
Mạng nơ ron hay bất kỳ mô hình tính toán nào đều làm việc với các con số. Vậy làm thế nào để các mô hình tính toán có thể làm việc với ngôn ngữ tự nhiên? Chúng ta đều biết từ là đơn vị ngôn ngữ nhỏ nhất mang ý nghĩa hoàn chỉnh. Do đó, để các mô hình làm việc được với ngôn ngữ tự nhiên thì việc số hóa các từ là cách tiếp cận đơn giản nhất. Bài viết này mang đến những giải thích cơ bản, cung cấp cho bạn một ý tưởng chung về Word Embedding và cách nó hoạt động.
Các cách biểu diễn từ
Chúng ta có thể có một vài cách biểu diễn từ như sau:
- Biểu diễn mỗi từ bằng một con số: Đây là cách đơn giản nhất, tuy nhiên, nó có thể làm sai lệch mối quan hệ ngữ nghĩa giữa các từ. Nếu bạn biểu diễn “mèo” là số 1 và “chó” là số 2. Như vậy, ở một khía cạnh nào đó ta có: “mèo”+”mèo”=”chó”, “chó” > “mèo”. Nghĩ xa hơn, câu chuyện “mèo lại hoàn mèo” đúng là một ca khó cho cách biểu diễn này.
- Sử dụng “one-hot vector”: Đây là vector có số chiều bằng số từ vựng. Vector này có duy nhất một chiều có giá trị bằng 1 ứng với từ đang biểu diễn, các vị trí khác có giá trị 0. Ví dụ [1,0,0,0…0]. Biểu diễn này giải quyết được mẫu thuẫn tiềm năng của biểu diễn bằng số. Tuy nhiên, nhược điểm của phương pháp này là số chiều vector rất lớn, ảnh hưởng đến quá trình xử lý cũng như lưu trữ.
- Sử dụng vector ngẫu nhiên: Với cách này, mỗi từ được biểu thị bằng một vector có giá trị của các chiều là ngẫu nhiên. Do đó, số lượng chiều chúng ta cần sử dụng ít hơn nhiều so với sử dụng one-hot. Ví dụ: nếu bạn có 1 triệu từ, bạn có thể biểu thị tất cả các từ đó trong không gian 3D, mỗi từ là một điểm trong không gian 3 chiều.
- Sử dụng Word embedding: Đây được coi là cách tốt nhất để thể hiện các từ trong văn bản. Kỹ thuật này cũng gán mỗi từ với một vector, nhưng ưu việt hơn kỹ thuật vector ngẫu nhiên vì các vector này được tính toán để biểu diễn quan hệ tương đồng giữa các từ.
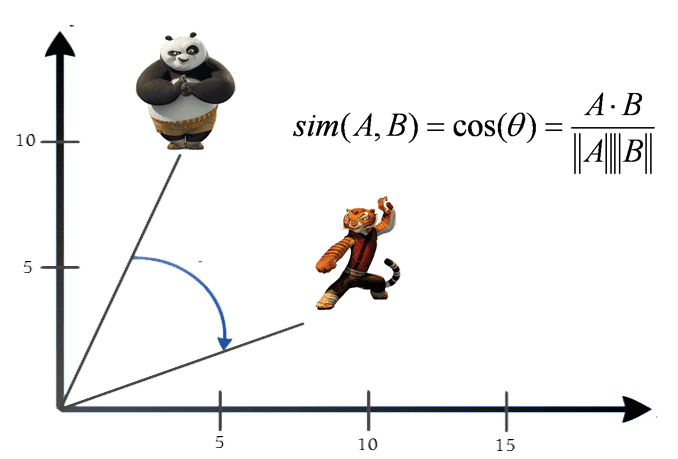
Phương pháp tạo word embedding
Các phương pháp tạo ra Word embedding được gọi chung là Word2Vec. Biểu diễn vector của từ có thể thu được bằng hai phương pháp phổ biến (cả hai đều liên quan đến Mạng nơ-ron): Skip Gram và Continuous Bag of Word (CBOW).
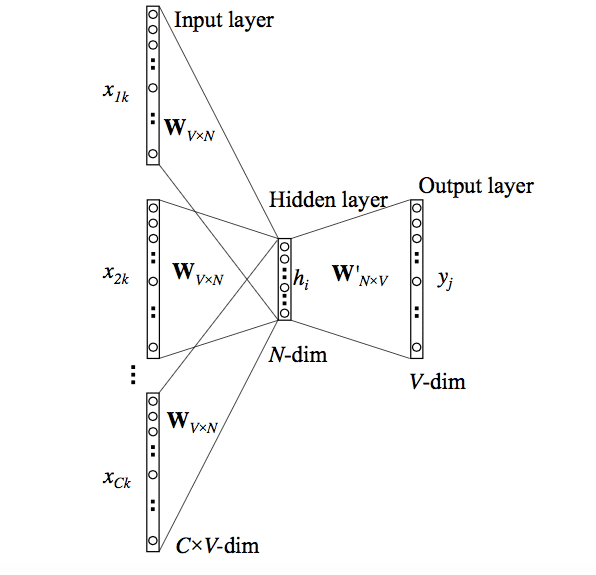
Mô hình CBOW
Phương pháp này lấy ngữ cảnh của mỗi từ làm đầu vào và cố gắng dự đoán từ tương ứng với ngữ cảnh. Hãy xem xét ví dụ: Hôm nay tôi đi học.
Chúng ta sẽ cố gắng dự đoán từ mục tiêu (đi) bằng cách sử dụng duy nhất một từ ngữ cảnh đầu vào (học). Cụ thể hơn, chúng tôi sử dụng mã hóa one-hot của từ đầu vào và đo lỗi đầu ra của mạng nơ ron đối với mã hóa one-hot của từ mục tiêu (đi).
Ngoài ra, chúng ta có thể xây dựng các kiến trúc dự đoán một từ bằng nhiều từ xung quanh. Trong quá trình dự đoán từ mục tiêu, mô hình sẽ học được biểu diễn vectơ của từ mục tiêu.
Mô hình Skip Gram
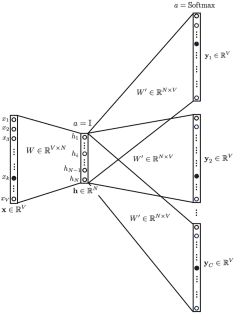
Mô hình Skip Gram còn được coi là phiên bản đảo ngược của mô hình CBOW. Cho trước một vị trí ngữ cảnh, mô hình cần đưa ra được phân bố xác suất của mỗi từ ở vị trí đó. Trong cả hai trường hợp, mạng sử dụng lan truyền ngược để học ra biểu diễn vector của từ.
Theo Mikolov, tác giả của word2vec, cả hai phương pháp đều có những ưu điểm và nhược điểm riêng. Skip Gram hoạt động tốt với lượng dữ liệu nhỏ và hoạt động được với tập từ vựng có chứa các từ hiếm. Mặt khác, CBOW có thể học trong thời gian ngắn và cho ra các biểu diễn tốt hơn cho các từ thông dụng.