
Giới thiệu
Anthropic vừa phát hành mô hình AI mới có tên “Claude 3.5 Sonnet”. Mô hình này hứa hẹn mang lại hiệu suất vượt trội so với các mô hình trước đó như Claude 3 Opus. Ngoài việc nhanh hơn gấp 2 lần và rẻ hơn gấp 5 lần, Claude 3.5 Sonnet còn được trang bị cửa sổ ngữ cảnh lớn lên tới 200K, làm cho nó phù hợp với các tác vụ phức tạp như hỗ trợ khách hàng theo ngữ cảnh và quản lý quy trình nhiều bước. Nhưng liệu nó có thể vượt qua GPT-4o hay không? Hãy cùng tìm hiểu qua bài đánh giá chi tiết dưới đây.
So Sánh Tốc Độ
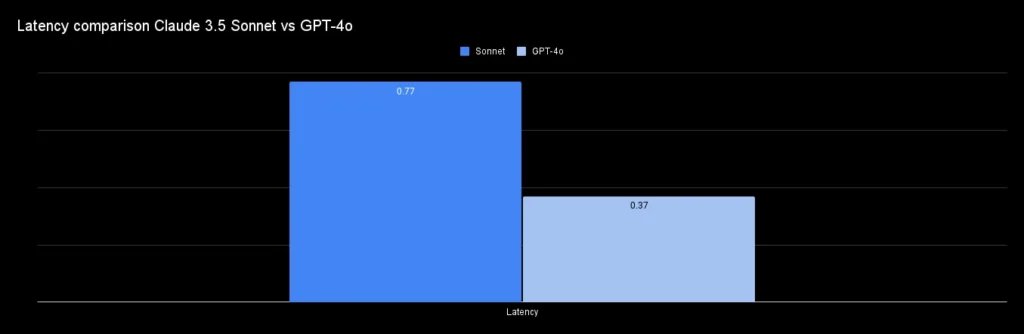
So Sánh Độ Trễ
Claude 3.5 Sonnet được tối ưu hóa để nhanh hơn Claude 3 Opus, nhưng trong so sánh với GPT-4o, Claude 3.5 Sonnet vẫn thua về độ trễ. Điều này có thể ảnh hưởng đến trải nghiệm thời gian thực trong các ứng dụng yêu cầu phản hồi tức thì.
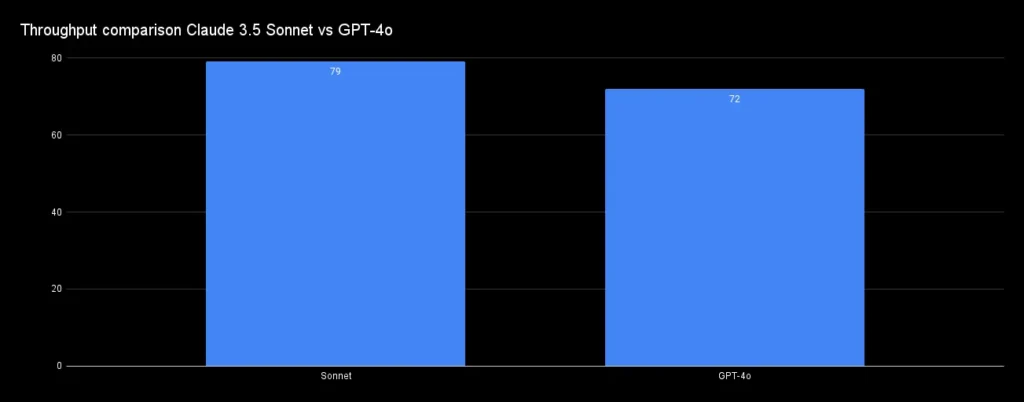
So Sánh Throughput
Khả năng cung cấp dữ liệu, hay còn gọi là throughput, của Claude 3.5 Sonnet đã được nâng cấp đáng kể. Mô hình này có khả năng cung cấp tới 79 tokens mỗi giây, mang lại hiệu suất gần như ngang ngửa với GPT-4o.
Hiệu Suất Theo Benchmark
Bảng so sánh dưới đây cho thấy Claude 3.5 Sonnet không chỉ vượt trội trong khả năng suy luận cấp đại học mà còn đặc biệt tốt trong việc viết mã và toán học đa ngữ.
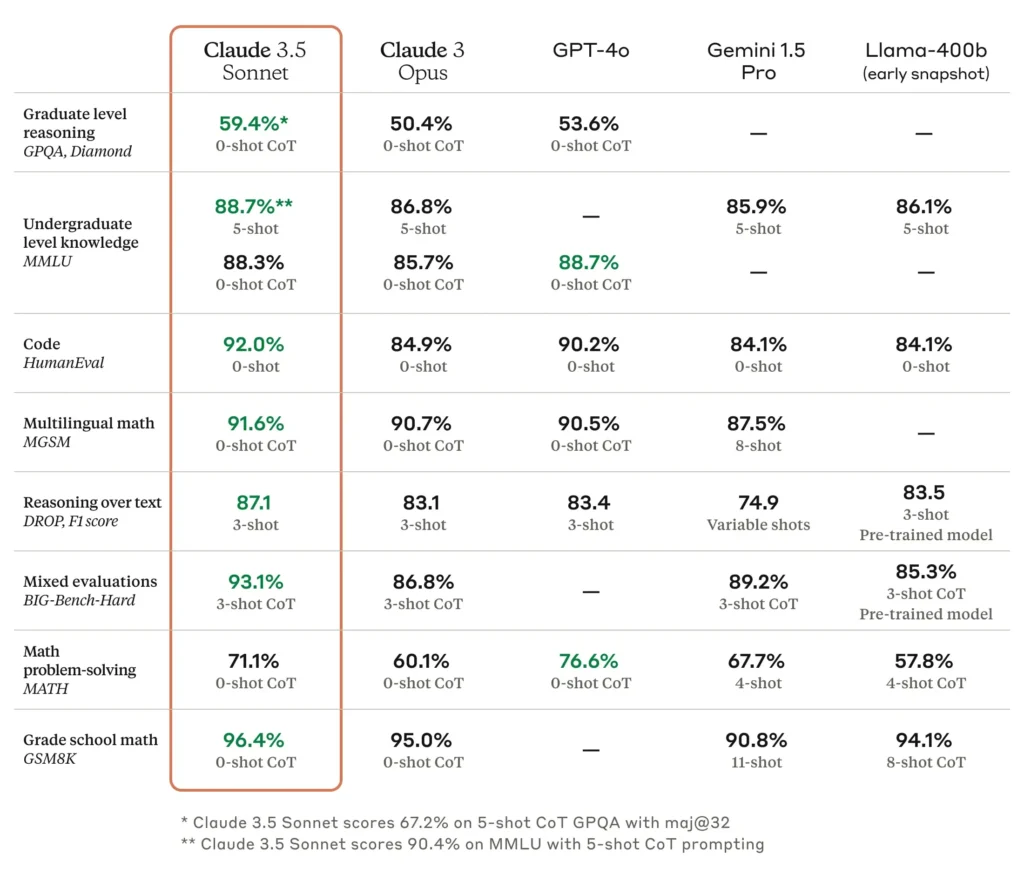
Tuy nhiền, đây là bảng so sánh được cung cấp bởi chính Claude. Nếu bạn đang tìm một đánh gia độc lập, hãy đọc tiếp.
Nhiệm vụ 1: Trích xuất dữ liệu
Để đánh giá khả năng trích xuất dữ liệu từ các hợp đồng pháp lý, chúng tôi đã thử nghiệm hai mô hình trên một tập dữ liệu gồm các hợp đồng dịch vụ. Cả hai mô hình đều gặp khó khăn với độ chính xác chỉ đạt 60-80%, nhưng GPT-4o nhỉnh hơn Claude 3.5 Sonnet một chút về số lượng thông tin trích xuất chính xác.
Chi tiết đánh giá:
Trong nhiệm vụ này, cả Claude 3.5 Sonnet và GPT-4o đều gặp khó khăn trong việc trích xuất các thông tin quan trọng như tiêu đề hợp đồng, tên khách hàng, và điều khoản kết thúc.
{
"contract_title": "MASTER",
"customer": "VENDOR",
"effective_date": "01/01/2022",
"initial_term": "1 năm"
}GPT-4o đã thực hiện tốt hơn trong việc nhận diện các điều khoản quan trọng. Tuy nhiên, việc đạt được độ chính xác cao hơn vẫn cần nhiều kỹ thuật prompt hơn.
Nhiệm vụ 2: Phân loại
Trong nhiệm vụ phân loại ticket khách hàng, Claude 3.5 Sonnet đã thể hiện độ chính xác tổng thể tốt hơn với tỉ lệ chính xác đạt 72%, vượt qua GPT-4o với 65%. Tuy nhiên, GPT-4 có độ chính xác cao nhất lên đến 77%.
Kết quả phân loại:
Claude 3.5 Sonnet đã nhận diện đúng các ticket khách hàng thành công và chưa thành công với độ chính xác cao, mặc dù phải đối mặt với các trường hợp lỗi phức tạp. GPT-4o có độ chính xác cao nhất (86.21%) khi tương tác với false positives (lỗi dương tính giả), điều này rất quan trọng trong việc đảm bảo ticket khách hàng được phân loại chính xác để tránh sự không hài lòng của khách hàng.
Bảng so sánh độ chính xác:
| Mô Hình | Độ Chính Xác | Precision | Recall | F1 Score |
| GPT-4o | 65% | 86.21% | 44.64% | 58.82% |
| Claude 3.5 Sonnet | 72% | 85.00% | 60.71% | 70.83% |
| GPT-4 | 77% | 73.91% | 91.07% | 81.60% |
| Claude 3 Opus | 72% | 83.33% | 62.50% | 71.43% |
Nhiệm vụ 3: Suy luận
Khi kiểm tra khả năng suy luận ngữ nghĩa, GPT-4o đã vượt trội với độ chính xác đạt 69%, so sánh với 44% của Claude 3.5 Sonnet. GPT-4o chứng minh sự xuất sắc trong các bài toán liên quan đến lịch trình, thời gian và suy luận đối ngược từ vựng.
Rõ ràng dữ liệu đã cho thấy Claude 3.5 Sonnet có độ chính xác thấp hơn GPT-4o trong các bài toán suy luận từ ngữ và phép tính số.
Kết Luận
Claude 3.5 Sonnet nổi bật với khả năng viết mã vượt trội và hiệu quả cải thiện đáng kể về tốc độ cung cấp dữ liệu, tuy nhiên, xét về tổng quan các tác vụ thì GPT-4o vẫn chiếm ưu thế với độ chính xác cao hơn trong các bài toán suy luận và phân loại.
Nếu bạn muốn đầu tư vào một trong hai mô hình này, hãy cân nhắc kỹ lưỡng các yêu cầu và mong muốn đối với dự án của bạn. Đừng quên thường xuyên theo dõi https://trituenhantao.io để cập nhật những thông tin mới nhất về trí tuệ nhân tạo!