![[NLP] Xử lý POS với thuật toán Conditional Random Fields](https://trituenhantao.io/wp-content/uploads/2019/04/pos-tagging.png "[NLP] Xử lý POS với thuật toán Conditional Random Fields")
Trong lĩnh vực Xử lý ngôn ngữ tự nhiên (NLP), hầu hết các mô hình cơ bản đều được xây dựng dựa trên phương pháp Bag of Words. Nhưng, các mô hình như vậy không thể xác định được các mối quan hệ về cú pháp giữa các từ.
Ví dụ: với một mô hình phân tích cảm xúc được xây dựng trên phương pháp Bag of Words. Ta không thể xác định được sự khác biệt trong câu :”I like you”, trong đó, động từ “like” là một động từ chỉ tình cảm tích cực. Và tương tự, với một câu khác: “I am like you” thì động từ “like” là là chỉ sự giống nhau giữa hai chủ thể chứ không chỉ tình cảm.
Vậy có cách nào ta có thể cải thiện thuật toán Bag of Words không?
Part of Speech (POS – gắn nhãn từ vựng) là một phương pháp trong xây dựng cây cú pháp mà tại đó ta có thể xác định NERs (các danh từ riêng/chung) và trích xuất quan hệ giữa các từ. Gắn thẻ POS cũng rất cần thiết để xác định được định dạng từ gốc (các dạng từ trong tiếng anh).
Gắn nhãn POS là xác định loại từ của một từ vựng trong ngữ cảnh đoạn văn đó. Để xác định được vấn đề này không hề đơn giản. Vì với một từ cụ thể, trong mỗi ngữ cảnh khác nhau sẽ có những ý nghĩa khác nhau.
Bạn có thể nhìn ví dụ sau: “Give me your answer” thì answer là một danh từ. Nhưng với câu “Answer the question” thì answer là một động từ.
Để máy tính có thể thực sự hiểu nghĩa của một câu và trích xuất được cấu trúc ngữ pháp của nó, thì POS là một bước quan trọng.
Các phương pháp gắn thẻ POS
Hiện nay có rất nhiều kĩ thuật gắn thẻ POS khác nhau:
- Lexical Based Methods : gắn nhãn POS mỗi từ theo dạng từ xuất hiện có tần suất cao nhất trong bộ dữ liệu.
- Rule-Based Methods : gắn nhã POS dựa trên một quy tắc xác định. Ví dụ: trong tiếng anh, những từ có kết thúc bằng “ed” hoặc “ing” thường được gán là một động từ. Phương pháp Rule-Based Methods có thể kết hợp với phương pháp Lexical Based Methods để gắn nhãn những từ có trong bộ train nhưng không có trong bộ test.
- Probabilistic Methods: Phương pháp dự theo xác suất. Phương pháp này gắn nhã POS dựa trên xác xuất xảy ra của một chuỗi nhãn cụ thể. Thuật toán Conditional Random Fields (CRFs) và Hidden Markov Models (HMMs) là hai phương pháp phổ biến nhất.
- Deep Learning Methods: Sử dụng mạng nơ ron để gắn nhãn POS.
Trong bài viết này, chúng ta sẽ xem xét đến thuật toán Conditional Random Fields (CRFs) trong bộ dữ liệu Penn Treebank Corpus (thuộc thư viện NLTK).
Trường xác suất có điều kiện (Conditional Random Fields – CRFs)
CRFs là thuật toán xác suất có điều kiện. Sự khác biệt ở mô hình này là sự phân phối xác suất theo điều kiện P(y/x), và xác suất này sẽ cố gắng đưa về xác suất bình thường: P(y, x).
Mô hình hồi quy Logistic, SVM, CRFs là những thuật toán phân loại có điều kiện. Naive Bayes, HMMs là những thuật toán phân loại sinh mẫu. CRFs được sử dung cho việc gắn nhãn NREs và POS.
Trong thuật toán CRFs, đầu vào là tập hợp các thuộc tính (dạng số thực) từ tập dữ liệu đầu vào theo một quy tắc. Trọng số của biểu thức với các thuộc tính đầu vào cùng các nhãn đã được găn thẻ trước đó và task sẽ được dùng để dự đoán cho việc nhãn gắn hiện tại. Ta sẽ ước lượng trọng số sao cho chỉ số likelihood của nhãn trog bộ dữ liệu train là cực đại.
Hàm mục tiêu trong thuật toán sẽ xác định nhãn cho mỗi từ trong câu. Hãy tưởng tượng với một ví dụ sau: chữ cái đầu tiên của từ có phải là chữ cái viết hoa không?; các tiền tố và hậu tố của từ có dạng như thế nào?; …
Trong CRFs, chúng ta cũng xây dựng dự đoán nhãn từ hiện tại theo nhãn của các từ trước đó. Các trọng số của mô hình sẽ được hợp lý nhất.
Giờ chúng ta hãy tìm hiểu bài toán gắn nhãn POS trên phần mềm Python. Các bạn có thể tham khảo code đầy đủ tại đây.
Data Set
Chúng ta sẽ làm ví dụ với bộ dữ liệu NLTK Treebank trên thư viện NLTK. Các nhãn trên NLTK được gắn trên thư viện gồm 12 nhãn: Động từ, Danh từ, Đại từ, Tính từ, Trạng từ, Adpositions, Conjunctions, Determiners, Cardinal Numbers, Particles, Từ khác / Từ mượn, Dấu câu. Bộ dữ liệu gồm có 3.914 câu được gắn thẻ và 12.408 từ vựng.
tagged_sentence = nltk.corpus.treebank.tagged_sents(tagset='universal')
print("Number of Tagged Sentences ",len(tagged_sentence))
tagged_words=[tup for sent in tagged_sentence for tup in sent]
print("Total Number of Tagged words", len(tagged_words))
vocab=set([word for word,tag in tagged_words])
print("Vocabulary of the Corpus",len(vocab))
tags=set([tag for word,tag in tagged_words])
print("Number of Tags in the Corpus ",len(tags))
Tiếp theo, chúng ta sẽ chia bộ dữ lieeujt hành bộ Train và bộ Test theo tỉ lệ 80:20. Như vậy, sẽ có 3,131 câu thuộc bộ dữ liệu train và 783 câu thuộc bộ dữ liệu test.
train_set, test_set = train_test_split(tagged_sentence,test_size=0.2,random_state=1234)
print("Number of Sentences in Training Data ",len(train_set))
print("Number of Sentences in Testing Data ",len(test_set))
Tạo các thuộc tính
Để xác định nhãn POS, chúng ta sẽ xây dựng một bộ từ điển với nhãn được gắn chô mỗi từ trong câu:
- Chữ cái đầu tiên có phải là chữ viết hoa không (Danh từ riêng có chữ cái đầu tiên viết hoa)?
- Đó có phải là từ đầu tiên trong câu không?
- Đó có phải là từ cuối cùng không?
- Từ này có chứa cả chữ và số không?
- Từ này có dấu gạch nối ở giữa không (phần này được áp dụng trong tiếng anh, những tính từ dài thường có dấu gạch nối: ví dụ: fast-growing, slow-moving).
- Các chữ cái đều được viết hoa toàn bộ?
- Đó là một số?
- Bốn hậu tố và tiền tố của từ là gì? (Trong tiếng anh, những từ có đuôi “ed” thường là động từ; những từ kết thúc bằng “ous” thường là tính từ.
Thuộc tính sẽ được xác định theo công thức như hình dưới và những features cho bộ dữ liệu train và test sẽ được trích xuất ra.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | def features(sentence,index): ### sentence is of the form [w1,w2,w3,..], index is the position of the word in the sentence return { 'is_first_capital':int(sentence[index][0].isupper()), 'is_first_word': int(index==0), 'is_last_word':int(index==len(sentence)-1), 'is_complete_capital': int(sentence[index].upper()==sentence[index]), 'prev_word':'' if index==0 else sentence[index-1], 'next_word':'' if index==len(sentence)-1 else sentence[index+1], 'is_numeric':int(sentence[index].isdigit()), 'is_alphanumeric': int(bool((re.match('^(?=.*[0-9]$)(?=.*[a-zA-Z])',sentence[index])))), 'prefix_1':sentence[index][0], 'prefix_2': sentence[index][:2], 'prefix_3':sentence[index][:3], 'prefix_4':sentence[index][:4], 'suffix_1':sentence[index][-1], 'suffix_2':sentence[index][-2:], 'suffix_3':sentence[index][-3:], 'suffix_4':sentence[index][-4:], 'word_has_hyphen': 1 if '-' in sentence[index] else 0 }def untag(sentence): return [word for word,tag in sentence]def prepareData(tagged_sentences): X,y=[],[] for sentences in tagged_sentences: X.append([features(untag(sentences), index) for index in range(len(sentences))]) y.append([tag for word,tag in sentences]) return X,yX_train,y_train=prepareData(train_set)X_test,y_test=prepareData(test_set) |
Xây dựng mô hình CRFs
Bước tiếp theo, chúng ta sử dụng thư viện sklearn_crfsuite để xây dựng mô hình. Mô hình được tối ưu hóa theo phương pháp Gradient Descent và sử dụng thuật toán LBGS – L1, L2. Mô hình CRFs sẽ giúp gắn nhãn tất cả những các từ, kể cả những từ không có trong bộ tài liệu.
1 2 3 4 5 6 7 8 9 | from sklearn_crfsuite import CRFcrf = CRF( algorithm='lbfgs', c1=0.01, c2=0.1, max_iterations=100, all_possible_transitions=True)crf.fit(X_train, y_train) |
Đánh giá mô hình Conditional Random Fields
Chúng ta sử dụng chỉ số F-score để đánh giá mô hình. F-score sẽ cân bằng hai chỉ số Precision và Recall như sau:
2*((precision*recall)/(precision+recall))
Precision được định nghĩa là tỷ lệ những quan sát được dự đoán đúng trên tổng số quan sát được dự đoán đúng
Recall được định nghĩa là số dự đoán chính xác trên tổng số số quan sát thực sự thuộc lớp đúng.
Precision=TP/(TP+FP)
Recall=TP/(TP+FN)
Mô hình Conditional Random Fields (CRFs) trên đã đưa ra F-score bằng 0.996 với bộ dữ liệu train và 0.97 với bộ dữ liệu test.
01 02 03 04 05 06 07 08 09 10 11 12 13 | from sklearn_crfsuite import metricsfrom sklearn_crfsuite import scorersy_pred=crf.predict(X_test)print("F1 score on Test Data ")print(metrics.flat_f1_score(y_test, y_pred,average='weighted',labels=crf.classes_))print("F score on Training Data ")y_pred_train=crf.predict(X_train)metrics.flat_f1_score(y_train, y_pred_train,average='weighted',labels=crf.classes_)### Look at class wise scoreprint(metrics.flat_classification_report( y_test, y_pred, labels=crf.classes_, digits=3)) |
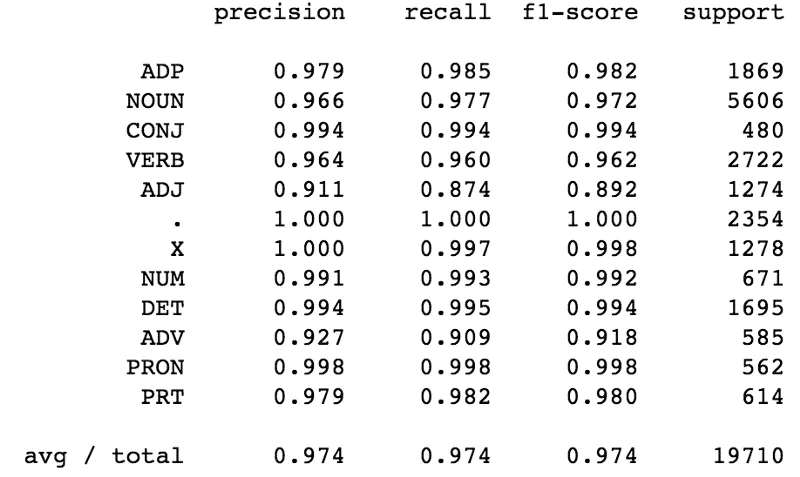
Từ bảng kết quả,, ta thấy rằng để dự đoán một từ có phải là tính từ không, các chỉ số precision, recall và F-score thấp. Như vậy ta cần thêm các features vào mô hình CRFs để dự đoán Tình từ tốt hơn.
Tiếp theo, chúng ta hãy xem cụm những nhãn hay đi cùng nhau nhất:

Như chúng ta thấy, tính từ thường được đi với danh từ. Còn động từ thì thường đi sau những Particle (ví dụ: “to”); những Determinant như “The” thường sẽ theo sau là một danh từ.

Các từ “Will”, “would” thường theo sau là động từ; những từ kết thúc bằng “ed” thường là động từ. Còn nếu trong từ có gạch nối, thì xác suất từ đó là một tính từ sẽ cao hơn. Tương tự như vậy, nếu từ đó bắt đầu bằng một chữ cái viết hoa, thì khả năng từ đó là danh từ cao hơn.
Thuật toán CRFs còn được sử dụng trong rất nhiều bài toán không chỉ POS, ví dụ như Tokenizer, NERs,…
Hi vọng bài sẽ giúp ích cho bạn trong tìm hiểu về xử lý ngôn ngữ tự nhiên.
Hãy theo dõi https://trituenhantao.io để có thêm những kiến thức mới nhé.