


Boosting là một kỹ thuật ensemble có mục tiêu tạo ra một bộ phân lớp mạnh từ một số các bộ phân lớp yếu hơn. AdaBoost là thuật toán boosting được phát triển cho phân lớp nhị phân và là thuật toán đầu tiên thực sự thành công. Tìm hiểu AdaBoost là một cách hiệu quả để hiểu được boosting . Các phương pháp boosting hiện đại được xây dựng trên thuật toán này.

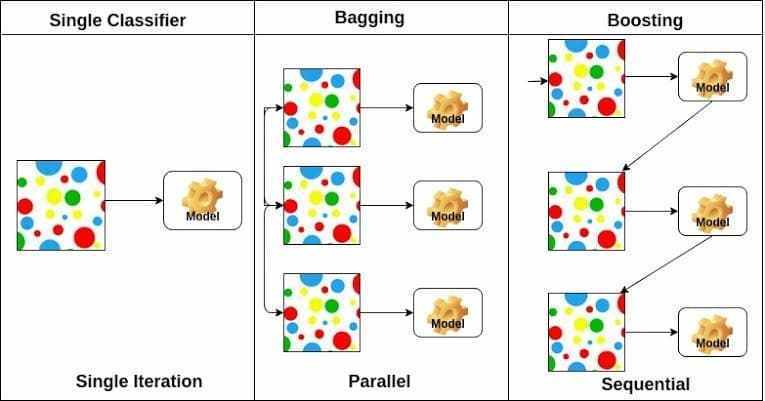
Kỹ thuật này được thực hiện thông qua việc xây dựng một mô hình từ dữ liệu huấn luyện, sau đó các mô hình tiếp theo được tạo, cố gắng sửa các lỗi từ mô hình đầu tiên. Các mô hình được thêm vào cho đến khi tập huấn luyện được dự đoán hoàn hảo hoặc số lượng mô hình đạt ngưỡng cực đại.
AdaBoost được sử dụng với các cây quyết định có độ sâu nhỏ. Sau khi cây đầu tiên được tạo, hiệu suất của cây trên mỗi mẫu huấn luyện được sử dụng làm thông tin để quyết định cây tiếp theo sẽ tập trung vào mẫu huấn luyện nào. Dữ liệu huấn luyện khó dự đoán sẽ được đánh trọng số lớn hơn so với các trường hợp khác.
Các mô hình được tạo lần lượt, hiệu suất của mô hình trước sẽ ảnh hưởng đến cách mô hình sau được xây dựng. Sau khi tất cả các cây (mô hình) được xây dựng, dự đoán được thực hiện trên dữ liệu mới. Lần này, mỗi cây được được đánh trọng số tùy thuộc vào độ chính xác của nó trên dữ liệu huấn luyện.
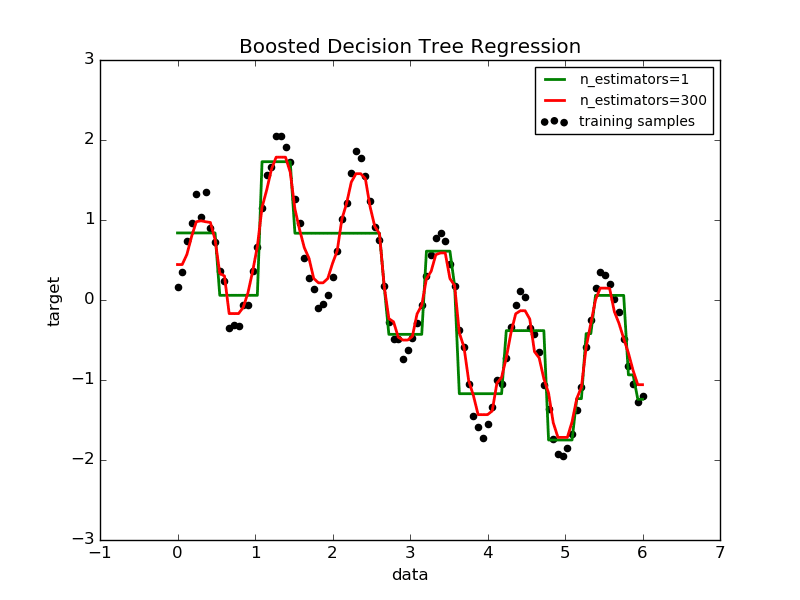
Chúng ta có thể nhìn vào hình dưới để thấy được sự cải thiện của AdaBoost (đường màu đỏ) so với một mô hình riêng lẻ (đường màu xanh). AdaBoost với 300 bộ phân lớp có khả năng khớp với dữ liệu tốt hơn rất nhiều so với một bộ phân lớp đơn lẻ.
Nếu bạn thấy bài viết thú vị, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io hoặc đăng ký (dưới chân trang) để nhận được những bài viết tương tự sớm nhất!