BLEU là viết tắt của Bilingual Evaluation Understudy, là phương pháp đánh giá một bản dịch dựa trên các bản dịch tham khảo, được giới thiệu trong paper BLEU: a Method for Automatic Evaluation of Machine Translation). BLEU được thiết kế để sử dụng trong dịch máy (Machine Translation), nhưng thực tế, phép đo này cũng được sử dụng trong các nhiệm vụ như tóm tắt văn bản, nhận dạng giọng nói, sinh nhãn ảnh v..v.. Bên cạnh đó phép đo này hoàn toàn có thể sử dụng để đánh giá chất lượng bản dịch của nhân viên.

Điều kiện tiên quyết để có thể sử dụng BLEU là bạn phải có một (hoặc nhiều) câu mẫu. Đối với bài toán dịch máy, câu mẫu chính là câu đầu ra của cặp câu trong tập dữ liệu. BLEU đánh giá một câu thông qua việc so khớp câu đó với các câu mẫu và cho thang điểm từ 0 (sai lệch tuyệt đối) đến 1 (khớp tuyệt đối).
BLEU được biết đến như một phương pháp đơn giản, dễ hiểu, chi phí tính toán thấp và tương đồng với cách đánh giá của con người. Mặc dù vậy, yếu tổ con người trong việc sinh câu mẫu làm cho BLEU không hoàn toàn khách quan. Ví dụ, cùng một câu có thể có nhiều bản dịch tốt và việc viết tất cả các bản dịch đó vào tập câu mẫu đôi khi bất khả thi.
Cách tính của BLEU là đếm số n-gram khớp nhau giữa câu mẫu (R) và câu được đánh giá (C) sau đó chia cho số token của C. Việc chọn n phụ thuộc vào ngôn ngữ, nhiệm vụ và mục tiêu cụ thể. Đơn giản nhất ta có thể sử dụng unigram là n-gram chứa 1 token (n=1). Một cách trực quan, n càng lớn, câu văn càng mượt.
Việc so khớp này không phụ thuộc vào vị trí, do đó BLEU không thể đánh giá được thứ tự của từ. Đây vừa là ưu điểm vừa là hạn chế của BLEU. Trong ngôn ngữ, một câu có thể được biểu diễn bởi các thứ tự từ khác nhau nhưng vẫn phải tuân theo những quy tắc nhất định.
Ngoài ra, để tránh việc một bản dịch lặp đi lặp lại một từ mà vẫn được “chấm điểm” cao (ví dụ như “this this this this” được so với “this is a cat”), BLEU tính đến số lần xuất hiện lớn nhất của mỗi n-gram trong toàn bộ các câu mẫu để giới hạn số lần khớp tối đa. Trong ví dụ trên, this sẽ chỉ được tính 1 lần”
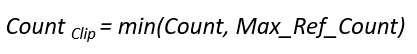
Trong Python, để tính điểm BLEU chúng ta có thể thực hiện dễ dàng với sự hỗ trợ của thư viện NLTK. Ví dụ như chúng ta có hai bản dịch cần đánh giá của câu “Có con mèo nằm trên chiếu”. Ta sẽ có điểm BLEU của hai câu như sau:
import nltk.translate.bleu_score as bleu
reference_translation=['The cat is on the mat.'.split(),
'There is a cat on the mat.'.split()
]
candidate_translation_1='the the the mat on the the.'.split()
candidate_translation_2='The cat is on the mat.'.split()
print("BLEU Score candidate 1: ",bleu.sentence_bleu(reference_translation, candidate_translation_1))
print("BLEU Score candidate 2: ",bleu.sentence_bleu(reference_translation, candidate_translation_2))

Với kết quả 0.47 và 1, BLEU đánh giá câu dịch thứ 2 tốt hơn câu dịch thứ 1 vì nó khớp tuyệt đối với câu trong tập ví dụ.
Nếu bạn thích bài viết này, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io hoặc kết nối với chúng tôi (dưới chân trang) để nhận được những thông tin quan trọng và cập nhật từ lĩnh vực!