Performer là một biến thể của Transformer mở rộng attention một cách tuyến tính, cho phép huấn luyện nhanh hơn và cho phép mô hình làm việc trên độ dài lớn hơn.
Các mô hình Transformer đã mang lại kết quả state-of-the-art trên đa dạng các lĩnh vực bao gồm ngôn ngữ tự nhiên, hội thoại, ảnh và thậm chí là âm nhạc. Thành phần cốt yếu của tất cả các kiến trúc Transformer là mô đun attention, có nhiệm vụ tính sự liên quan giữa các cặp vị trí trong câu đầu vào. Mặc dù vậy, cách tiệp cận này khó có thể mở rộng khi độ dài của đầu vào lớn. Cụ thể, thời gian và bộ nhớ để tính tất cả sự tương đồng của các vị trí sẽ tăng theo lũy thừa bậc 2.
Trong thực tế, các ứng dụng luôn cần attention trên câu dài. Do đó các giải pháp tăng cường tốc độ và bộ nhớ đã được đề xuất như các kỹ thuật caching hoặc sử dụng attention thưa. Attention thưa chỉ tính toán độ tương tự trên một số cặp lựa chọn chứ không tính trên toàn bộ các cặp có thể có trong chuỗi đầu vào. Do đó, kết quả của phương pháp này là một ma trận thưa hơn so với attention đầy đủ.
Đầu vào của attention thưa có thể được cài đặt thủ công, tìm kiếm bằng các phương pháp tối ưu hóa, học từ dữ liệu hoặc thậm chí là khởi tạo ngẫu nhiên. Một số ví dụ của các phương pháp này là Sparse Transformers, Longformers, Routing Transformers, Reformers, và Big Bird. Vì các ma trận thưa có thể được biểu diễn bởi đồ thị, phương pháp làm thưa được lấy cảm hứng từ mạng nơ ron đồ thị với các quan hệ cụ thể được attention. Kiến trúc thưa như vậy thường đòi hỏi các tầng bổ sung để có thể tạo ra ma trận attention đầy đủ.
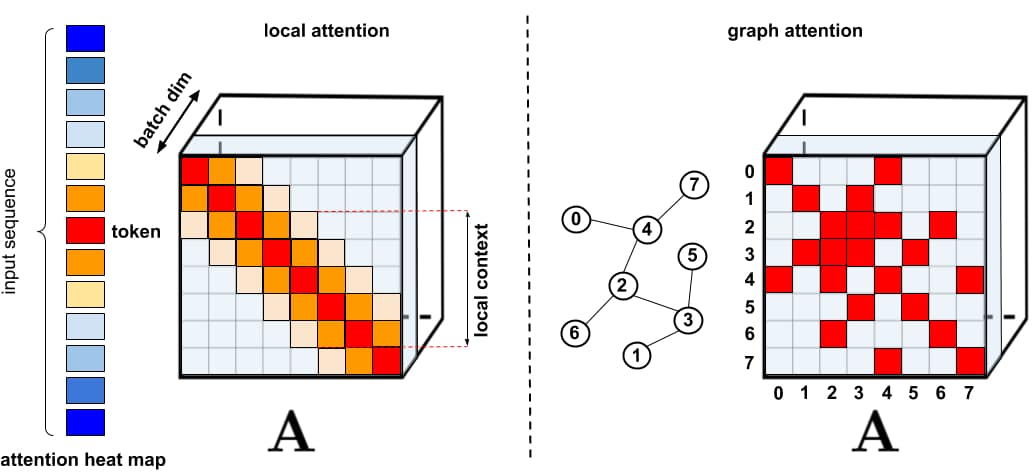
Bên cạnh ưu điểm, phương pháp làm thưa vẫn có một số hạn chế. (1) Chúng đòi hỏi các phép toán nhân ma trận thưa hiệu quả, đôi khi các phép toán này không được hỗ trợ; (2) Chúng thường không được đảm bảo chặt chẽ bởi lý thuyết; (3) Chúng thường chủ yếu tối ưu cho Transformer và các mô hình sinh pretraining; (4) Chúng thường chồng nhiều tầng attention để khắc phục biểu diễn thưa, do đó khó có thể phối hợp với một mô hình pretrain khác. Bên cạnh đó, attention thưa không đủ để giải quyết nhiều bài toán mà attention thông thường có thể giải quyết, như là Pointer Network. Có những phép toán không thể thưa hóa và cũng không thể thay thế, như hàm softmax, hiện đang được sử dụng nhiều trong các hệ gợi ý thực tế trong công nghiệp.
Để giải quyết vấn đề trên, các tác giả đề xuất Performer, một kiến trúc Transformer có thể mở rộng attention một cách tuyến tính, cho phép huân luyện nhanh hơn và cho phép mô hình làm việc trên độ dài lớn hơn. Mô hình này cần thiết cho các dataset như ImageNet64 hay PG-19. Performer sử dụng một framework attention tổng quát hiệu quả (tuyến tính), cho phép phối hợp các cơ chế attention dựa trên các phép đo tương tự khác nhau (gọi là các kernel). Framework được cài đặt bởi thuật toán FAVOR+. Độ chính xác của phương pháp này được đảm bảo trong khi duy trì độ phức tạp (thời gian + bộ nhớ) tuyến tính và có thể ứng dụng cho một phép toán softmax độc lập.
Đối với cơ chế attention gốc, query và key là hàng và cột của ma trận, được nhân vào nhau và truyền qua softmax để tạo nên ma trận attention, lưu trữ các giá trị về độ tương tự. Phương pháp này không thể khôi phục được các giá trị query và key khi đã truyền qua hàm softmax. Mặc dù vậy, ma trận attention có thể được phân giải thành tích của các hàm phi tuyến tính của các query và key, giúp mã hóa thông tin về độ tương tự một cách hiệu quả hơn. Đây là ý tưởng chính để giảm độ phức tạp khi tính attention.
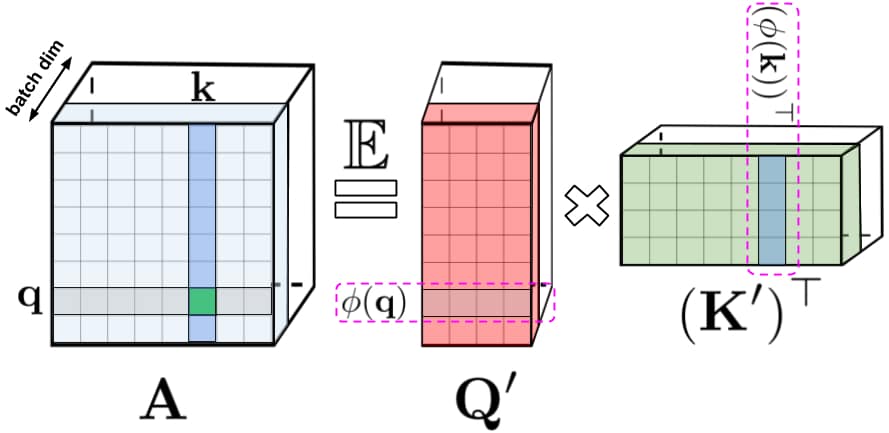
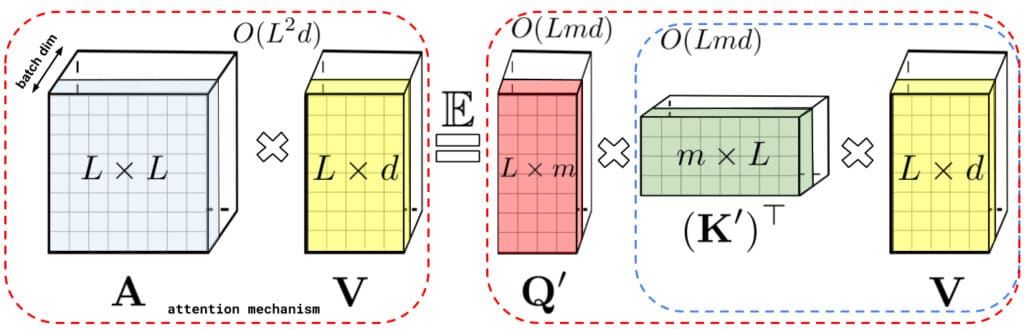
Phương pháp phân tích ma trận trên giúp lưu trữ ma trận attention một cách gián tiếp với bộ nhớ tuyến tính, thay vì bình phương. Trong khi cơ chế attention gốc nhân ma trận attention với value để có được kết quả cuối cùng, ta có thể thực hiện nhân ma trận theo một cách khác với các ma trận con được phân tích. Theo đó, thời gian thực hiện cũng chỉ ở mức tuyến tính.
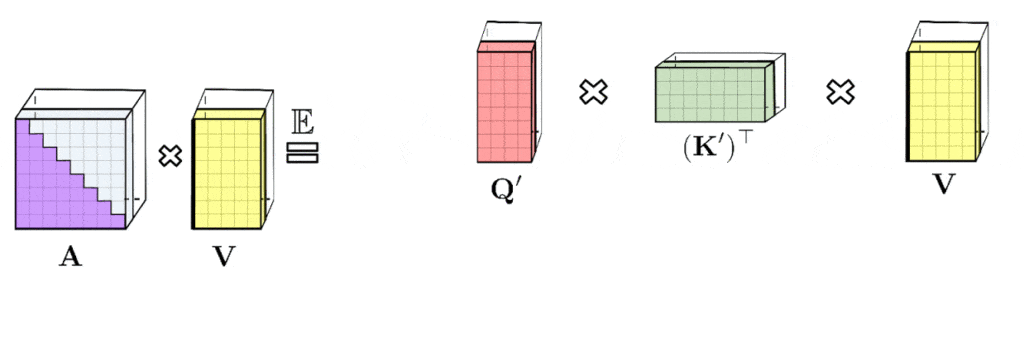
Phân tích trên đúng với attention hai chiều, tức là không có ký hiệu cho các token trước và sau. Đối với attention một chiều, các tác giả điều chỉnh cách tiếp cận, sử dụng mảng cộng dồn, chỉ lưu trữ tổng hiện tại của các phép toán trên ma trận.
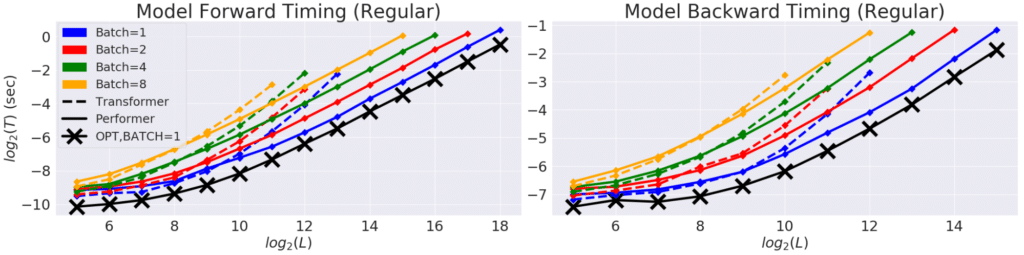
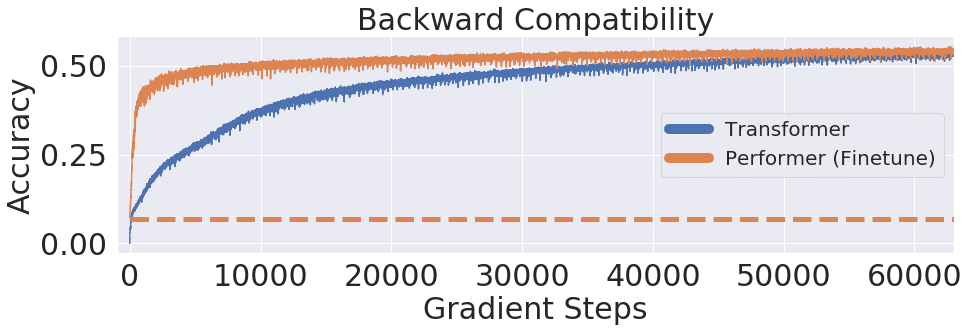
Các thực nghiệm trên Performer cho thấy độ phức tạp tính toán và bộ nhớ tối ưu hơn Transfomer. Bên cạnh đó, Performer cũng cần ít bước tối ưu để đạt độ chính xác bão hòa.
Để có thể tìm hiểu sâu về Performer, bạn có thể đọc paper, tải code, hoặc vọc code ứng dụng Performer vào bài toán Protein Language Modeling.
Nếu bạn thích bài viết này, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập website hoặc đăng ký (dưới chân trang) để có được những thông tin cập nhật và chuyên sâu về lĩnh vực.