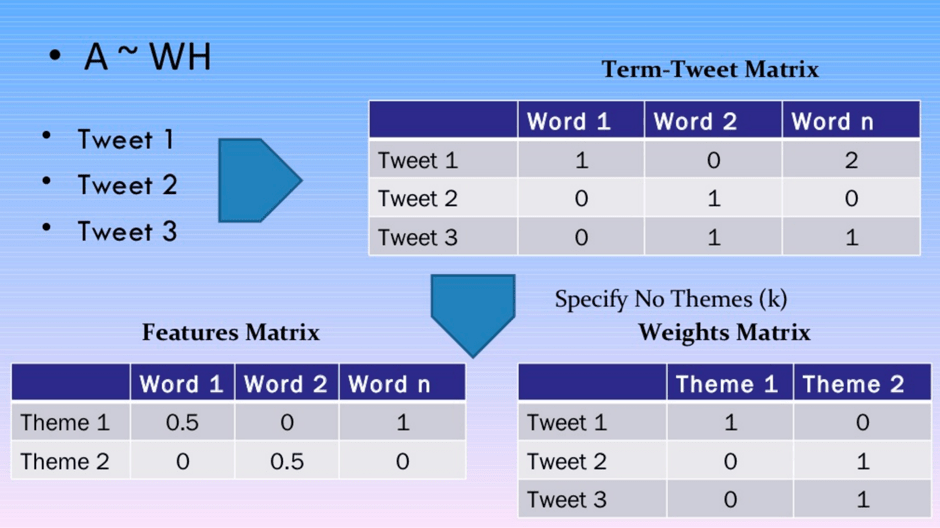
Ma trận với thuật toán NMF
Lưu ý khi sử dụng hai thuật toán này là ta cần xác định được hệ số “k” – số lượng chủ đề cho trước.
Topic Modeling với thư viện Scikit Learn
Bộ dữ liệu ví dụ trong bài này là bộ 20 Newsgoups trong thư viện Scikit Learn. Đây là bộ dữ liệu ví dụ phổ biến sử dụng và các tiêu đề, gạch chân, và dấu ngoại đề đã được xử lý.
from sklearn.datasets
import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.data
Scikit Learn hỗ trợ tạo ma trận từ rất dễ dàng bằng cách trích xuất các tình năng cần thiết có xử lý bộ dữ liệu văn bản. TF-IDF kết hợp với mô hình Bag of words Matrix, trong NMF ta có thể sử dụng TfidfVectorizer. Mặt khác, LDA thiên về mô phỏng xác xuất (có nghĩa là xử lý các tần xuất) chỉ yêu cầu số lượng thô, do đó, ta có thể sử dụng lệnh CountVectorizer. Giả sử ta đã loại bỏ hết những Stop Words và giới hạn số lượng từ vector trong mỗi túi là 1000.
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
no_features = 1000
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
# LDA can only use raw term counts for LDA because it is a probabilistic graphical model
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tf = tf_vectorizer.fit_transform(documents)
tf_feature_names = tf_vectorizer.get_feature_names()
Xây dựng mô hình với thư viện Scikit Learn
Như phần trên đã nói, cả NMF vàLDA đều không xác định được thông số k – số lượng chủ đề văn bản.Do vậy, trong bài này, ta giả sử xác định 20 chủ đề với 2 thuật toán này.
from sklearn.decomposition import NMF, LatentDirichletAllocation
no_topics = 20
# Run NMF
nmf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf)
# Run LDA
lda = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
Đánh giá kết quả của hai thuật toán NMF và LDA
Về cơ bản, cấu trúc ma trận kết quả trả về của NMF và LDA là giống nhau, và cách thức thực hiện trên thư viện Scikit Learn của cả 2 thuật toán cũng giống nhau. Điều này giúp ta có thể hiển thị top trọng tâm trong mỗi chủ đề.
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
no_top_words = 10
display_topics(nmf, tfidf_feature_names, no_top_words)
display_topics(lda, tf_feature_names, no_top_words)
Dưới đây là kết quả phân cụm chủ đề bằng thuật toán NMF và LDA. Với thuật toán NMF, ta thấy chủ đề 0 và 8 rất khó để tìm được tên chủ đề thích hợp, còn những chủ đề khác thì có thể tìm được tên chủ đề.
Thuật toán LDA với bộ dữ liệu cho kết quả có 2 nhóm chủ đề với dữ liệu nhiễu ( Chủ đề 4 và 7) và một số chủ đề khó tìm được tên chủ đề (Chủ đề 3 và 9).
Với bài toán này, ta thấy NMF đã có kết quả tốt hơn so với LDA.
Bảng kết quả:
Với thuật toán NMF:
Topic 0: people don think like know time right good did say
Topic 1: windows file use dos files window using program problem card
Topic 2: god jesus bible christ faith believe christian christians church sin
Topic 3: drive scsi drives hard disk ide controller floppy cd mac
Topic 4: game team year games season players play hockey win player
Topic 5: key chip encryption clipper keys government escrow public use algorithm
Topic 6: thanks does know mail advance hi anybody info looking help
Topic 7: car new 00 sale price 10 offer condition shipping 20
Topic 8: just like don thought ll got oh tell mean fine
Topic 9: edu soon cs university com email internet article ftp send
Với thuật toán LDA:
Topic 0: government people mr law gun state president states public use
Topic 1: drive card disk bit scsi use mac memory thanks pc
Topic 2: said people armenian armenians turkish did saw went came women
Topic 3: year good just time game car team years like think
Topic 4: 10 00 15 25 12 11 20 14 17 16
Topic 5: windows window program version file dos use files available display
Topic 6: edu file space com information mail data send available program
Topic 7: ax max b8f g9v a86 pl 145 1d9 0t 34u
Topic 8: god people jesus believe does say think israel christian true
Topic 9: don know like just think ve want does use good
Trong bài tiếp theo, tôi sẽ đưa ra phương pháp thảo luận trong việc xây dựng kết quả đầu ra chủ đề văn bản tốt hơn.
Nguồn: https://medium.com