
Hãy cùng tìm hiểu khái niệm quantization với trituenhantao.io, một kỹ thuật quan trọng trong việc tối ưu hóa mô hình ngôn ngữ lớn (LLM) để giảm thiểu yêu cầu về bộ nhớ GPU. Trong bối cảnh ngày càng có nhiều mô hình ngôn ngữ lớn ra đời, việc quản lý và sử dụng hiệu quả tài nguyên phần cứng trở thành một thách thức không nhỏ. Quantization xuất hiện như một giải pháp hữu hiệu, giúp giảm kích thước mô hình mà vẫn duy trì hiệu suất hoạt động ở mức chấp nhận được.
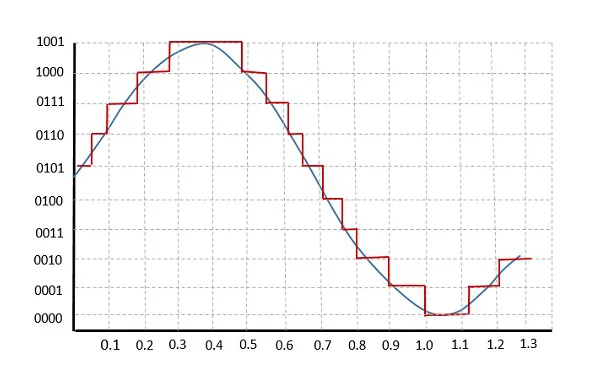
Quantization là gì?
Quantization là quá trình chuyển đổi dữ liệu từ một dạng biểu diễn có độ chính xác cao sang một dạng biểu diễn với ít thông tin hơn. Điều này thường được thực hiện bằng cách giảm số bit cần thiết để lưu trữ trọng số và độ lệch của mô hình. Ví dụ, chuyển từ định dạng 32-bit xuống 16-bit có thể giảm một nửa dung lượng bộ nhớ cần thiết. Điều này đặc biệt hữu ích khi triển khai các mô hình trên phần cứng có giới hạn về tài nguyên như GPU.
Lợi ích của Quantization
- Giảm Dung Lượng Bộ Nhớ: Bằng cách sử dụng ít bit hơn để lưu trữ dữ liệu, quantization giúp giảm đáng kể dung lượng bộ nhớ cần thiết cho mô hình. Một phương pháp phổ biến là sử dụng định dạng 4-bit hoặc 8-bit, có thể làm giảm kích thước mô hình lên đến 4 lần.
- Tăng Tốc Độ Xử Lý: Với ít dữ liệu cần xử lý hơn, các phép toán trên mô hình cũng được thực hiện nhanh hơn, giúp tăng tốc độ xử lý tổng thể của hệ thống.
- Hiệu Quả Chi Phí: Việc giảm yêu cầu về phần cứng cho phép triển khai các mô hình trên các thiết bị rẻ hơn và ít mạnh mẽ hơn, làm cho công nghệ này dễ tiếp cận hơn cho nhiều tổ chức và cá nhân.
Thách Thức và Cân Nhắc
Mặc dù mang lại nhiều lợi ích, quantization cũng đi kèm với một số thách thức:
- Độ Chính Xác: Giảm độ chính xác của dữ liệu có thể dẫn đến mất mát về độ chính xác của mô hình. Tuy nhiên, các kỹ thuật như Quantization Aware Training (QAT) có thể giúp giảm thiểu tác động này bằng cách điều chỉnh mô hình trong quá trình huấn luyện để thích nghi với việc quantize.
- Tương Thích Phần Cứng: Không phải tất cả các loại phần cứng đều hỗ trợ tốt cho mọi kiểu quantization. Do đó, cần cân nhắc kỹ lưỡng khi lựa chọn phương pháp phù hợp với hệ thống của bạn.
Hy vọng thông qua bài viết này, bạn đã có cái nhìn rõ hơn về quantization và cách nó giúp tối ưu hóa việc sử dụng tài nguyên cho các mô hình ngôn ngữ lớn. Mời các bạn thường xuyên ghé thăm trituenhantao.io để cập nhật thêm nhiều kiến thức bổ ích khác!