
Trong bài trước chúng ta đã tìm hiểu qua về phương pháp Word2Vec. Trong bài này, chúng ta sẽ tìm hiểu mô hình Doc2vec, cách xây dựng mô hình và mối quan hệ với phương pháp Word2vec và những điểm mạnh của phương pháp.
Tại sao Doc2Vec lại cần thiết?
Trên thực tế, dữ liệu chính đầu vào của bài toán Text Mining là tập những văn bản. Bộ dữ liệu này được áp dụng cho hầu hết bài toán Text Mining. Chẳng hạn như bài toán trích xuất văn bản, bài toán tìm kiếm trên Web, bài toán lọc thư rác, hay bài toán Topic Modeling, … Tuy nhiên, ta lại không có nhiều kỹ thuật để chuyển đổi dữ liệu dạng text sang dạng máy tính có thể hiểu với bộ dữ liệu đặc trưng đó.
Một kỹ thuật phổ biến nhất hay sử dụng cho các bài toán này là mô hình Bag of Words (BOW). Mô hình này giúp ta có thể chuyển đổi dữ liệu đầu vào thành những vector theo cấp câu/cấp văn bản đầu vào. Nhưng kết quả đầu ra của mô hình sẽ không có độ chính xác cao. Nguyên nhân do mô hình BOW đã làm mất đi ý nghĩa của các từ cũng như sự sắp xếp các từ trong câu.
Gần đây, kỹ thuật Latent Dirichlet Allocation (LDA) được đánh giá tốt cho bài toán Topic Modeling. Tuy nhiên, kết quả đầu ra của mô hình rất khó hiệu chỉnh và khó có thể đánh giá được.
Năm 2014, ông Tomas Mikolov (một trong những tác giả của Word2Vec) và ông Lê Quốc Vinh đã giới thiệu phương pháp Doc2Vec. Đây là phương pháp giúp chuyển đổi dữ liệu dạng text theo cấp tài liệu/văn bản sang vector giúp máy tính có hiểu hiểu được.
Phương pháp này được xây dựng trên mô hình Word2Vec. Do vậy, phương pháp này không chỉ giúp vector hóa văn bản theo cấp tài liệu (như BOW) mà còn giữ được ý nghĩa của các từ trong văn bản đó.
Ta hãy cùng tìm hiểu nhé.
Mô hình Doc2vec
Trong bài trước, ta đã tìm hiểu ý tưởng xây dựng của phương pháp Word2Vec. Mỗi từ sẽ thông qua những từ xung quanh (ngữ cảnh) để đánh giá độ tương đồng giữa các từ. Từ đó ta có thể biểu diễn được các từ bằng vector mà vẫn giữ được ý nghĩa các từ. Có hai cách xây dựng mô hình Word2vec: CBOW và Continuous skip-gram.
Mô hình Doc2Vec cũng tương tự. Thay vì biểu diễn từ thành những vector, phương pháp Doc2vec sẽ biểu diễn văn bản thành những vector tương ứng. Khác với cấp độ từ, cấp độ văn bản không có những cấu trúc logic như từ ngữ.
Distributed Memory version of Paragraph Vector (PV-DM)
Ý tưởng của thuật toán này khá cơ bản. Dựa trên mô hình word2vec, ta thêm vào một vector khác (được gọi là Paragraph ID). Sau khi train mô hình, ta trích rút từ kết quả đầu ra vector có Paragraph ID.
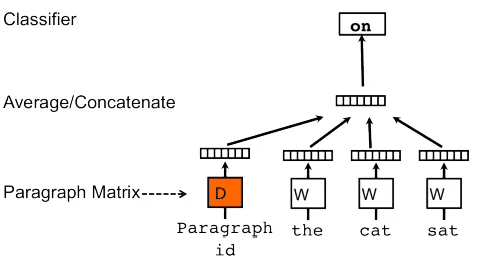
Nhìn mô hình này quen chứ? Đây chính là mô hình mở rộng của CBOW. Nhưng thay vì chỉ sử dụng những từ xung quanh( từ ngữ cảnh) để dự đoán từ mục tiêu, ta còn thêm một thuộc tính vector là một tài liệu vào.
Như vậy, khi chúng ta train vector từ W, vector văn bản D cũng sẽ được train theo cùng. Và kết quả đầu ra, mô hình sẽ đưa ra chỉ số vector của tài liệu đó.
Mô hình train trên được gọi là Distributed Memory version of Paragraph Vector (PV-DM). Hoạt động dựa trên việc ghi nhớ nhớ những gì còn thiếu trong ngữ cảnh, trong chủ đề, hoặc trong đoạn văn. Word vectors sẽ đại diện biểu diễn khái niệm của một từ, document vector như mô tả khái niệm cho một cấp tài liệu
Doc2vec là Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
Cũng giống như Word2vec, một phương pháp khác trong Doc2vec là Distributed Bag of Words version of Paragraph Vector (PV-DBOW) – gần giống phương pháp Skip-gram.
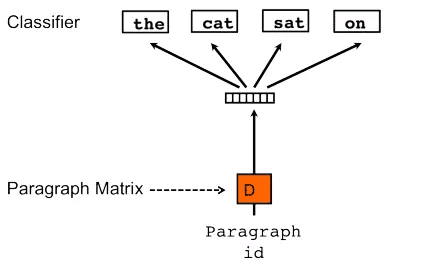
Điểm khác biệt với Word2vec là thuật toán này thật sự nhanh hơn và tốn ít bộ nhớ hơn so với Skip-gram của Word2vec vì không cần phải nhớ các từ.
Tuy nhiên, theo lời khuyên của tác giả, ta nên sử dụng kết hợp cả hai thuật toán, mặc dù mô hình PV-DM vượt trội hơn và thường xuyên đạt được kết quả ở hiện tại.
Kỹ thuật Doc2vec thường được sử dụng trong trường hợp sau: dùng để training mô hình, xây dựng một bộ yêu cầu cấp tài liệu. Khi đó, mỗi vector từ W được tạo cho mỗi từ và mỗi document vector D sẽ được tạo cho mỗi tài liệu. Mô hình cũng chứa những trọng số cho việc đào tạo layer ẩn của mô hình. Trong giai đoạn đưa kết quả mô hình, khi đó tài liệu đầu vào mới được tính toán để đưa ra vector tương ứng.
Đánh giá Mô hình
Đặc điểm của phương pháp Doc2Vec là mô hình train không thực hiện tác vụ mục tiêu của thuật toán. Ta có thể hiểu như sau. Mô hình Word2vec thực hiện train qua những từ ngữ cảnh xung quanh. Nhưng kết quả đầu ra của bài toán là đưa ra độ tương đồng giữa các từ. Như vậy, việc đánh giá độ chính xác của thuật toán sẽ rất khó khăn. Ví dụ với hình vẽ sau:
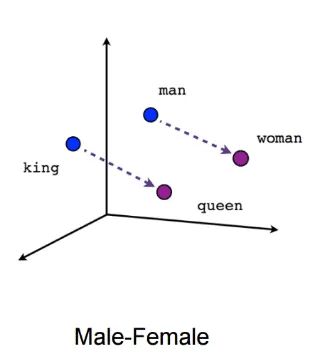
Ta có hể thấy King-Man => Qeen-Woman như hình trên. Những hiện nay không có một quy chuẩn cụ thể nào có thể đánh giá được độ chính xác của mô hình.
Do vậy, khi train mô hình, ta cần lưu ý những tham số của mô hình. Việc lựa chọn tham số sẽ khái quát được dữ liệu đầu vào. Vấn đề này được gọi là analogical reasoning (Lý luận tương đồng). ta có thể xem một vài ví dụ về sự tương đồng dưới đây:
- happy happily — furious furiously
- immediate immediately — infrequent infrequently
- slowing slowed — sleeping slept
- spending spent — striking struck
Mục tiêu đầu ra của mô hình là biểu diễn được những từ có độ tương đồng sẽ có khoảng cách gần nhau.
Ta có thể theo dõi ví dụ sau đây. Đầu vào của thuật toán là 03 đoạn văn như hình dưới.


Ta được kết quả so sánh mô hình như sau:

Kết luận
Ta đã tìm hiểu qua phương pháp Doc2Vec. Cũng gần tương tự như Word2vec, phương pháp Doc2vec cũng có hai cách xây dựng mô hình. Doc2vec có nhiều ưu điểm hơn so với Word2vec. Chúc các bạn có những thành công với phương pháp mới này nhé.
Nguồn: https://trituenhantao.io/