
Attention là một kỹ thuật hiện đại trong các mạng nơ ron nhân tạo. Kỹ thuật này đã chứng minh được tính hiệu quả trong các nhiệm vụ dịch máy hay xử lý ngôn ngữ tự nhiên. Nó cũng là một trong số những thành phần tạo nên đột phá trong các mô hình như BERT hay GPT-2. Trong bài viết này, hãy cùng trituenhantao.io tìm hiểu sâu hơn kỹ thuật này.
Attention là thành phần tạo nên sự khác biệt chính của mô hình đình đám Transformer. Mô hình này tạo nên sự đột phá trong các bài toán của NLP so với các mạng nơ ron hồi quy trước nó. Chúng khác nhau ở cách xử lý đầu vào và cách nhóm các đặc trưng liên quan.
Mạng nơ ron hồi quy và LSTM
Chúng ta sử dụng các từ như thế nào? Một cách đơn giản, ta nối chúng thành một chuỗi, từ này nối tiếp từ kia. Để biểu diễn chuỗi này trong không gian véc tơ, chúng ta cần tối thiểu hai chiều, một chiều biểu diễn các từ khác nhau và một chiều biểu diễn thời gian. Lý do là chúng ta cần các từ khác nhau xuất hiện trong các thời điểm khác nhau để diễn đạt ý tưởng của chúng ta bằng ngôn ngữ. Sẽ thế nào nếu như bạn chỉ được diễn đạt ý tưởng của mình với một từ (hoặc là được sử dụng tất cả các từ với duy nhất một lần phát âm)?!!
Mạng nơ ron hồi quy (RNN) là mô hình sớm ra đời để xử lý thông tin tạo nên bởi các chuỗi từ. Mô hình sẽ đi từ đầu đến cuối chuỗi để có được thông tin liên kết giữa các từ. Mặc dù tiên phong trong xử lý chuỗi nhưng vì tiếp nhận đầu vào một cách không có chọn lọc nên mô hình này gặp phải vấn đề Vanishing Gradient. RNN bị lãng quên cho đến khi các biến thể của nó là LSTM và GRU ra đời giúp tăng cường khả năng ghi nhớ và hiệu quả của mô hình. Mặc dù vậy, khi Attention tham gia vào cuộc chơi, những cải tiến đó là không đủ để cứu vãn số phận của các mô hình dựa trên RNN.
Attention và self-attention
Attention nhận vào hai câu, chuyển chúng thành một ma trận với hàng và cột tương ứng với các từ trong hai câu đầu vào. Attention sẽ khớp các từ của câu này với từ tương ứng ở câu kia để tập trung vào các từ có liên kết mạnh của hai câu. Tính hợp lý của cách tiếp cận này có thể thấy rõ ràng trong dịch máy, bên cạnh ý nghĩa của toàn câu, mô hình cần “chú ý” vào các từ để học được cách dịch tự nhiên nhất.

Attention không bị giới hạn trong việc tìm tương quan giữa các từ trong các câu ở hai ngôn ngữ khác nhau. Chúng ta có thể tạo ra ma trận với hàng và cột là cùng một câu để hiểu những phần nào của câu sẽ liên quan đến nhau. Kỹ thuật này được gọi là “self-attention”, mặc dù vậy, vì nó quá phổ biến nên người ta thường gọi tắt nó là attention.
Attention cho phép mô hình quan sát câu một cách trọn vẹn và nối các từ với ngữ cảnh liên quan đến chúng. Bằng cách này, attention có thể sử dụng thông tin tạo bởi mối quan hệ của các từ dù chúng nằm ở cách xa nhau.
Transformer và multi-headed attention
Ngôn ngữ của con người là một dạng thức rất phức tạp. Cùng một từ, trong mối liên kết với các từ khác nhau thì có ý nghĩa khác nhau. Do đó, để mô hình có thể hoạt động tốt với ngôn ngữ tự nhiên, nó cần có kiến trúc đủ linh hoạt. Sự ra đời của Transformer với kiến trúc sử dụng attention đã tạo nên đột phá trong NLP.
Transformer sử dụng attention để tổng hợp các thông tin về ngữ cảnh tương ứng với một từ và mã hóa ngữ cảnh đó trong chính vector của từ đó. Đây là cách biểu diễn từ một cách thông minh hơn so với các cách biểu diễn truyền thống. Với attention, mô hình có thể học ra được ngữ cảnh của từ ở những phần có liên quan, không quan trọng nó ở gần hay cách xa vị trí của từ trong câu. Với thông tin đó, mô hình có thể hiểu được ý nghĩa của từ và vai trò của nó trong câu.
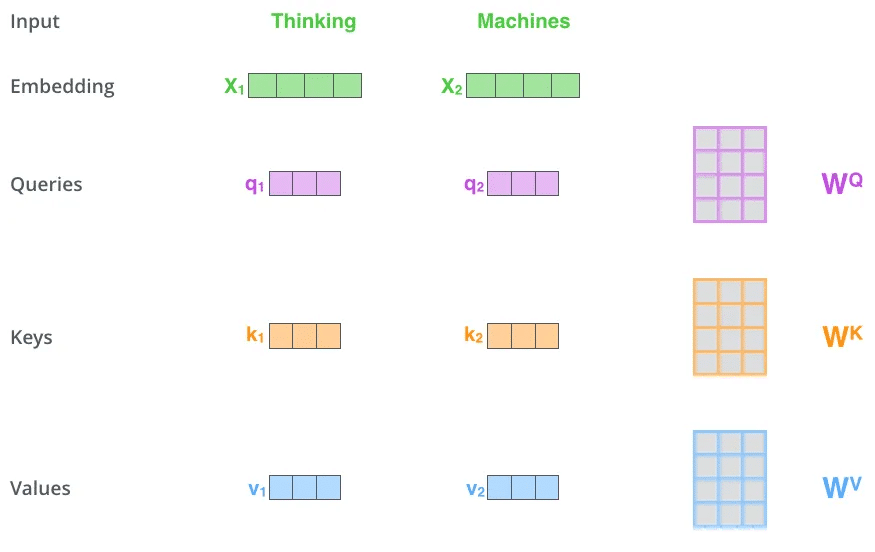
Trong kiến trúc khá phổ biến của Transformer, đối với mỗi từ, chúng ta có một khóa K, giá trị V và truy vấn Q. Truy vấn Q sẽ tìm kiếm trong các giá trị khóa K của tất cả các từ để tìm ra ứng viên cung cấp ngữ cảnh cho nó (thông qua tích vô hướng). Cuối cùng, ta có ma trận đầu ra của lớp attention:
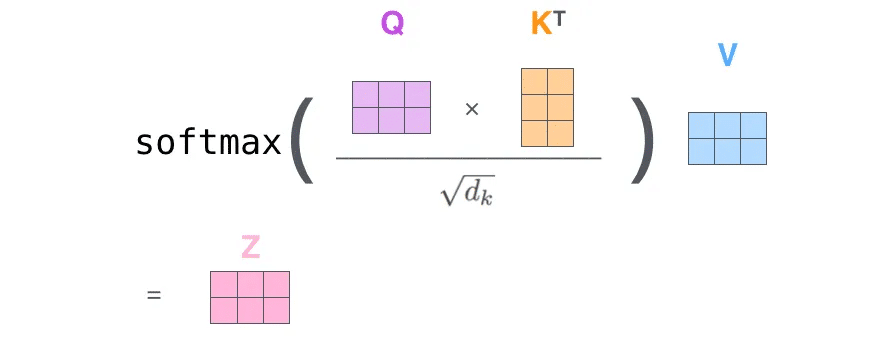
Một từ có thể có nhiều nghĩa và kết nối với các từ khác theo những cách rất đa dạng, do đó mỗi từ có thể có nhiều bộ Q-K-V liên kết với nó. Kiến trúc này có tên gọi là multi-headed attention. Mỗi ma trận self-attention được tính toán riêng rẽ trên toàn bộ câu để học ra những tầng ngữ nghĩa khác nhau trước khi được kết hợp với nhau bởi một ma trận trọng số.
Lời kết
Hi vọng thông qua bài viết này, các bạn đã hiểu thêm về kỹ thuật Attention, đây là một kỹ thuật quan trọng trong các mô hình Transformer như BERT hay GPT-2. Mặc dù vậy, bên cạnh attention, các mô hình này còn được tích hợp các kỹ thuật cao cấp khác. Xin mời các bạn đón đọc trong các bài viết có liên quan.