")
Trong phần trước, chúng ta đã cùng nhau tìm hiểu sơ bộ về TensorFlow.js cùng như cài đặt môi trường, nạp dư liệu cho nhiệm vụ nhận dạng chữ số viết tay. Phần này, hãy cùng nhau thiết lập kiến trúc của mô hình, huấn luyện và đánh giá nó.
Lưu ý: Chúng ta sẽ huấn luyện và đánh giá mô hình sử dụng tài nguyên trên trình duyệt của bạn (tài nguyên của máy tính bạn). Nên bạn hãy đảm bảo tắt các chương trình không cần thiết để máy tính không bị treo.
4. Thiết lập kiến trúc mô hình
Trong phần này, chúng ta sẽ viết code để thiết lập kiến trúc của mô hình. Kiến trúc mô hình là cụm từ hào nhoáng cho “các hàm nào mô hình sẽ thực hiện khi ta chạy nó”, hoặc là “thuật toán nào mô hình sử dụng để có được kết quả”.
Trong học máy, chúng ta thiết lập kiến trúc (hay thuật toán) và mô hình sẽ học ra các tham số thông qua quá trình huấn luyện.
Chèn thêm hàm dưới đây vào file script.js để định nghĩa kiến trúc của mô hình.
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
Giờ ta hãy cùng phân tích các chi tiết. Đầu tiên, mô hình chứa lớp convolution và max pooling (tf.layers.conv2d, tf.layers. maxPooling2d) với inputShape là định dạng đầu vào của các ảnh [28, 28 ,1]. Sau đó, trước khi truyền qua lớp thực hiện phân loại tf.layers.dense, dữ liệu cần được duỗi phẳng với tf.layers.flatten.
Với dense layer và hàm kích hoạt softmax, phân bố xác suất trên 10 phân lớp được tính toán. Phân lớp với giá trị cao nhất sẽ là chữ số được dự đoán. Đó là lý do chúng ta cần 10 phần tử trong lớp đầu ra. Hàm loss ta sử dụng là cross-entropy (categoricalCrossentropy). Đầu ra được mã hóa dạng one-hot và thước đo cho mô hình là accuracy.
5. Huấn luyện mô hình
Copy đoạn mã sau vào file script.js của bạn
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
Thêm đoạn mã sau vào hàm run() để bắt đầu huấn luyện
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture'}, model);
await train(model, data);
Tải lại trang và sau vài giây, bạn sẽ thấy các đồ thị báo cáo quá trình huấn luyện.
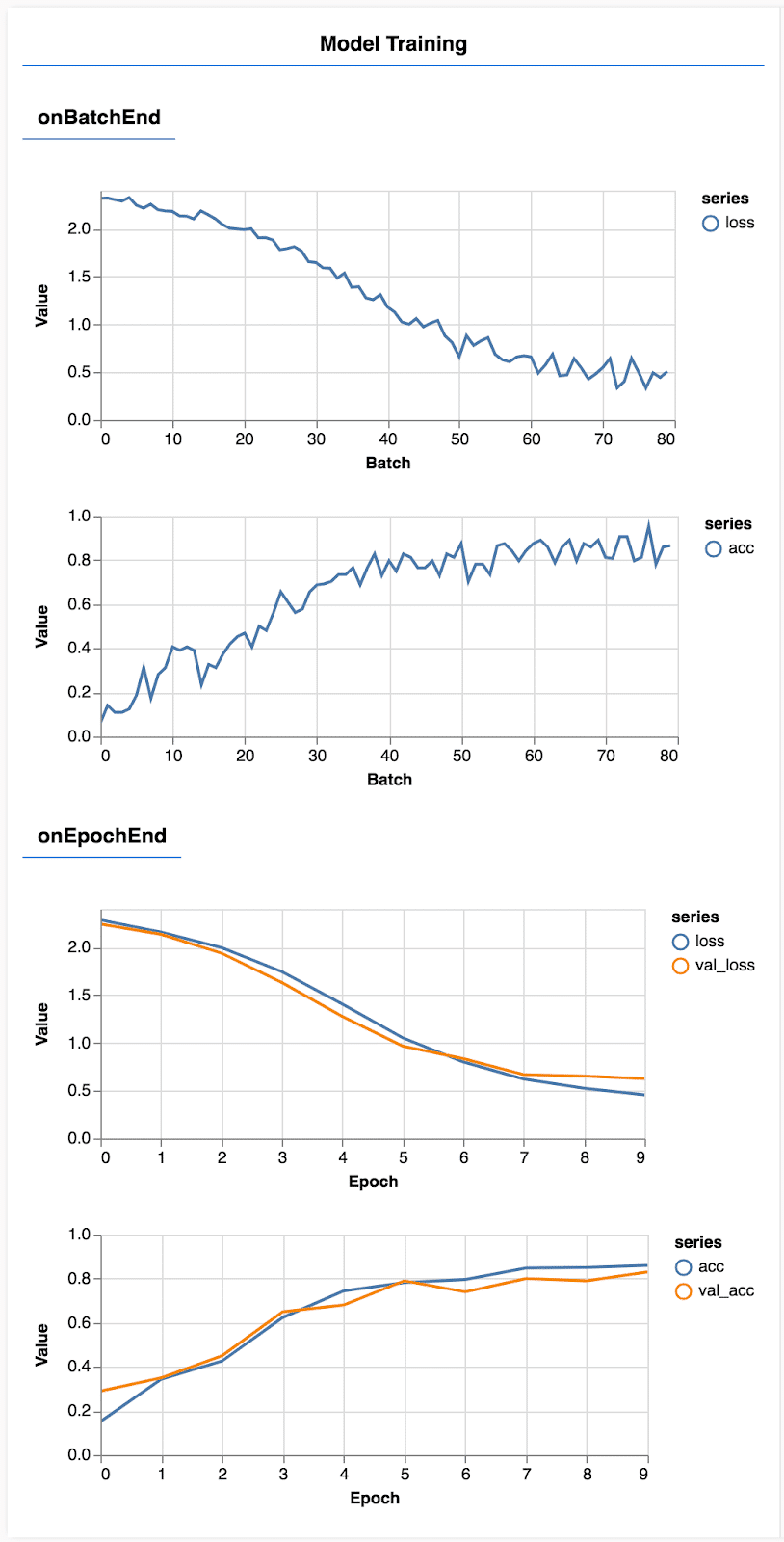
Ta định nghĩa các thông số được sử dụng để theo dõi quá trình huấn luyện ['loss', 'val_loss', 'acc', 'val_acc'] nó bao gồm độ accuracy và loss của cả tập huấn luyện và tập xác nhận. Tập huấn luyện được sử dụng để huấn luyện mô hình, tập xác nhận để theo dõi hiệu quả của mô hình sau mỗi epoch. Nếu mô hình hoạt động tốt trên tập huấn luyện nhưng không tốt trên tập xác nhận, khả năng cao mô hình đã bị overfitting.
6. Đánh giá Mô hình
Accuracy trên tập xác nhận đánh giá xem mô hình của chúng ta hoạt động tốt ra sao với dữ liệu mà nó chưa được chứng kiến. Mặc dù vậy, ta có thể xem xét một cách chi tiết hiệu quả của mô hình trên từng phân lớp. Có một vài phương thức trong tfjs-vis có thể giúp ta làm điều đó.
Thêm đoạn mã sau vào file script.js của bạn
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax([-1]);
const preds = model.predict(testxs).argMax([-1]);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(
container, {values: confusionMatrix}, classNames);
labels.dispose();
}
Đoạn mã này làm những gì?
- Đưa ra dự đoán
- Tính toán accuracy
- Hiển thị các thông số
Đầu tiên là đưa ra dự đoán. Mô hình nhận vào 500 bức ảnh và dự đoán chữ số tương ứng với từng bức ảnh. Hàm argmax cho ta chỉ số của phân lớp có xác suất cao nhất. Về mặt tính toán, việc véc tơ hóa giúp cho chúng ta có thể dự đoán 500 mẫu cùng một lúc. Đây là ưu điểm của việc sử dụng các framework như TensorFlow thay vì tự code từ đầu. Tiếp theo chúng ta hiển thị accuracy cho từng phân lớp và confusion matrix.
Thêm đoạn mã sau vào hàm run() để bắt đầu huấn luyện
await showAccuracy(model, data); await showConfusion(model, data);
Kết quả sẽ xuất hiện như sau:
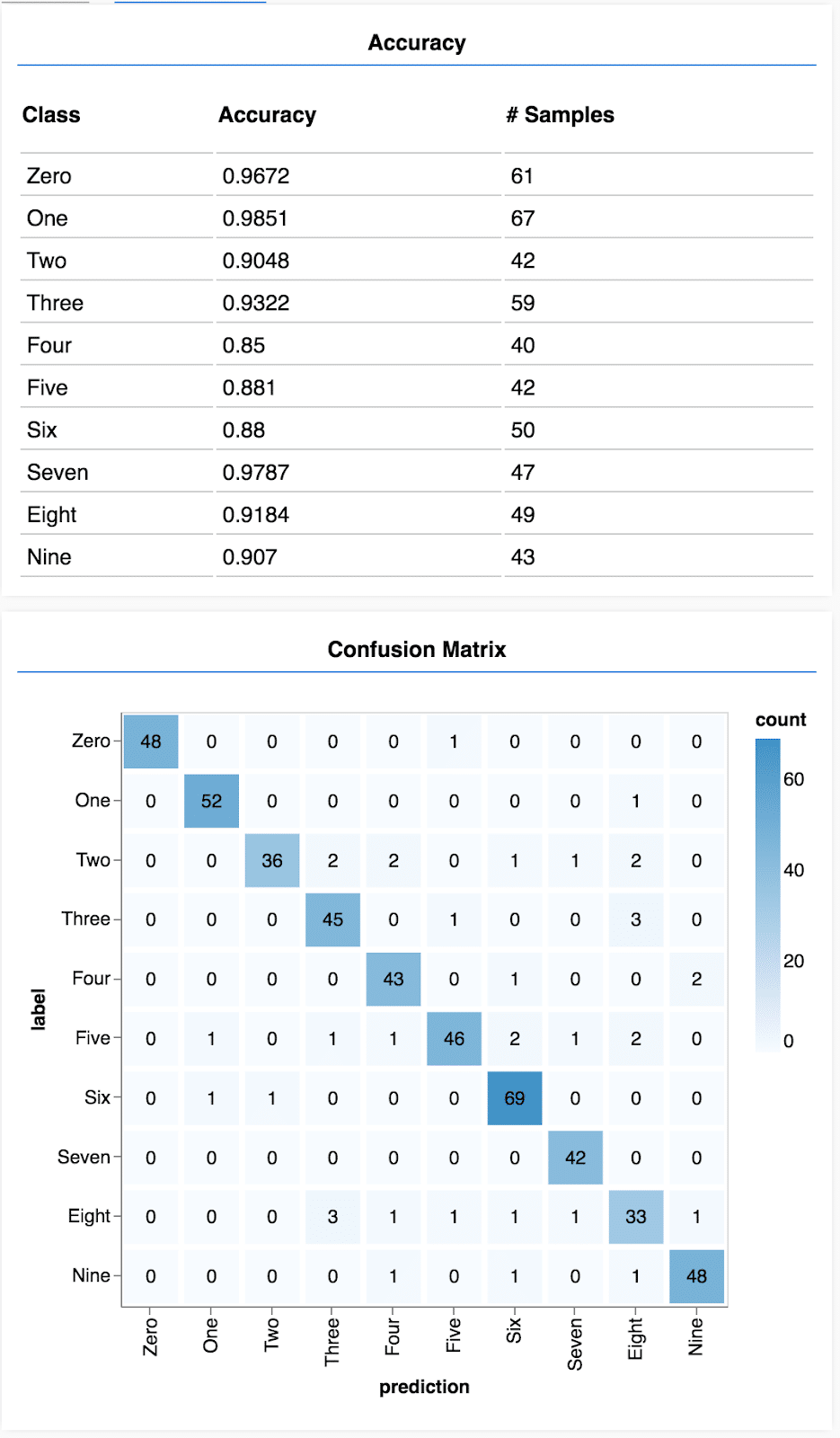
Bạn có thể xem ví dụ hoàn chỉnh tại đây.
Như vậy, thông qua loạt bài hướng dẫn này, chúng ta đã cùng đi qua các bước quan trọng để xây dựng một mô hình Deep learning nhận dạng chữ số viết tay với TensorFlow.js. Nếu bạn thấy bài viết này hữu ích, hãy chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io hoặc đăng ký (dưới chân trang) để nhận được những bài viết mới sớm nhất.