VAE là phiên bản nâng cấp của bộ tự mã hóa Auto Encoder, VAE giúp tự động lựa chọn đặc trưng một cách chính xác thông qua quá trình học không giám sát. Vậy cụ thể VAE hoạt động như thế nào, hãy cùng trituenhantao.io tìm hiểu trong bài viết này.
Machine learning giờ đây không chỉ dừng lại với khả năng nhận biết, phân biệt, chúng đã bắt đầu có khả năng sáng tạo. Câu chuyện bắt đầu từ sự trở lại của Deep learning, các mạng nơ ron có khả năng tự động trích chọn và phân tích đặc trưng của dữ liệu, từ những gì học được, chúng bắt đầu có thể sáng tạo nên những thực thể số sống động. Hai dòng thuật toán lớn nhất là GAN và VAE.

Nhược điểm của Auto Encoder
Auto Encoder là một ý tưởng tuyệt vời trong việc trích chọn đặc trưng quan trọng từ dữ liệu. Kiến trúc này tạo ra một nút thắt cổ chai giữa encoder và decoder. Do đó, trên lý thuyết, chỉ những đặc trưng đại diện được giữ lại.
Đó là lý thuyết, còn thực tế thì sao? Auto Encoder được thiết kế để học cách mã hóa và giải mã đầu ra càng giống đầu vào càng tốt, không quan tâm đến phân bố của các đặc trưng ẩn có hợp lý hay không. Điều này khiến cho Auto Encoder bị overfitting và các mẫu sinh ra bất hợp lý. Ví dụ đơn giản, nếu trong tập dữ liệu của bạn có 9 người đàn ông trọc đầu, 1 người phụ nữ tóc dài xinh đẹp thì nhiều khả năng tất cả các mẫu sinh ra đều trọc đầu hoặc với nỗ lực của Auto Encoder bạn sẽ có những tấm hình như sau:

Hoặc nếu may mắn, ta có thể có được bức hình giống như sau (với xác suất cực kỳ nhỏ):

Hai ví dụ trên được lấy ra để bạn dễ hình dung về nhược điểm của Auto Encoder. Trên thực tế, các hình do Auto Encoder sinh ra méo mó và dị dạng hơn nhiều.
Vậy giải pháp là gì? Chúng ta cần một cơ chế để giám sát và điều chỉnh phân bố của các đặc trưng. VAE ra đời để giúp chúng ta làm điều đó.
VAE – Variational Auto Encoder
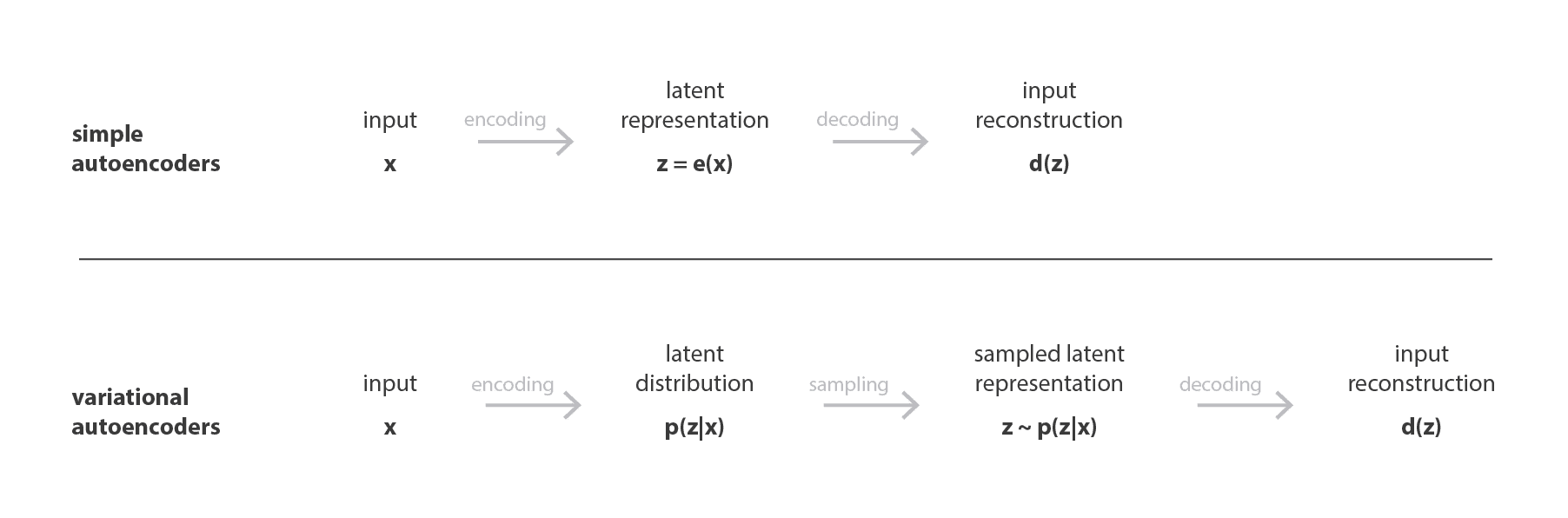
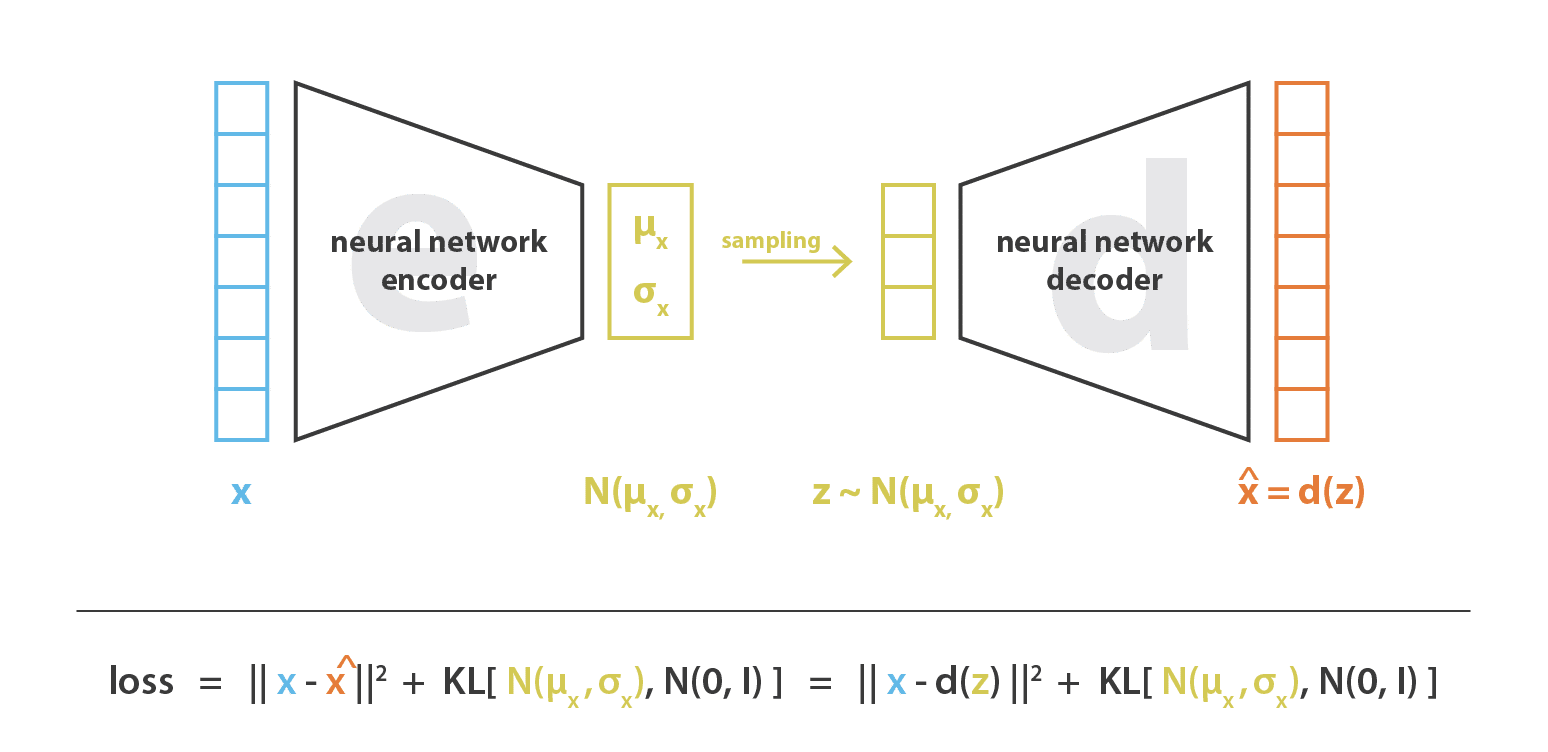
VAE là viết tắt của Variational Auto Encoder, là một Auto Encoder mà quá trình huấn luyện được điều chỉnh để đảm bảo rằng các đặc trưng ẩn đủ tốt phục vụ cho việc sinh dữ liệu.
VAE cũng có một encoder và một decoder, cũng được huấn luyện để tái lập đầu vào thông qua nút thắt cổ chai. Mặc dù vậy, thay vì mã hóa đầu vào như một điểm dữ liệu, ta mã hóa nó như một phân bố xác suất trên không gian ẩn.
Hàm loss trong VAE được cấu tạo bởi hai thành phần, một thành phần để đánh giá khả năng khôi phục đầu vào và một thành phần để giám sát phân bố của lớp ẩn với Kulback-Leibler divergence.
Với cách thiết kế hàm loss như trên, VAE vừa đảm bảo giữ lại được các đặc trưng quan trọng trong giữ liệu, vừa giữ được phân bố của chúng trên thực tế. Hình dưới thể hiện sự khác biệt trong hiệu quả tái lập đầu vào giữa Auto Encoder và VAE.

Nếu bạn thấy bài viết này thú vị, hãy chia sẻ với những người quan tâm. Hãy thường xuyên truy cập và tương tác với chúng tôi qua các kênh (dưới chân trang) để có được thông tin mới nhất về lĩnh vực. Hẹn gặp lại các bạn trong các bài viết sau!