
Minh họa RLHF là bài viết của Lambert Nathan, Castricato Louis, von Werra Leandro và Havrilla Alex trên HuggingFace blog. Bài viết được sửa đổi một phần không đáng kể để phù hợp hơn với độc giả Việt Nam. Bạn có thể đọc bài gốc tiếng Anh tại đây.
Các mô hình ngôn ngữ đã thể hiện những khả năng ấn tượng trong vài năm qua bằng cách tạo văn bản đa dạng và hấp dẫn từ prompt của con người. Tuy nhiên, điều gì tạo nên một văn bản “hay” vốn rất khó xác định vì nó mang tính chủ quan và phụ thuộc vào ngữ cảnh. Có nhiều ứng dụng chẳng hạn như viết truyện mà bạn muốn có sự sáng tạo, các đoạn văn bản cung cấp thông tin phải trung thực hoặc các đoạn mã mà chúng ta muốn chúng có thể thực thi được.
Viết một hàm mất mát để nắm bắt các thuộc tính này có vẻ khó nhằn và hầu hết các mô hình ngôn ngữ vẫn được đào tạo với một hàm loss đơn giản dựa trên dự đoán token tiếp theo (ví dụ: cross entropy). Để bù đắp cho những thiếu sót này, người ta xác định các chỉ số được thiết kế để nắm bắt tốt hơn các sở thích và ưu tiên của con người, chẳng hạn như BLEU hoặc ROUGE. Mặc dù phù hợp hơn so với bản thân hàm loss trong việc đo lường hiệu quả, các số liệu này chỉ so sánh văn bản được tạo với các tham chiếu bằng các quy tắc đơn giản và do đó cũng bị hạn chế. Câu hỏi đặt ra là tại sao chúng ta không sử dụng phản hồi của con người đối với văn bản được tạo làm thước đo hiệu quả hoặc thậm chí tiến thêm một bước và sử dụng phản hồi đó như một hàm loss để tối ưu hóa mô hình? Đó là ý tưởng về Học tăng cường từ phản hồi của con người (RLHF). RLHF giúp điều chỉnh các mô hình ngôn ngữ được huấn luyện trên một corpus chung trở nên phù hợp hơn với các giá trị phức tạp của con người.
Thành công gần đây nhất của RLHF là việc sử dụng nó trong ChatGPT. Với khả năng ấn tượng của ChatGPT, chúng tôi đã yêu cầu nó giải thích về RLHF:
RLHF: Các bước thực hiện
Học tăng cường từ Phản hồi của con người (còn được gọi là RL từ sở thích của con người) là một khái niệm đầy thách thức vì nó liên quan đến quá trình đào tạo nhiều mô hình và các giai đoạn triển khai khác nhau. Trong bài này, chúng tôi sẽ chia quá trình đào tạo thành ba bước chính:
- Pretrain Mô hình ngôn ngữ (LM),
- Thu thập dữ liệu và huấn luyện mô hình phần thưởng,
- Tinh chỉnh Mô hình ngôn ngữ với học tăng cường.
Để bắt đầu, chúng ta tìm hiểu cách các mô hình được pretrain.
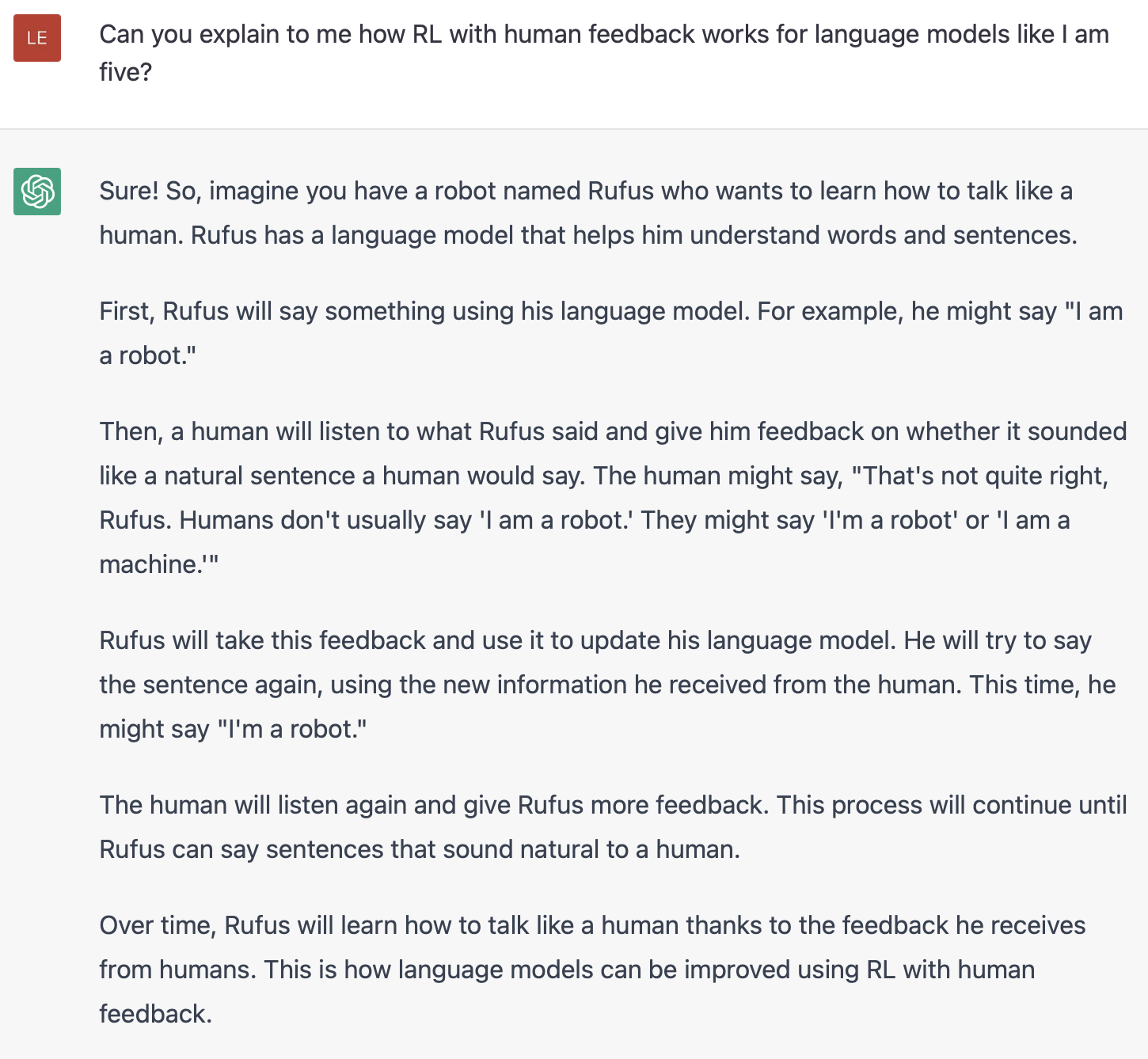
Pretrain Mô hình ngôn ngữ
Để bắt đầu, RLHF sử dụng mô hình ngôn ngữ đã được pretrain với các mục tiêu pretraining cổ điển (xem bài đăng này để biết thêm chi tiết). OpenAI đã sử dụng phiên bản nhỏ hơn của GPT-3 cho mô hình RLHF đầu tiên nổi tiếng của họ, InstructGPT. Anthropic đã sử dụng các mô hình transformer từ 10 triệu đến 52 tỷ tham số được huấn luyện cho nhiệm vụ này. DeepMind có mô hình 280 tỷ tham số của họ là Gopher.
Mô hình ban đầu này cũng có thể được tinh chỉnh trên các văn bản hoặc điều kiện bổ sung, nhưng không nhất thiết phải làm như vậy. Ví dụ, OpenAI tinh chỉnh trên văn bản do con người tạo ra được coi là “ưa thích” và Anthropic tạo ra mô hình LM ban đầu cho RLHF bằng cách distill LM gốc dựa trên ngữ cảnh của tiêu chí “hữu ích, trung thực và vô hại”. Cả hai đều là nguồn dữ liệu đắt đỏ, được tăng cường, nhưng không phải là kỹ thuật bắt buộc để hiểu RLHF.
Nhìn chung, không có câu trả lời rõ ràng về “mô hình nào” là tốt nhất cho xuất phát điểm của RLHF. Đây sẽ là một chủ đề phổ biến trong blog này – không gian thiết kế của các tùy chọn trong đào tạo RLHF chưa được khám phá kỹ lưỡng.
Tiếp theo, với mô hình ngôn ngữ, ta cần tạo dữ liệu để đào tạo mô hình phần thưởng, phương pháp để tích hợp các tùy chọn của con người vào hệ thống.
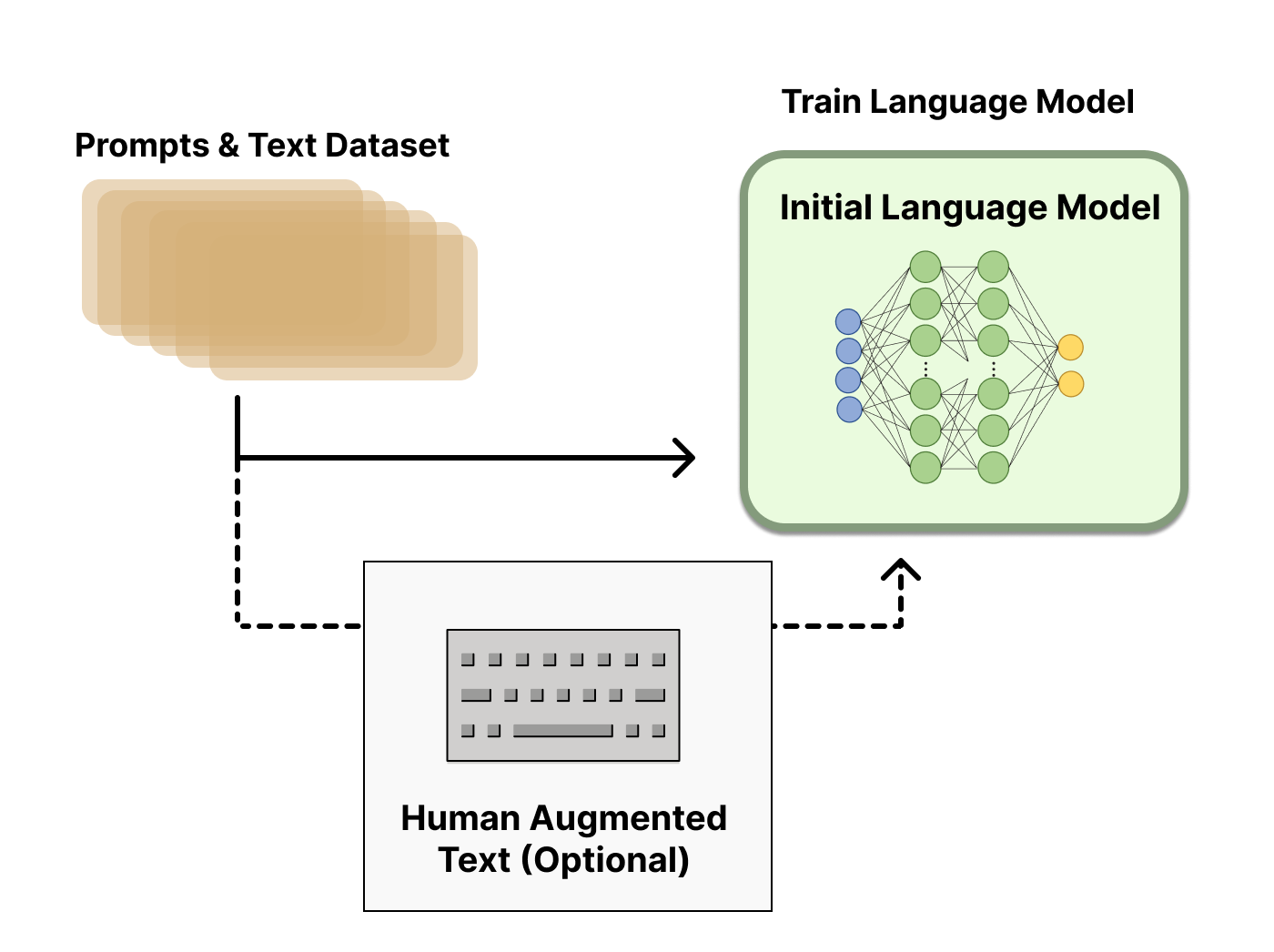
Huấn luyện mô hình phần thưởng
Việc tạo ra một mô hình phần thưởng (RM, còn được gọi là mô hình ưu tiên) được hiệu chỉnh theo sở thích của con người là ý tưởng nghiên cứu tương đối mới về RLHF. Mục tiêu cơ bản của nó là có được một mô hình hoặc hệ thống chứa một chuỗi văn bản và trả về phần thưởng vô hướng sẽ đại diện cho sở thích của con người bằng một con số. Hệ thống có thể là một LM đầu cuối hoặc một hệ thống mô-đun đưa ra phần thưởng (ví dụ: mô hình xếp hạng các đầu ra và thông tin xếp hạng được chuyển đổi thành phần thưởng). Đầu ra là phần thưởng vô hướng rất quan trọng đối với các thuật toán RL hiện có được tích hợp liền mạch sau này trong quá trình RLHF.
Các LM để mô hình phần thưởng có thể là LM được tinh chỉnh khác hoặc LM được pretrain trên dữ liệu ưu tiên. Ví dụ: Anthropic sử dụng một phương pháp tinh chỉnh chuyên biệt để khởi tạo các mô hình này sau khi pretrain (preference model pretraining, PMP) vì họ nhận thấy phương pháp này hiệu quả hơn so với tinh chỉnh, nhưng không có biến thể nào của mô hình phần thưởng được coi là tốt nhất cho đến bây giờ.
Tập dữ liệu huấn luyện về các cặp prompt-generation (lời nhắc – kết quả sinh) cho RM được tạo bằng cách lấy mẫu một tập hợp lời nhắc từ tập dữ liệu được xác định trước (Dữ liệu của Anthropic được tạo chủ yếu bằng công cụ trò chuyện trên Amazon Mechanical Turk có sẵn trên Hub và OpenAI sử dụng lời nhắc do người dùng gửi tới API). Lời nhắc được chuyển đến mô hình ngôn ngữ ban đầu để tạo văn bản mới.
Người chú thích có nhiệm vụ xếp hạng đầu ra văn bản được tạo từ LM. Ban đầu, người ta có thể nghĩ rằng con người nên áp dụng điểm số trực tiếp cho từng đoạn văn bản để tạo ra mô hình phần thưởng, nhưng điều này khó thực hiện trong thực tế. Các giá trị khác nhau của con người khiến những điểm số này không được ổn định và nhiễu. Thay vào đó, việc xếp hạng được sử dụng để so sánh kết quả đầu ra của nhiều mô hình và tạo ra một bộ dữ liệu được chuẩn hóa tốt hơn nhiều.
Có nhiều phương pháp để xếp hạng văn bản. Một phương pháp đã thành công là yêu cầu người dùng so sánh văn bản được tạo từ hai mô hình ngôn ngữ dựa trên cùng một lời nhắc. Bằng cách so sánh kết quả đầu ra của mô hình thông qua đối đầu trực tiếp, hệ thống Elo có thể được sử dụng để tạo thứ hạng của các mô hình và kết quả đầu ra tương đối với nhau. Các phương pháp xếp hạng khác nhau này được chuẩn hóa thành tín hiệu phần thưởng vô hướng để tối ưu các mô hình.
Một yếu tố thú vị của quá trình này là các hệ thống RLHF thành công cho đến nay đã sử dụng các mô hình ngôn ngữ phần thưởng với các kích thước khác nhau liên quan đến việc tạo văn bản (ví dụ: OpenAI 175B LM, mô hình phần thưởng 6B, LM được sử dụng bởi Anthropic và các mô hình phần thưởng từ 10B đến 52B, DeepMind sử dụng 70B Chinchilla cho cả LM và mô hình phần thưởng). Một nhận xét trực giác có thể rút ra ở đây là các mô hình phần thưởng này cần phải có khả năng hiểu văn bản được cung cấp cho chúng tương đương với mô hình sinh văn bản. (B là viết tắt của Billion, tức là tỷ tham số).
Như vậy, trong hệ thống RLHF, chúng ta có một mô hình ngôn ngữ ban đầu có thể được sử dụng để sinh văn bản và một mô hình phần thưởng nhận bất kỳ văn bản nào và gán cho nó một số điểm về mức độ chấp nhận của con người đối với nó. Tiếp theo, chúng ta sẽ sử dụng học tăng cường (RL) để tối ưu hóa mô hình ngôn ngữ gốc đối với mô hình phần thưởng.
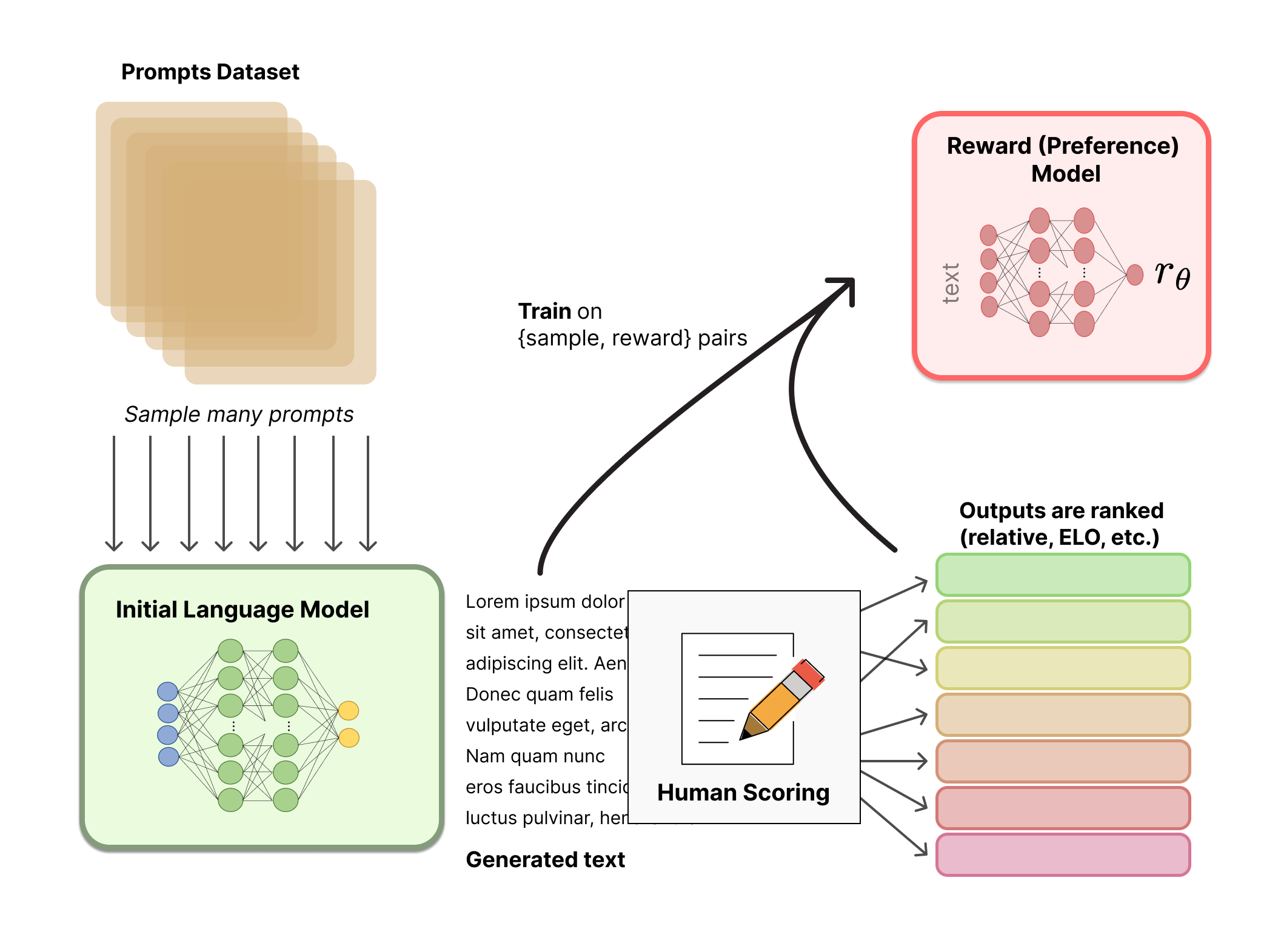
Tinh chỉnh với học tăng cường
Đào tạo một mô hình ngôn ngữ với học tăng cường, trong một thời gian dài, là điều mà mọi người nghĩ là không thể vì lý do kỹ thuật và thuật toán. Điều mà nhiều tổ chức dường như đã bắt đầu tiến hành là tinh chỉnh một số hoặc tất cả các tham số của bản sao của LM ban đầu bằng thuật toán RL policy-gradient, Proximal Policy Optimization (PPO). Các thông số của LM bị đóng băng vì việc tinh chỉnh toàn bộ mô hình 10 tỷ hoặc hơn 100 tỷ tham số rất tốn kém (để biết thêm thông tin, bạn có thể đọc thêm về Low-Rank Adaptation (LoRA) cho LM hoặc Sparrow LM từ DeepMind). PPO đã xuất hiện trong một thời gian tương đối dài – có rất nhiều hướng dẫn về cách thức hoạt động của nó. Sự trưởng thành tương đối của phương pháp này khiến nó trở thành một lựa chọn thuận lợi để nhân rộng ứng dụng đào tạo phân tán mới cho RLHF. Hóa ra những tiến bộ về học tăng cường mà RLHF đạt được đều dựa vào việc tinh chỉnh các mô hình lớn đựa trên những thuật toán quen thuộc (chúng ta sẽ nói thêm về điều này sau).
Đầu tiên chúng ta hãy xây dựng nhiệm vụ tinh chỉnh này như một bài toán học tăng cường. Đầu tiên, chính sách là một mô hình ngôn ngữ nhận vào prompt và trả về một chuỗi văn bản (hoặc phân phối xác suất trên văn bản). Không gian hành động của chính sách này là tất cả các token tương ứng với từ vựng của mô hình ngôn ngữ (thường theo thứ tự 50 nghìn token) và không gian quan sát là phân phối các chuỗi token đầu vào có thể có, cũng khá lớn so với các lần sử dụng RL trước đây (số chiều xấp xỉ kích thước từ vựng ^ độ dài của chuỗi token đầu vào). Hàm phần thưởng là sự kết hợp giữa mô hình ưu tiên và sự hạn chế thay đổi chính sách.
Hàm phần thưởng là nơi hệ thống kết hợp tất cả các mô hình mà chúng ta đã thảo luận thành một quy trình RLHF. Đưa ra lời nhắc, x, từ tập dữ liệu, hai văn bản, y1, y2, được tạo – một từ mô hình ngôn ngữ ban đầu và một từ lần lặp lại hiện tại của chính sách được tinh chỉnh. Văn bản từ chính sách hiện tại được chuyển đến mô hình ưu tiên, mô hình này trả về một khái niệm vô hướng về “mức độ ưu tiên”, \boldsymbol{r}_\theta. Văn bản này được so sánh với văn bản từ mô hình ban đầu để tính toán một giá trị phạt về sự khác biệt giữa chúng. Trong nhiều bài báo từ OpenAI, Anthropic và DeepMind, giá trị phạt này được thiết kế như một phiên bản thu nhỏ của phân kỳ Kullback–Leibler (KL) giữa các chuỗi phân phối này qua token, \boldsymbol{r}_{\mathrm{KL}}. Phân kỳ KL phạt và hạn chế chính sách học tăng cường di chuyển quá xa khỏi mô hình được pretrain ban đầu sau mỗi lần huấn luyện, điều này đảm bảo mô hình đưa ra các đoạn văn bản mạch lạc và hợp lý. Nếu không có giá trị phạt này, quá trình tối ưu hóa có thể bắt đầu tạo ra văn bản vô nghĩa nhưng lại đánh lừa mô hình phần thưởng để có được phần thưởng cao. Trên thực tế, phân kỳ KL được tính gần đúng thông qua lấy mẫu từ cả hai bản phân phối (được John Schulman giải thích tại đây). Cuối cùng, phần thưởng học tăng cường được cập nhật là \boldsymbol{r}=\boldsymbol{r}_\theta–\lambda r_{\mathrm{KL}}.
Một số hệ thống RLHF đã thêm các điều khoản bổ sung vào hàm phần thưởng. Ví dụ: OpenAI đã thử nghiệm thành công trên InstructGPT bằng cách kết hợp các gradient tiền đào tạo bổ sung (từ bộ chú thích của con người) vào quy tắc cập nhật cho PPO. Vì RLHF vẫn đang tiếp tục được khảo sát, việc xây dựng hàm phần thưởng này có thể sẽ tiếp tục phát triển.
Cuối cùng, quy tắc được cập nhật là tham số được cập nhật từ PPO mà tối đa hóa giá trị phần thưởng trong lô dữ liệu hiện tại (PPO là on-policy, điều này có nghĩa là các tham số chỉ được cập nhật với lô hiện tại). PPO là thuật toán tối ưu hóa vùng tin cậy sử dụng các ràng buộc về độ dốc để đảm bảo bước cập nhật không làm mất ổn định quá trình học. DeepMind đã sử dụng cách thiết lập phần thưởng tương tự cho Gopher nhưng dùng A2C để tối ưu hóa độ dốc, đây là điểm khác biệt đáng kể nhưng chưa được tái thực hiện ra bên ngoài.

Tùy theo sự cân nhắc, từ đây, RLHF có thể tiếp tục cập nhật lặp đi lặp lại mô hình phần thưởng và chính sách cùng nhau. Khi chính sách RL cập nhật, người dùng có thể tiếp tục xếp hạng các đầu ra này so với các phiên bản trước đó của mô hình. Hầu hết các bài báo vẫn chưa thảo luận về việc triển khai hoạt động này, vì chế độ triển khai cần thiết để thu thập loại dữ liệu này chỉ hoạt động đối với các tác nhân đối thoại có quyền truy cập vào cơ sở người dùng đã tham gia. Anthropic thảo luận về tùy chọn này dưới dạng Iterated Online RLHF (xem bài báo), trong đó các phần lặp lại của chính sách được đưa vào hệ thống xếp hạng ELO trên các mô hình. Điều này tạo nên các phức hợp động của chính sách và mô hình phần thưởng không ngừng được phát triển, đại diện cho một câu hỏi nghiên cứu phức tạp và mở.
Mã nguồn mở cho RLHF
Mã nguồn đầu tiên được công bố để tiến hành RLHF trên LMs bởi OpenAI trên TensorFlow năm 2019.
Từ đó đến nay, đã có một vài repo hoạt động với RLHF trên PyTorch. Trong đó, đáng chú ý nhất là Transformers Reinforcement Learning (TRL), TRLX được phát triển dựa trên TRL, và Reinforcement Learning for Language models (RL4LMs).
TRL được thiết kế để tinh chỉnh các LM được đào tạo trước trong hệ sinh thái Hugging Face với PPO. TRLX là một nhánh mở rộng của TRL do CarperAI xây dựng để xử lý các mô hình lớn hơn cho cả online training và offline training. Hiện tại, TRLX có API cho RLHF với PPO và ngôn ngữ ngầm định Q-Learning ILQL ở quy mô cần thiết để triển khai LM lớn hơn (ví dụ: 33 tỷ tham số). Các phiên bản tương lai của TRLX sẽ cho phép các mô hình ngôn ngữ lên đến 200 tỷ tham số. Do đó, giao diện của TRLX được tối ưu cho các kỹ sư máy học có kinh nghiệm ở quy mô này.
RL4LMs cung cấp các khối để tinh chỉnh và đánh giá LLM bằng nhiều thuật toán RL (PPO, NLPO, A2C và TRPO), các hàm và giá trị phần thưởng. Ngoài ra, thư viện có thể dễ dàng tùy chỉnh, cho phép huấn luyện bất kỳ LM dựa trên transformer với kiến trúc encoder-decoder hoặc encoder trên bất kỳ hàm phần thưởng tùy ý nào do người dùng chỉ định.
Đáng chú ý, đã có thử nghiệm và đánh giá điểm chuẩn trên nhiều loại tác vụ với số lượng lên tới 2000 thử nghiệm, nêu bật một số thông tin chi tiết thực tế về so sánh ngân sách dữ liệu (sử dụng chuyên gia so với mô hình phần thưởng), xử lý việc hack phần thưởng và sự không ổn định trong đào tạo, v.v. các kế hoạch hiện tại bao gồm đào tạo phân tán các mô hình lớn hơn và các thuật toán RL mới.
Cả TRLX và RL4LM đều đang được phát triển mạnh hơn, vì vậy nhiều tính năng đáng mong đợi sẽ sớm ra mắt.
Đây là dataset lớn được tạo bởi Anthropic trên Hub.
Bước tiếp theo của RLHF?
Mặc dù những kỹ thuật này cực kỳ hứa hẹn và có tác động mạnh và đã thu hút sự chú ý của các phòng thí nghiệm nghiên cứu lớn nhất về AI, nhưng vẫn có những hạn chế rõ ràng. Các mô hình, mặc dù tốt hơn, vẫn có thể tạo ra văn bản có hại hoặc không chính xác trên thực tế mà không có bất kỳ sự không chắc chắn nào. Sự không hoàn hảo này là một thách thức và động lực lâu dài đối với RLHF – giải quyết các vấn đề cố hữu của con người có nghĩa là sẽ không bao giờ có giới hạn cuối cùng rõ ràng phải vượt qua để mô hình được dán nhãn là hoàn chỉnh.
Khi triển khai một hệ thống sử dụng RLHF, việc thu thập dữ liệu sở thích của con người khá tốn kém do sự tích hợp trực tiếp của những nhân viên khác bên ngoài phạm vi huấn luyện mô hình. Hiệu suất của RLHF chỉ tốt bằng chất lượng của chú thích do con người tạo ra, có hai loại: văn bản do con người tạo, chẳng hạn như tinh chỉnh LM ban đầu trong InstructGPT và nhãn tùy chọn của con người giữa các kết quả đầu ra của mô hình.
Tạo văn bản con người viết tốt để trả lời prompt cụ thể là rất tốn kém, vì nó thường yêu cầu thuê nhân viên bán thời gian (thay vì có thể dựa vào người dùng sản phẩm hoặc nguồn lực cộng đồng). Rất may, quy mô dữ liệu được sử dụng trong đào tạo mô hình phần thưởng cho hầu hết các ứng dụng của RLHF (~50 nghìn mẫu ưu tiên được gắn nhãn) không đắt bằng. Tuy nhiên, đó vẫn là một chi phí cao hơn so với các phòng thí nghiệm hàn lâm có thể chi trả. Hiện tại, chỉ tồn tại một bộ dữ liệu quy mô lớn cho RLHF trên mô hình ngôn ngữ chung (từ Anthropic) và một vài bộ dữ liệu quy mô nhỏ hơn dành riêng cho các nhiệm vụ (chẳng hạn như dữ liệu tóm tắt từ OpenAI). Thách thức thứ hai của dữ liệu đối với RLHF là những người chú thích con người thường có thể không đồng ý với nhau, thêm một phương sai tiềm năng đáng kể vào dữ liệu đào tạo mà không có cơ sở thực tế.
Với những hạn chế này, rất nhiều tùy chọn thiết kế chưa được khám phá vẫn có thể cho phép RLHF đạt được những bước tiến đáng kể. Nhiều trong số này thuộc phạm vi cải thiện RL optimizer. PPO là một thuật toán tương đối cũ, nhưng không có lý do rõ ràng nào khiến các thuật toán khác không thể mang lại lợi ích và sự thay đổi cho quy trình thực hiện RLHF hiện có. Một chi phí lớn của phần phản hồi khi tinh chỉnh chính sách LM là mọi đoạn văn bản được tạo từ chính sách cần được đánh giá trên mô hình phần thưởng (vì nó hoạt động giống như một phần của môi trường trong khung RL tiêu chuẩn). Để tránh những chuyển tiếp tốn kém này của một mô hình lớn, offline RL có thể được sử dụng làm trình tối ưu hóa chính sách. Gần đây, các thuật toán mới đã xuất hiện, chẳng hạn như ngôn ngữ ẩn Q-learning (ILQL) [Talk về ILQL tại CarperAI], đặc biệt phù hợp với loại tối ưu hóa này. Những đánh đổi cốt lõi khác trong quy trình RL, như cân bằng thăm dò-khai thác, cũng chưa được ghi lại. Khám phá những hướng này ít nhất sẽ phát triển sự hiểu biết đáng kể về cách thức hoạt động của RLHF và, nếu không, chí ít sẽ cải thiện hiệu quả.
Chúng tôi đã tổ chức một bài giảng vào Thứ Ba ngày 13 tháng 12 năm 2022, mở rộng về bài đăng này; Bạn có thể xem nó ở đây!
Đọc thêm
Dưới đây là danh sách các bài báo phổ biến nhất về RLHF đến nay. Lĩnh vực này gần đây trở nên nổi tiếng với sự xuất hiện của DeepRL (khoảng năm 2017) và đã phát triển thành một nghiên cứu rộng hơn về các ứng dụng của LLMs từ nhiều công ty công nghệ lớn. Dưới đây là một số bài báo về RLHF trước khi chú trọng vào LM:
- TAMER: Training an Agent Manually via Evaluative Reinforcement (Knox và Stone 2008): Đề xuất một đại diện học tập nơi con người cung cấp điểm số cho các hành động được thực hiện lặp đi lặp lại để học mô hình phần thưởng.
- Interactive Learning from Policy-Dependent Human Feedback (MacGlashan et al. 2017): Đề xuất một thuật toán actor-critic, COACH, nơi phản hồi của con người (cả tích cực và tiêu cực) được sử dụng để điều chỉnh hàm ưu tiên.
- Deep Reinforcement Learning from Human Preferences (Christiano et al. 2017): RLHF áp dụng cho sở thích giữa các quỹ đạo Atari.
- Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces (Warnell et al. 2018): Mở rộng khuôn khổ TAMER, trong đó một mạng nơ-ron sâu được sử dụng để mô hình hóa dự đoán phần thưởng.
Và đây là tập hợp sơ bộ các bài báo “chủ chốt” đang mở rộng để cho thấy hiệu suất của RLHF cho LMs:
- Fine-Tuning Language Models from Human Preferences (Zieglar et al. 2019): Một bài báo sớm nghiên cứu ảnh hưởng của việc học phần thưởng trên bốn nhiệm vụ cụ thể.
- Learning to summarize with human feedback (Stiennon et al., 2020): RLHF áp dụng cho nhiệm vụ tóm tắt văn bản. Cũng như, Recursively Summarizing Books with Human Feedback (OpenAI Alignment Team 2021), công việc tiếp theo về tóm tắt sách.
- WebGPT: Browser-assisted question-answering with human feedback (OpenAI, 2021): Sử dụng RLHF để đào tạo một đại diện điều hướng web.
- InstructGPT: Training language models to follow instructions with human feedback (OpenAI Alignment Team 2022): RLHF áp dụng cho một mô hình ngôn ngữ tổng quát [Bài đăng trên blog về InstructGPT].
- GopherCite: Teaching language models to support answers with verified quotes (Menick et al. 2022): Đào tạo một LM với RLHF để trả lời câu hỏi kèm theo trích dẫn cụ thể.
- Sparrow: Improving alignment of dialogue agents via targeted human judgements (Glaese et al. 2022): Tinh chỉnh một đại diện đối thoại với RLHF
- ChatGPT: Optimizing Language Models for Dialogue (OpenAI 2022): Đào tạo một LM với RLHF để sử dụng phù hợp như một chatbot đa năng.
- Scaling Laws for Reward Model Overoptimization (Gao et al. 2022): nghiên cứu các đặc tính tỷ lệ của mô hình ưu tiên được học trong RLHF.
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (Anthropic, 2022): Tài liệu chi tiết về việc đào tạo một trợ lý LM với RLHF.
- Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned (Ganguli et al. 2022): Tài liệu chi tiết về các nỗ lực “khám phá, đo lường và cố gắng giảm bớt [các mô hình ngôn ngữ] đầu ra tiềm ẩn có hại”.
- Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning (Cohen et al. 2022): Sử dụng RL để tăng cường kỹ năng đối thoại của một đại diện đối thoại không giới hạn.
- Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization (Ramamurthy và Ammanabrolu et al. 2022): Thảo luận về không gian thiết kế của công cụ mã nguồn mở trong RLHF và đề xuất một thuật toán mới NLPO (Natural Language Policy Optimization) là một sự thay thế cho PPO.
Lĩnh vực này là sự hội tụ của nhiều lĩnh vực khác, vì vậy bạn cũng có thể tìm thấy các tài nguyên trong các lĩnh vực khác:
- Học liên tục các hướng dẫn (Kojima et al. 2021, Suhr và Artzi 2022) hoặc học từ phản hồi người dùng trong bandit (Sokolov et al. 2016, Gao et al. 2022)
- Lịch sử trước đây về việc sử dụng các thuật toán RL khác để tạo văn bản (không phải tất cả đều có sở thích con người), chẳng hạn như với mạng nơ-ron hồi quy (Ranzato et al. 2015), thuật toán actor-critic để dự đoán văn bản (Bahdanau et al. 2016), hoặc một công trình sớm thêm sở thích con người vào khuôn khổ này (Nguyen et al. 2017).