

Hình ảnh minh họa: AI Safety và bảo mật đang trở thành mối quan tâm hàng đầu trong ngành công nghệ
Ngày 17 tháng 7 năm 2025, Future of Life Institute đã chính thức công bố AI Safety Index Summer 2025 – một báo cáo đánh giá toàn diện về mức độ an toàn và bảo mật của 7 công ty AI hàng đầu thế giới. Kết quả gây chấn động khi cho thấy ngành công nghệ AI vẫn chưa sẵn sàng cho những mục tiêu tham vọng mà họ đã đề ra, đặc biệt là việc phát triển Trí tuệ nhân tạo tổng quát (AGI) trong thập kỷ tới.
Báo cáo này không chỉ đơn thuần là một bảng xếp hạng, mà còn là lời cảnh báo nghiêm trọng về khoảng cách ngày càng lớn giữa tốc độ phát triển công nghệ AI và khả năng quản lý rủi ro của các công ty. Với việc các mô hình AI ngày càng mạnh mẽ và có khả năng tác động sâu rộng đến xã hội, việc đảm bảo an toàn không còn là lựa chọn mà đã trở thành yêu cầu bắt buộc.
Bảng Xếp Hạng Gây Sốc: Không Công Ty Nào Đạt Điểm Tốt
Kết quả đánh giá của AI Safety Index 2025 cho thấy một thực tế đáng lo ngại: ngay cả những công ty hàng đầu trong lĩnh vực AI cũng chỉ đạt được điểm số ở mức trung bình hoặc thấp hơn. Anthropic dẫn đầu với điểm C+ (2.64/4.0), trong khi DeepSeek và Zhipu AI – hai đại diện từ Trung Quốc – nhận điểm F, cho thấy sự thiếu hụt nghiêm trọng trong các tiêu chuẩn an toàn AI.
Bảng Xếp Hạng Chi Tiết AI Safety Index 2025
| Thứ hạng | Công ty | Điểm tổng thể | Xếp loại | Điểm số (4.0) |
| 1 | Anthropic | C+ | Khá | 2.64 |
| 2 | OpenAI | C | Trung bình | 2.10 |
| 3 | Google DeepMind | C- | Trung bình yếu | 1.76 |
| 4 | x.AI | D | Yếu | 1.23 |
| 5 | Meta | D | Yếu | 1.06 |
| 6 | Zhipu AI | F | Thất bại | 0.62 |
| 7 | DeepSeek | F | Thất bại | 0.37 |
Điều đáng chú ý là không một công ty nào đạt được điểm A hoặc B, cho thấy toàn bộ ngành công nghiệp AI đang gặp khó khăn nghiêm trọng trong việc đảm bảo an toàn. Khoảng cách điểm số giữa Anthropic (2.64) và DeepSeek (0.37) lên đến 2.27 điểm, phản ánh sự chênh lệch lớn về cam kết và năng lực trong việc phát triển AI an toàn.
Anthropic Dẫn Đầu Nhờ Cam Kết Mạnh Mẽ Với An Toàn AI
Anthropic giành vị trí đầu tiên không phải ngẫu nhiên. Công ty này đã thể hiện sự dẫn đầu trong nhiều lĩnh vực quan trọng của an toàn AI. Đặc biệt, Anthropic là công ty duy nhất thực hiện các thử nghiệm rủi ro sinh học (bio-risk trials) với sự tham gia của con người, một bước tiến quan trọng trong việc đánh giá tác động thực tế của các mô hình AI đối với an toàn sinh học.
Về bảo vệ quyền riêng tư, Anthropic đã thiết lập tiêu chuẩn vàng trong ngành bằng cách cam kết không sử dụng dữ liệu người dùng để huấn luyện mô hình. Chính sách này không chỉ bảo vệ quyền riêng tư của người dùng mà còn giảm thiểu rủi ro rò rỉ thông tin cá nhân thông qua các phản hồi của AI.
Nghiên cứu về alignment – việc đảm bảo AI hoạt động theo ý định của con người – của Anthropic được đánh giá là hàng đầu thế giới. Công ty đã đầu tư mạnh mẽ vào việc phát triển các kỹ thuật Constitutional AI, giúp mô hình AI học cách tuân thủ các nguyên tắc đạo đức và an toàn một cách tự nhiên.
Cấu trúc tổ chức của Anthropic cũng góp phần vào thành công này. Với tư cách là một Public Benefit Corporation, công ty có nghĩa vụ pháp lý phải cân bằng giữa lợi nhuận và lợi ích công cộng, tạo ra động lực mạnh mẽ để ưu tiên an toàn hơn là chỉ tập trung vào hiệu suất.
OpenAI Đứng Thứ Hai Với Những Điểm Sáng Đáng Chú Ý
OpenAI giành vị trí thứ hai trong bảng xếp hạng với điểm C (2.10), thể hiện những nỗ lực đáng kể trong việc cải thiện tính minh bạch và quản lý rủi ro. Một trong những điểm nổi bật nhất của OpenAI là việc trở thành công ty duy nhất công bố đầy đủ chính sách whistleblowing – cơ chế cho phép nhân viên báo cáo các vấn đề an toàn mà không sợ bị trả thù.
Tuy nhiên, việc công bố này chỉ diễn ra sau khi các phương tiện truyền thông tiết lộ những điều khoản hạn chế nghiêm ngặt trong chính sách ban đầu, cho thấy tầm quan trọng của giám sát bên ngoài trong việc thúc đẩy tính minh bạch.
OpenAI cũng được đánh giá cao về khung quản lý rủi ro mạnh mẽ, đặc biệt là việc đánh giá rủi ro trên các mô hình pre-mitigation – tức là trước khi áp dụng các biện pháp giảm thiểu rủi ro. Cách tiếp cận này cho phép hiểu rõ hơn về khả năng nguy hiểm tiềm ẩn của mô hình trước khi triển khai.
Công ty cũng chia sẻ nhiều chi tiết về các đánh giá mô hình bên ngoài và cung cấp thông số kỹ thuật chi tiết về mô hình, giúp cộng đồng nghiên cứu có thể hiểu và đánh giá tốt hơn về khả năng và rủi ro của các hệ thống AI.
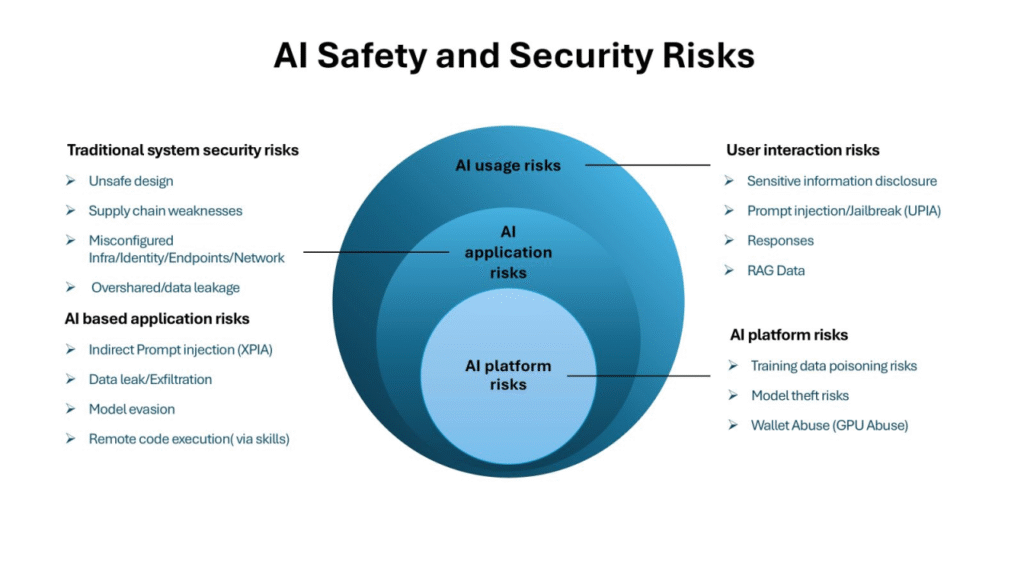
Hình ảnh: Bản đồ rủi ro an toàn và bảo mật AI cho thấy sự phức tạp của các thách thức hiện tại
Google DeepMind: Tiềm Năng Lớn Nhưng Chưa Phát Huy Hết
Google DeepMind đứng ở vị trí thứ ba với điểm C- (1.76), một kết quả có phần bất ngờ đối với một trong những tên tuổi lớn nhất trong lĩnh vực AI. Mặc dù có nguồn lực khổng lồ và đội ngũ nghiên cứu hàng đầu thế giới, DeepMind vẫn chưa thể hiện được cam kết mạnh mẽ với an toàn AI như mong đợi.
Công ty này thuộc nhóm ba công ty duy nhất (cùng với Anthropic và OpenAI) thực hiện kiểm tra các khả năng nguy hiểm liên quan đến rủi ro quy mô lớn như khủng bố sinh học và mạng. Tuy nhiên, các chuyên gia đánh giá cho rằng phương pháp kiểm tra của DeepMind vẫn thiếu những tiêu chuẩn cơ bản trong đánh giá rủi ro.
Một trong những điểm yếu được chỉ ra là việc thiếu phương pháp luận rõ ràng liên kết giữa các thử nghiệm cụ thể với các rủi ro được xác định. Điều này làm giảm độ tin cậy trong việc phát hiện kịp thời các khả năng nguy hiểm trước khi chúng gây ra tác hại nghiêm trọng.
x.AI và Meta: Những Gã Khổng Lồ Công Nghệ Với Điểm Số Đáng Thất Vọng
x.AI của Elon Musk và Meta (Facebook) đều nhận điểm D, phản ánh những thiếu hụt nghiêm trọng trong cam kết với an toàn AI. Điều này đặc biệt đáng lo ngại khi xét đến quy mô ảnh hưởng và nguồn lực khổng lồ của hai công ty này.
x.AI, mặc dù được thành lập với tuyên bố mục tiêu “hiểu thực tế của vũ trụ”, lại thể hiện sự thiếu nhất quán trong việc áp dụng các biện pháp an toàn. Các nhà nghiên cứu từ OpenAI và Anthropic thậm chí đã công khai chỉ trích văn hóa an toàn “liều lĩnh” tại x.AI, cho rằng công ty đang đặt tốc độ phát triển lên trên an toàn.
Meta, với hàng tỷ người dùng trên các nền tảng mạng xã hội, việc nhận điểm D trong an toàn AI là một tín hiệu cảnh báo nghiêm trọng. Công ty này đã nhiều lần bị chỉ trích về việc xử lý thông tin sai lệch và nội dung có hại trên các nền tảng của mình, và kết quả này cho thấy những vấn đề tương tự có thể xuất hiện trong các sản phẩm AI.
Thất Bại Hoàn Toàn Của Các Công Ty AI Trung Quốc
Kết quả gây sốc nhất trong báo cáo là việc cả DeepSeek (0.37 điểm) và Zhipu AI (0.62 điểm) đều nhận điểm F – mức thất bại hoàn toàn. Tuy nhiên, cần lưu ý rằng kết quả này phần lớn phản ánh sự khác biệt về văn hóa doanh nghiệp và khung pháp lý giữa Trung Quốc và phương Tây.
Báo cáo đánh giá các công ty dựa trên các tiêu chuẩn như tự quản trị và chia sẻ thông tin – những yếu tố ít được ưu tiên trong văn hóa doanh nghiệp Trung Quốc. Hơn nữa, Trung Quốc đã có các quy định chính thức cho việc phát triển AI tiên tiến, khác với Mỹ và Anh nơi các công ty chủ yếu dựa vào cam kết tự nguyện.
Điều này không có nghĩa là các công ty Trung Quốc kém an toàn hơn về mặt kỹ thuật, mà chỉ ra rằng họ hoạt động trong một hệ thống quản lý khác biệt. Tuy nhiên, việc thiếu minh bạch và chia sẻ thông tin vẫn là một mối quan ngại lớn đối với cộng đồng AI toàn cầu.
Sáu Lĩnh Vực Đánh Giá: Cái Nhìn Toàn Diện Về An Toàn AI
AI Safety Index 2025 đánh giá các công ty dựa trên sáu lĩnh vực cốt lõi, mỗi lĩnh vực bao gồm nhiều chỉ số cụ thể để đo lường mức độ cam kết và hiệu quả trong việc đảm bảo an toàn AI:
1. Đánh Giá Rủi Ro (Risk Assessment) – 6 Chỉ Số
Lĩnh vực này tập trung vào khả năng của các công ty trong việc xác định và đánh giá các rủi ro tiềm ẩn từ các mô hình AI. Bao gồm cả kiểm tra nội bộ và bên ngoài, đánh giá khả năng nguy hiểm, và các thử nghiệm với sự tham gia của con người. Anthropic dẫn đầu trong lĩnh vực này nhờ các thử nghiệm bio-risk đột phá.
2. Tác Hại Hiện Tại (Current Harms) – 8 Chỉ Số
Đây là lĩnh vực có nhiều chỉ số nhất, đánh giá khả năng của các mô hình trong việc xử lý các vấn đề an toàn hiện tại như thông tin sai lệch, nội dung có hại, và bảo vệ quyền riêng tư. Các benchmark như Stanford HELM và TrustLLM được sử dụng để đánh giá khách quan.
3. Khung An Toàn (Safety Frameworks) – 4 Chỉ Số
Lĩnh vực này xem xét các chính sách, quy trình và cam kết của công ty đối với an toàn AI. OpenAI được đánh giá cao trong lĩnh vực này nhờ khung quản lý rủi ro mạnh mẽ và chính sách whistleblowing minh bạch.
4. An Toàn Hiện Sinh (Existential Safety) – 4 Chỉ Số
Đây là lĩnh vực quan trọng nhất và cũng là nơi tất cả các công ty đều thất bại. Không công ty nào đạt điểm trên D trong lĩnh vực này, cho thấy sự thiếu chuẩn bị nghiêm trọng cho các rủi ro hiện sinh từ AI.
5. Quản Trị và Trách Nhiệm (Governance & Accountability) – 5 Chỉ Số
Lĩnh vực này đánh giá cấu trúc tổ chức, quy trình ra quyết định và cơ chế giám sát của các công ty. Anthropic có lợi thế nhờ cấu trúc Public Benefit Corporation.
6. Chia Sẻ Thông Tin (Information Sharing) – 6 Chỉ Số
Đánh giá mức độ minh bạch và sẵn sàng chia sẻ thông tin về nghiên cứu, rủi ro và các biện pháp an toàn với cộng đồng. Đây là lĩnh vực mà các công ty phương Tây có lợi thế rõ rệt so với các đối thủ Trung Quốc.
Những Phát Hiện Đáng Báo Động Từ Báo Cáo
Ngành Công Nghiệp Chưa Sẵn Sàng Cho AGI
Phát hiện quan trọng nhất và cũng đáng lo ngại nhất từ báo cáo là sự mâu thuẫn giữa tham vọng và thực tế. Các công ty AI hàng đầu đều tuyên bố sẽ đạt được Trí tuệ nhân tạo tổng quát (AGI) trong thập kỷ tới, nhưng không một công ty nào đạt điểm trên D trong lĩnh vực An toàn Hiện sinh.
Một chuyên gia đánh giá đã gọi sự mâu thuẫn này là “cực kỳ đáng lo ngại”, lưu ý rằng mặc dù đang chạy đua hướng tới AI cấp độ con người, “không công ty nào có bất cứ thứ gì giống như một kế hoạch nhất quán, khả thi” để đảm bảo các hệ thống như vậy vẫn an toàn và có thể kiểm soát được.
Thiếu Hụt Nghiêm Trọng Trong Kiểm Tra Khả Năng Nguy Hiểm
Chỉ có 3 trong 7 công ty được đánh giá (Anthropic, OpenAI và Google DeepMind) báo cáo việc thực hiện kiểm tra đáng kể các khả năng nguy hiểm liên quan đến rủi ro quy mô lớn như khủng bố sinh học hoặc mạng. Điều này có nghĩa là hơn một nửa các công ty AI hàng đầu không có cơ chế đánh giá thích hợp cho những rủi ro có thể gây tác hại nghiêm trọng đến xã hội.
Thậm chí đối với ba công ty có thực hiện kiểm tra, các chuyên gia vẫn cảnh báo rằng các phương pháp đánh giá hiện tại vẫn thiếu các tiêu chuẩn cơ bản. Một chuyên gia nhận xét: “Phương pháp luận/lý luận liên kết rõ ràng một quy trình đánh giá hoặc thử nghiệm cụ thể với rủi ro, cùng với các hạn chế và điều kiện, thường bị thiếu vắng. Tôi có độ tin cậy rất thấp rằng các khả năng nguy hiểm đang được phát hiện kịp thời để ngăn chặn tác hại đáng kể.”
Khoảng Cách Ngày Càng Lớn Giữa Các Công Ty
Một xu hướng đáng lo ngại khác được báo cáo chỉ ra là khoảng cách ngày càng lớn giữa các công ty trong việc áp dụng các biện pháp an toàn. Trong khi một số công ty có động lực mạnh mẽ áp dụng các kiểm soát mạnh mẽ hơn, những công ty khác lại bỏ qua các biện pháp bảo vệ cơ bản.
Điều này làm nổi bật sự không đầy đủ của các cam kết tự nguyện và nhu cầu cấp thiết về một khung quy định chung. Khi không có “sàn quy định” chung, các công ty ít có trách nhiệm có thể tạo ra lợi thế cạnh tranh không công bằng bằng cách bỏ qua các biện pháp an toàn tốn kém.
Hội Đồng Chuyên Gia Uy Tín Thực Hiện Đánh Giá
AI Safety Index 2025 được thực hiện bởi một hội đồng gồm sáu chuyên gia hàng đầu trong lĩnh vực AI và an toàn AI, đảm bảo tính khách quan và chuyên môn cao của báo cáo:
Dylan Hadfield-Menell từ MIT, người dẫn đầu Algorithmic Alignment Group và là Schmidt Sciences AI2050 Early Career Fellow, chuyên về triển khai AI an toàn và đáng tin cậy.
Tegan Maharaj từ HEC Montréal, người dẫn đầu phòng thí nghiệm ERRATA về Rủi ro Sinh thái và AI Có trách nhiệm, đồng thời là thành viên học thuật cốt lõi tại Mila.
Jessica Newman, Giám đốc sáng lập của AI Security Initiative tại UC Berkeley và là chuyên gia trong OECD Expert Group on AI Risk and Accountability.
Sneha Revanur, người sáng lập và chủ tịch của Encode – tổ chức toàn cầu do giới trẻ dẫn đầu vận động cho quy định đạo đức của AI, được TIME vinh danh trong danh sách 100 người có ảnh hưởng nhất trong AI.
Stuart Russell từ UC Berkeley, tác giả của sách giáo khoa AI tiêu chuẩn được sử dụng tại hơn 1500 trường đại học trong 135 quốc gia, và là người nhận giải thưởng OBE từ Nữ hoàng Elizabeth II.
David Krueger từ University of Montreal, nhà nghiên cứu tại Mila và Center for Human-Compatible AI, tập trung vào giảm thiểu rủi ro tuyệt chủng của con người từ trí tuệ nhân tạo.
Sự đa dạng về chuyên môn và kinh nghiệm của hội đồng này đảm bảo rằng đánh giá được thực hiện từ nhiều góc độ khác nhau, từ kỹ thuật thuần túy đến chính sách công và đạo đức AI.
Ý Nghĩa Sâu Rộng Của AI Safety Index 2025
Cảnh Báo Về Cuộc Đua AI Thiếu Kiểm Soát
Báo cáo AI Safety Index 2025 không chỉ đơn thuần là một bảng xếp hạng mà còn là lời cảnh báo nghiêm trọng về tình trạng hiện tại của ngành công nghiệp AI. Việc không có công ty nào đạt điểm tốt cho thấy rằng cuộc đua phát triển AI đang diễn ra nhanh hơn khả năng đảm bảo an toàn.
Điều này đặc biệt đáng lo ngại khi xét đến tốc độ phát triển exponential của công nghệ AI. Các mô hình AI ngày càng mạnh mẽ được phát hành với tần suất ngày càng cao, nhưng các biện pháp an toàn và kiểm soát không theo kịp tốc độ này.
Nhu Cầu Cấp Thiết Về Quy Định Toàn Cầu
Kết quả của báo cáo làm nổi bật nhu cầu cấp thiết về một khung quy định toàn cầu cho AI. Việc dựa vào các cam kết tự nguyện của các công ty đã chứng minh là không đủ để đảm bảo an toàn. Sự chênh lệch lớn trong điểm số giữa các công ty cho thấy rằng không có “sàn” chung về tiêu chuẩn an toàn.
Các quốc gia và tổ chức quốc tế cần phối hợp để xây dựng các tiêu chuẩn an toàn AI có tính ràng buộc pháp lý, đảm bảo rằng tất cả các công ty phát triển AI đều phải tuân thủ các biện pháp an toàn tối thiểu.
Tầm Quan Trọng Của Minh Bạch và Giám Sát
Báo cáo cũng nhấn mạnh tầm quan trọng của minh bạch và giám sát bên ngoài. Việc OpenAI chỉ công bố chính sách whistleblowing sau khi bị phương tiện truyền thông tiết lộ cho thấy rằng áp lực từ bên ngoài là cần thiết để thúc đẩy tính minh bạch.
Cộng đồng nghiên cứu, phương tiện truyền thông và xã hội dân sự đóng vai trò quan trọng trong việc giám sát và đánh giá các công ty AI. Các báo cáo như AI Safety Index cung cấp công cụ quan trọng để theo dõi tiến bộ và gây áp lực cho các công ty cải thiện.
Hướng Đi Trong Tương Lai: Những Bài Học Từ AI Safety Index 2025
Cần Có Cách Tiếp Cận Toàn Diện
Kết quả của AI Safety Index 2025 cho thấy rằng an toàn AI không thể được đảm bảo thông qua một yếu tố đơn lẻ. Cần có cách tiếp cận toàn diện bao gồm nghiên cứu kỹ thuật, chính sách tổ chức, minh bạch, và hợp tác quốc tế.
Các công ty cần đầu tư không chỉ vào việc cải thiện hiệu suất mô hình mà còn vào việc phát triển các công cụ đánh giá rủi ro, thiết lập quy trình quản trị mạnh mẽ, và xây dựng văn hóa ưu tiên an toàn.
Học Hỏi Từ Những Người Dẫn Đầu
Thành công của Anthropic trong việc dẫn đầu bảng xếp hạng cung cấp những bài học quý giá cho toàn ngành. Việc kết hợp nghiên cứu kỹ thuật tiên tiến với cấu trúc tổ chức ưu tiên lợi ích công cộng đã tạo ra một mô hình có thể được các công ty khác học hỏi.
OpenAI cũng cho thấy rằng minh bạch và sẵn sàng chia sẻ thông tin có thể cải thiện đáng kể điểm số an toàn mà không nhất thiết phải hy sinh lợi thế cạnh tranh.
Vai Trò Của Cộng Đồng Quốc Tế
Sự khác biệt trong điểm số giữa các công ty phương Tây và Trung Quốc nhấn mạnh tầm quan trọng của hợp tác quốc tế trong việc xây dựng các tiêu chuẩn an toàn AI chung. Cần có đối thoại và hợp tác giữa các quốc gia để đảm bảo rằng an toàn AI không bị ảnh hưởng bởi các khác biệt về văn hóa hoặc hệ thống chính trị.
Kết Luận: Lời Cảnh Báo Và Hy Vọng
AI Safety Index 2025 của Future of Life Institute đã cung cấp một bức tranh rõ ràng và đáng lo ngại về tình trạng an toàn AI hiện tại. Việc không có công ty nào đạt điểm tốt, đặc biệt là thất bại hoàn toàn trong lĩnh vực An toàn Hiện sinh, là một lời cảnh báo nghiêm trọng cho toàn ngành công nghiệp.
Tuy nhiên, báo cáo cũng cho thấy rằng có những công ty đang dẫn đầu trong việc ưu tiên an toàn AI. Thành công của Anthropic chứng minh rằng có thể kết hợp đổi mới kỹ thuật với cam kết mạnh mẽ đối với an toàn. OpenAI cũng cho thấy rằng minh bạch và sẵn sàng chia sẻ thông tin có thể cải thiện đáng kể mức độ an toàn.
Quan trọng nhất, báo cáo này nhấn mạnh rằng an toàn AI không phải là trách nhiệm của riêng các công ty công nghệ. Cần có sự tham gia của toàn xã hội – từ các nhà hoạch định chính sách, nhà nghiên cứu, phương tiện truyền thông đến công chúng – để đảm bảo rằng AI phát triển theo hướng có lợi cho nhân loại.
Khi chúng ta đứng trước ngưỡng cửa của kỷ nguyên AGI, AI Safety Index 2025 nhắc nhở chúng ta rằng tốc độ không phải là tất cả. An toàn, minh bạch và trách nhiệm phải được đặt lên hàng đầu nếu chúng ta muốn AI thực sự phục vụ cho lợi ích của nhân loại.