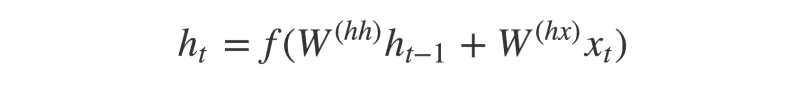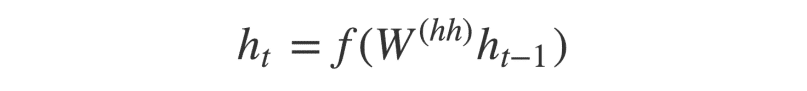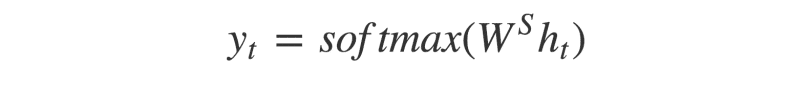Lần này, trituenhantao.io sẽ cung cấp cho bạn một bài giải thích ngắn gọn và cô đọng về mô hình seq2seq
Seq2Seq
Sequence to sequence - Từ chuỗi sang chuỗi. Thuật ngữ này chỉ một lớp các bài toán hoặc các kiến trúc mô hình có đầu vào và đầu ra là một chuỗi các phần tử.
sử dụng encoder
encoder
Bộ mã hóa trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
(bộ mã hóa) decoder
decoder
Bộ giải mã trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
(bộ giải mã). Lớp các mô hình này đã mang đến những kết quả rõ nét trong các nhiệm vụ phức tạp như dịch máy, chú thích video, hỏi đáp, v..v..
Ghi chú: Trong bài này, các từ mang tính chất thuật ngữ được giữ nguyên để các bạn tiện tra cứu thêm thông tin.
Để có thể hiểu về cách thức hoạt động của lớp mô hình seq2seq
Seq2Seq
Sequence to sequence - Từ chuỗi sang chuỗi. Thuật ngữ này chỉ một lớp các bài toán hoặc các kiến trúc mô hình có đầu vào và đầu ra là một chuỗi các phần tử.
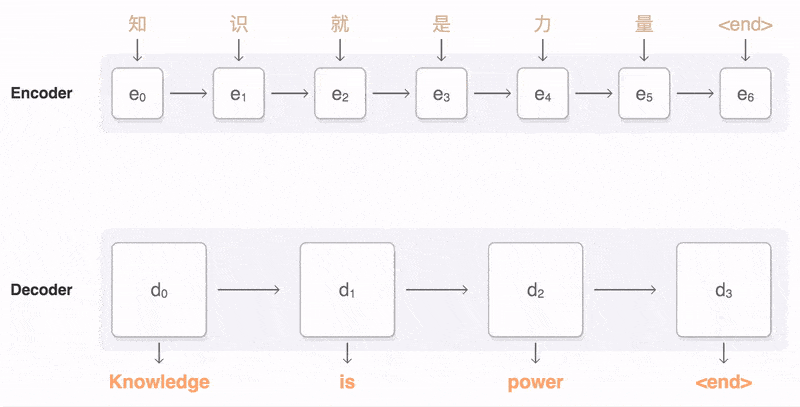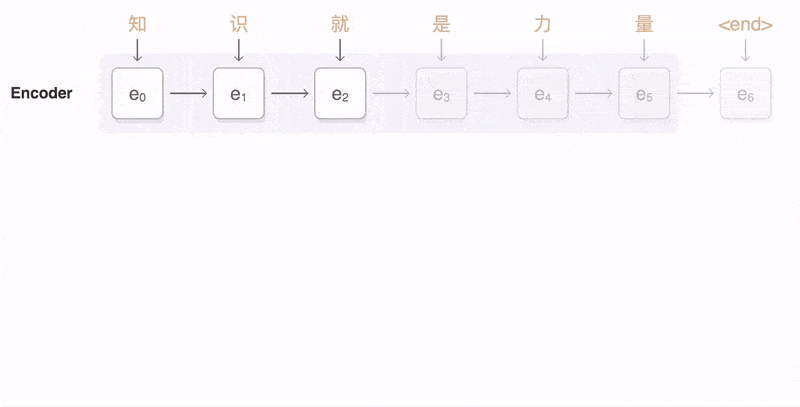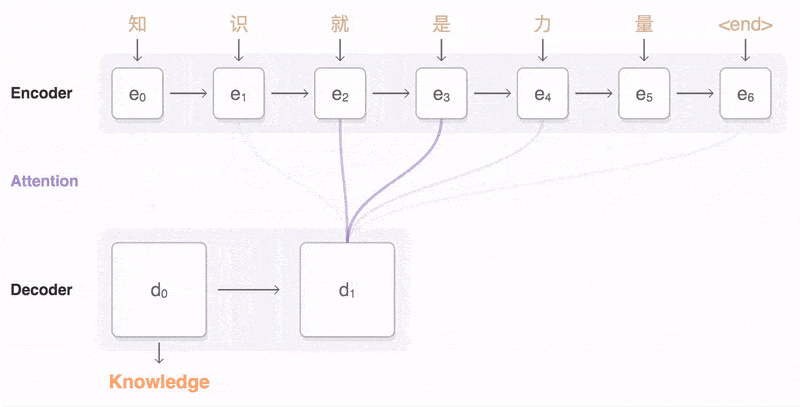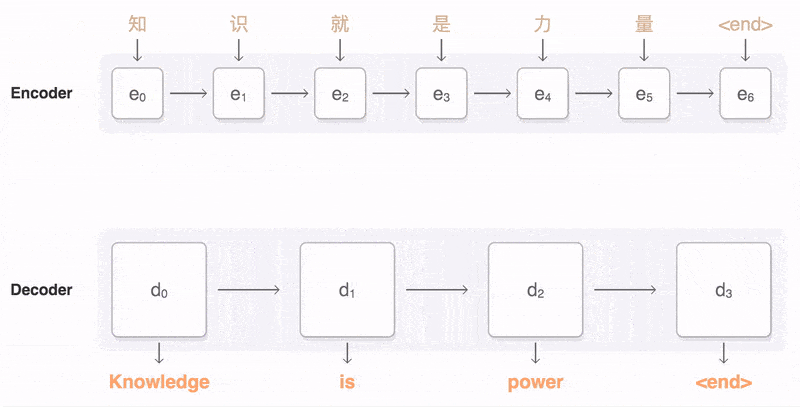
, chúng ta cùng nhìn vào hình vẽ dưới đây.
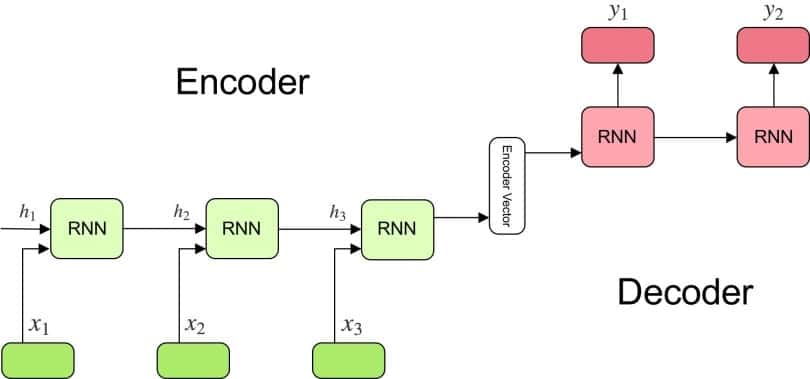
Kiến trúc của mô hình encoder-decoder
encoder-decoder
Kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được decoder sử dụng để sinh chuỗi đầu ra.
seq2seq
Seq2Seq
Sequence to sequence - Từ chuỗi sang chuỗi. Thuật ngữ này chỉ một lớp các bài toán hoặc các kiến trúc mô hình có đầu vào và đầu ra là một chuỗi các phần tử.
Mô hình điển hình thuộc lớp này bao gồm 3 phần: bộ mã hóa (Encoder
encoder
Bộ mã hóa trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
), véc tơ mã hóa trung gian (Encoder
encoder
Bộ mã hóa trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
vector) và bộ giải mã (Decoder
decoder
Bộ giải mã trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
).
Bộ mã hóa – Encoder
Một ngăn xếp chứa các mạng con là phần tử của RNN
RNN
Mạng nơ ron hồi quy (RNN) là một lớp các mạng nơ ron nhân tạo trong đó đầu ra từ bước trước được cung cấp làm đầu vào cho bước hiện tại.
(hoặc các ô nhớ của LTSM hay GRU
GRU
Viết tắt của Gated recurrent units, là một cơ chế gating trong các mạng nơ ron hồi quy, được giới thiệu vào năm 2014 bởi nhóm của Kyunghyun Cho. GRU giống với LSTM nhưng có ít thông số hơn, vì kiến trúc này không có cổng đầu ra.
) nơi nhận vào tín hiệu của một phần tử của chuỗi đầu vào và truyền tiếp về phía cuối mạng.
Trong bài toán hỏi đáp, chuỗi đầu vào là tập hợp tất cả các từ của câu hỏi. Mỗi từ được thể hiện bởi x_i với i là thứ tự của từ đó.
Các trạng thái ẩn h_i được tính với công thức:
Công thức đơn giản này mô tả kết quả của một mạng nơ ron
Nơ ron
Một nơ ron hay tế bào thần kinh nhân tạo (còn được gọi là perceptron) là một hàm toán học. Nó là tổng của một hoặc nhiều yếu tố đầu vào được nhân với các trọng số. Giá trị này sau đó được chuyển đến một hàm phi tuyến tính, được gọi là hàm kích hoạt, để trở thành đầu ra của nơ ron.
hồi quy (RNN
RNN
Mạng nơ ron hồi quy (RNN) là một lớp các mạng nơ ron nhân tạo trong đó đầu ra từ bước trước được cung cấp làm đầu vào cho bước hiện tại.
) thông thường. Như chúng ta có thể thấy, các trạng thái ẩn được tính bởi đầu vào tương ứng (x_t) và trạng thái ẩn trước đó h_(t-1).
Véc tơ mã hóa trung gian – Encoder vector
Đây là trạng thái ẩn nằm ở cuối chuỗi, được tính bởi bộ mã hóa, nó cũng được tính bởi công thức phía trên.
Véc tơ này có chức năng gói gọn thông tin của toàn bộ các phần tử đầu vào để giúp cho bộ mã hóa dự đoán thông tin chính xác hơn.
Véc tơ này sau đó hoạt động như trạng thái ẩn đầu tiên của bộ giải mã.
Bộ giải mã – Decoder
Một ngăn xếp các mạng con là phần tử của RNN
RNN
Mạng nơ ron hồi quy (RNN) là một lớp các mạng nơ ron nhân tạo trong đó đầu ra từ bước trước được cung cấp làm đầu vào cho bước hiện tại.
có nhiệm vụ dự đoán đầu ra y_t tại thời điểm t.
Mỗi phần từ này nhận đầu vào là trạng thái ẩn trước đó và tạo kết quả đầu ra cũng như trạng thái ẩn của chính nó.
Trong bài toán hỏi đáp, chuỗi đầu ra là tập hợp các từ của câu trả lời. Mỗi từ được biểu diễn bởi y_i với i là thứ tự của từ.
Các trạng thái ẩn h_i được tính bởi công thức:
Như chúng ta thấy, các trạng thái ẩn được tính bởi trạng thái ngay trước đó.
Đầu ra y_t tại thời điểm t được tính bởi công thức:
Chúng ta tính đầu ra sử dụng trạng thái ẩn tương ứng tại thời điểm hiện tại và nhân với trọng số tương ứng W(S). Softmax
Softmax
Trong toán học, hàm softmax, còn được gọi là hàm mũ mềm hoặc hàm mũ chuẩn hóa, là hàm nhận vào một vectơ của chứa K số thực và chuẩn hóa nó thành phân phối xác suất chứa K xác suất tỷ lệ thuận với lũy thừa của các số đầu vào.
được sử dụng để tạo ra vec tơ xác suất giúp chúng ta xác định đầu ra cuối cùng (VD: các từ trong bài toán hỏi đáp).
Năng lực đặc biệt của mô hình này là nó có thể ánh xạ chuỗi đầu vào và chuỗi đầu ra có độ dài khác nhau. Vì thế, nó mở ra giải pháp cho một loạt các bài toán trong lĩnh vực này.
Hi vọng thông qua bài viết này các bạn đã hiểu thêm về mô hình seq2seq
Seq2Seq
Sequence to sequence - Từ chuỗi sang chuỗi. Thuật ngữ này chỉ một lớp các bài toán hoặc các kiến trúc mô hình có đầu vào và đầu ra là một chuỗi các phần tử.
với kiến trúc sử dụng encoder
encoder
Bộ mã hóa trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
và decoder
decoder
Bộ giải mã trong kiến trúc sử dụng bộ mã hóa và bộ giải mã, thường thấy trong các mô hình seq2seq. Encoder mã hóa chuỗi đầu vào thành một biểu diễn gọi là "vectơ ngữ cảnh". Vectơ này được Decoder sử dụng để sinh chuỗi đầu ra.
. Hãy thường xuyên truy cập hoặc đăng ký nhận bản tin Trí tuệ nhân tạo (ở chân trang) để nhận được những bài viết cập nhật nhất về chủ đề này các bạn nhé!