


Hàm loss là thành phần quan trọng trong việc huấn luyện các mô hình học máy. Hãy cùng tìm hiểu ý nghĩa và các trường hợp sử dụng của chúng!
Hàm loss là gì?
Huấn luyện mạng nơ ron nhân tạo giống với cách con người học tập. Chúng ta đưa mô hình dữ liệu, nó đưa ra dự đoán và chúng ta phản hồi xem dự đoán đó có chính xác hay không. Dựa trên phản hồi, mô hình có thể sửa những lỗi sai trước đó. Quá trình này lặp đi lặp lại cho đến khi mô hình đạt đến một độ chính xác nhất định.
Việc chỉ ra rằng mô hình đã đoán sai là vô cùng quan trọng để nó có thể học ra tri thức từ dữ liệu. Và đó là nguyên nhân hàm loss được thiết kế. Hàm loss sẽ chỉ ra mô hình đoán sai bao nhiêu so với giá trị thực tế. Trong bài viết này, hãy cùng trituenhantao.io tìm hiểu một số hàm loss phổ biến được sử dụng trong Pytorch.
Hàm Loss MAE – Trị tuyệt đối trung bình
torch.nn.L1Loss
Đo sai số trị tuyệt đối trung bình (mean average error)

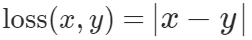
với x là giá trị thực tế, y là giá trị dự đoán.
Ý nghĩa của MAE
Nó đo khoảng cách giữa giá trị dự đoán và giá trị thực. Đây là phép đo sai số đơn giản nhất. Giá trị tuyệt đối được sử dụng vì chúng ta không muốn các số âm và các số dương được cộng trái dấu và triệt tiêu lẫn nhau.
Giá trị của MAE càng thấp, mô hình càng tin cậy. Chúng ta không thể mong giá trị lỗi bằng 0 vì trường hợp này rất hiếm gặp trong thực tế. Nếu giá trị này bằng 0 trong chương trình của bạn, bạn nên tập trung gỡ lỗi chương trình hoặc kiểm tra lại cách huấn luyện và quan sát mô hình thay vì ăn mừng.
Khi nào thì sử dụng MAE?
+ Các bài toán hồi quy
+ Các mô hình đơn giản
+ Mạng nơ ron
thường sử dụng với các bài toán phức tạp nên MAE ít được dùng
Hàm Loss MSE – Bình phương trung bình
torch.nn.MSELoss
Đo sai số bình phương trung bình (chuẩn L2 bình phương).

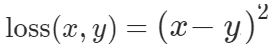
với x là giá trị thực tế, y là giá trị dự đoán.
Ý nghĩa của MSELoss
Bình phương sai số giữa giá trị dự đoán và giá trị thực tế giúp ta khuếch đại các lỗi lớn. Ví dụ 200 bình phương à 40000, còn 0.1 bình phương là 0.01. Ta thấy rằng, việc sử dụng hàm loss này sẽ phạt nặng các lỗi lớn của mô hình và khuyến khích các lỗi nhỏ.
Khi nào sử dụng MSELoss?
+ Bài toán hồi quy
+ Đặc trưng
dạng số không quá lớn
+ Bài toán trong không gian có số chiều không quá lớn
Hàm Loss Smooth L1 – L1 mịn
torch.nn.SmoothL1Loss
Còn có tên Huber loss , với công thức

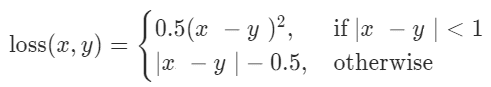
Ý nghĩa của Smooth L1 Loss
Hàm này sử dụng bình phương nếu trị tuyệt đối của sai số dưới 1 và sử dụng trị tuyệt đối trong trường hợp còn lai. Ta có thể thấy, hàm này không nhạy cảm với các outlier như MSELoss và giúp tránh tình trạng bùng nổ gradient .
Khi nào sử dụng Smooth L1 Loss?
+ Bài toán hồi quy
+ Đặc trưng
có giá trị lớn
+ Phù hợp với đa số các bài toán
Hàm Loss Negative Log-Likelihood
torch.nn.NLLLoss
NLLLoss được xác định bởi công thức:

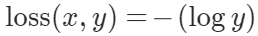
Ý nghĩa của NLLLoss
Hàm này tối đa hóa xác suất tổng thể của dữ liệu. Nó sẽ phạt mô hình khi dự đoán lớp đầu ra mong muốn với xác suất nhỏ. Hàm log giúp hiện thực hóa việc phạt, các xác suất là các giá trị số nhỏ hơn 1, do đó số đối của giá trị log là số dương, xác suất càng nhỏ, giá trị loss càng lớn.
Khi nào sử dụng NLLLoss?
+ Bài toán phân lớp
Hàm Loss Cross-Entropy
torch.nn.CrossEntropyLoss
Đo giá trị cross-entropy giữa giá trị dự đoán và giá trị thực tế.

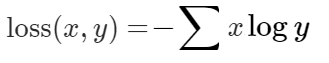
Với x là xác xuất của nhãn đúng, y và xác suất của nhãn dự đoán.
Ý nghĩa của Cross-Entropy Loss
Cross-entropy Loss được sử dụng để học phân bố xác suất của dữ liệu. Trong khi các hàm khác phạt các giá trị sai, Cross-entropy Loss phạt mô hình dựa trên cả tính đúng và độ chắc chắn (tự tin) của dự đoán. Hàm này phạt cả các dự đoán sai lẫn các dự doán đúng nhưng độ chắc chắn thấp.
Khi nào sử dụng Cross-entropy Loss?
+ Bài toán phân loại
+ Tạo ra các mô hình với độ chắc chắn cao (precision, recall cao)
Hàm Loss Kullback-Leibler
torch.nn.KLDivLoss
KLDivLoss đưa ra một phép đo về sự khác biệt giữa hai phân bố xác suất

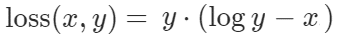
Với x là xác xuất của nhãn đúng, y và xác suất của nhãn dự đoán.
Ý nghĩa của KLDivLoss
KLDivLoss khá giống với Cross-Entropy Loss . Hai phân bố xác suất càng khác nhau, giá trị loss càng lớn. Sự khác biệt nằm ở chỗ KLDivLoss không phạt mô hình dựa trên độ chắc chắn.
Khi nào sử dụng KLDivLoss?
+ Bài toán phân loại
Hàm Loss Margin Ranking – Xếp hạng biên
torch.nn.MarginRankingLoss
Margin Ranking Loss sử dụng hai đầu vào x1, x2, và nhãn y với giá trị (1 hoặc -1). Nếu y == 1 , hàm này sẽ coi đầu vào thứ nhất nên được xếp hạng cao hơn đầu vào thứ 2, và ngược lại với y == -1.

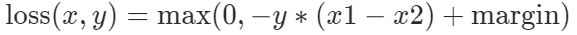
Ý nghĩa của Margin Ranking Loss
Dự đoán y của mô hình dựa trên việc xếp hạng x1 và x2. Giả sử rằng giá trị mặc định của biên (margin) bằng 0, nếu y và (x1-x2) cùng dấu, giá trị loss bằng 0. Nếu y và (x1-x2) trái dấu, giá trị loss được tính bởi y * (x1-x2).
Khi nào sử dụng Margin Ranking Loss?
+ GANs.
+ Các nhiệm vụ xếp hạng
Hàm Loss Hinge Embedding
torch.nn.HingeEmbeddingLoss
Được sử dụng để đo độ tương tự / khác biệt giữa hai đầu vào.

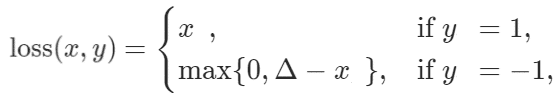
Ý nghĩa của Hinge Embedding Loss
Giá trị dự đoán y của mô hình dựa trên đầu vào x. Giả sử Δ=1, nếu y=-1, giá trị loss được tính bằng (1-x) nếu (1-x)>0 và 0 trong trường hợp còn lại. Với y =1, loss chính là giá trị của x.
Khi nào sử dụng Hinge Embedding Loss?
+ Học các biểu diễn nhúng không tuyến tính
+ Học bán giám sát
+ Đo độ tương đồng / khác biệt giữa hai đầu vào
Hàm Loss Cosine Embedding
torch.nn.CosineEmbeddingLoss
Được sử dụng để đo độ tương tự / khác biệt giữa hai đầu vào.

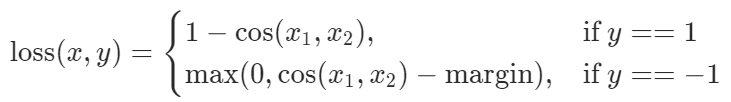
Ý nghĩa của Cosine Embedding Loss
Giá trị dự đoán y được xác định dựa trên khoảng cách cosine giữa hai đầu vào x1 và x2. Giá trị này xác định bởi góc giữa hai véc tơ theo công thức:

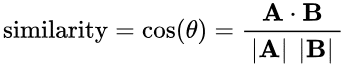
Khi nào sử dụng Cosine Embedding Loss?
+ Học các biểu diễn nhúng không tuyến tính
+ Học bán giám sát
+ Đo độ tương đồng / khác biệt giữa hai đầu vào
Nếu bạn thấy bài viết này hữu ích, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io hoặc đăng ký (dưới chân trang) để có được những bài viết hữu ích, mới nhất về chủ đề này!