
Mixture of Experts giúp tối ưu hóa tài nguyên tính toán thông qua việc chia nhỏ mô hình AI thành các mạng con chuyên gia.

Giới thiệu
Trong lĩnh vực học sâu (deep learning), các mô hình neural network, bao gồm cả những mô hình ngôn ngữ lớn, có thể rất lớn, lên đến hàng trăm tỷ tham số. Việc chạy chúng yêu cầu tài nguyên tính toán khổng lồ. Điều này dẫn đến sự xuất hiện của Mixture of Experts (MoE), một cách tiếp cận học máy chia nhỏ mô hình AI thành các mạng con riêng biệt hay “chuyên gia”. Từng chuyên gia này sẽ tập trung vào một phần nhỏ của dữ liệu đầu vào và chỉ các chuyên gia liên quan mới được kích hoạt cho mỗi nhiệm vụ cụ thể.
Mixture of Experts không phải là khái niệm mới. Vào năm 1991, các nhà nghiên cứu đề xuất một hệ thống AI với các mạng riêng biệt chuyên hóa vào các trường hợp huấn luyện khác nhau. Kết quả thử nghiệm của họ cho thấy mô hình đạt được độ chính xác mục tiêu chỉ bằng một nửa số chu kỳ huấn luyện so với mô hình thông thường.
Ngày nay, Mixture of Experts đang trở lại và trở thành xu hướng mới. Các mô hình ngôn ngữ lớn hàng đầu, như những mô hình từ Mistral, đang áp dụng nó. Hãy cùng phân tích kiến trúc của Mixture of Experts này.
Kiến trúc của Mixture of Experts
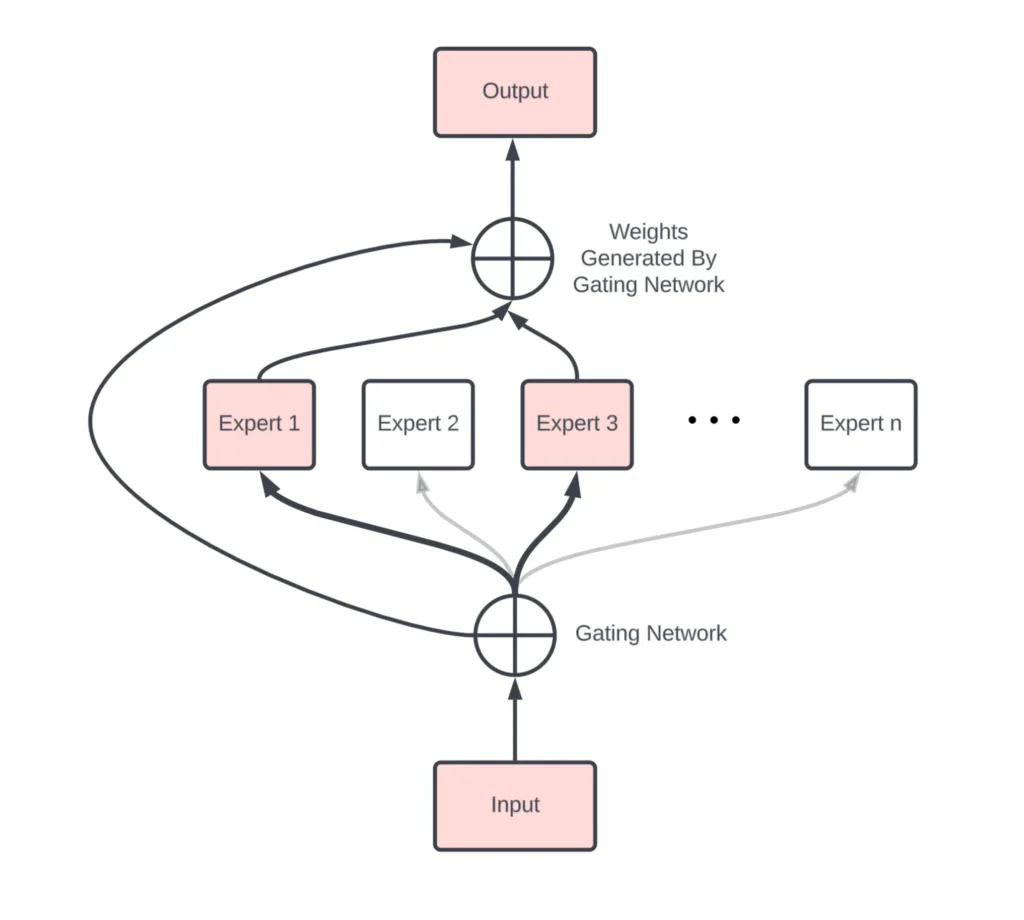
Các Thành Phần Chính
1. Gating Network: Hệ thống phân luồng hoạt động như một cảnh sát giao thông, quyết định chuyên gia nào sẽ xử lý từng nhiệm vụ cụ thể. Hệ thống phân luồng gán các trọng số trong khi thực hiện, kết hợp các kết quả nhận được để tạo ra đầu ra cuối cùng.
2. Expert Network: Các mạng chuyên gia nằm giữa đầu vào và đầu ra. Mỗi mạng chuyên gia có thể có hàng tỷ tham số, giúp xử lý dữ liệu đầu vào một cách hiệu quả.
Mistral Model – Mixtral 8x7B
Mixtral 8x7B là một mô hình ngôn ngữ lớn (LLM) với kiến trúc Mixture of Experts (MoE), được phát triển bởi Mistral AI. Mô hình này nổi bật nhờ sử dụng một kiến trúc chuyên gia thưa (Sparse Mixture of Experts – SMoE), trong đó mỗi lớp bao gồm tám chuyên gia, mỗi chuyên gia có khoảng 7 tỷ tham số. Khi xử lý một token, hệ thống định tuyến của Mixtral chọn ra hai chuyên gia tốt nhất từ tám chuyên gia này để xử lý dữ liệu, điều này giúp tăng hiệu quả tính toán mà không phải đánh đổi quá nhiều về hiệu năng.
Mixtral có tổng cộng 45 tỷ tham số, nhưng nhờ vào kiến trúc SMoE, số lượng tham số hoạt động trong mỗi lần inference chỉ tương đương với một mô hình có 13 tỷ tham số. Điều này giúp Mixtral đạt được hiệu năng vượt trội so với nhiều mô hình lớn hơn, như Llama 2 70B, đặc biệt trong các tác vụ liên quan đến lập trình và toán học.
Bên cạnh hiệu năng cao, Mixtral còn tối ưu về mặt tốc độ với khả năng inference nhanh hơn gấp 6 lần so với Llama 2 70B, trong khi vẫn duy trì chất lượng đầu ra tốt. Điều này làm cho Mixtral trở thành một lựa chọn hấp dẫn cho các ứng dụng yêu cầu xử lý ngôn ngữ tự nhiên với hiệu suất cao nhưng không muốn hy sinh quá nhiều về chi phí tính toán.
Mixtral 8x7B được cung cấp dưới dạng mã nguồn mở với giấy phép Apache 2.0, cho phép các nhà phát triển tự do tùy chỉnh và triển khai theo nhu cầu của họ. Mô hình này đã được sử dụng rộng rãi trong nhiều ứng dụng từ hỗ trợ khách hàng đến tạo văn bản tự động và đặc biệt hiệu quả trong các bài toán phức tạp đòi hỏi khả năng suy luận sâu.
Các Khái Niệm Quan Trọng
1. Sparsity (Tính Thưa Thớt): Trong một lớp thưa thớt, chỉ có các chuyên gia và các tham số của họ được kích hoạt. Cách tiếp cận này giảm yêu cầu về tính toán so với việc gửi yêu cầu qua toàn bộ mạng lưới.
2. Routing (Phân Luồng): Mạng lưới phân luồng dự đoán khả năng mỗi chuyên gia sẽ cho kết quả đầu ra tốt nhất. Mixtral sử dụng chiến lược phân luồng “top-k”, chọn ra hai chuyên gia tốt nhất từ tám chuyên gia cho mỗi tác vụ.
3. Load Balancing (Cân Bằng Tải): Việc phân luồng không đều có thể dẫn đến một số chuyên gia bị chọn ít hoặc nhiều hơn, gây mất cân đối và lãng phí tài nguyên. Để giải quyết điều này, các nhà nghiên cứu phát triển kỹ thuật “noisy top-k gating,” giới thiệu nhiễu Gaussian vào quá trình lựa chọn chuyên gia nhằm thúc đẩy sự kích hoạt đều đặn.
Lời kết
Mixture of Experts mang lại nhiều lợi ích về hiệu suất và hiệu quả tính toán, nhưng cũng đòi hỏi việc huấn luyện phức tạp hơn và yêu cầu giám sát kỹ lưỡng để đảm bảo cân bằng tải và sử dụng tối đa các chuyên gia.
Mixture of Experts là một lựa chọn hấp dẫn cho các ứng dụng lớn, đặc biệt là trong các mô hình ngôn ngữ lớn, nơi tài nguyên tính toán là quý giá. Khám phá và áp dụng MoE có thể giúp tiến xa hơn trong việc tối ưu hóa và tăng cường hiệu năng của các hệ thống AI hiện đại.
Hãy chia sẻ bài viết này và thường xuyên truy cập vào trituenhantao.io cũng như các kênh thông tin của chúng tôi để cập nhật những kiến thức mới nhất về lĩnh vực trí tuệ nhân tạo.