
BERT của Google và các phương pháp dựa trên transformer gần đây đã gây ra một cơn bão trong lĩnh vực NLP, đạt kết quả vượt trội trên một số nhiệm vụ. Gần đây, những cải tiến khác nhau của BERT đã xuất hiện. Hãy cùng trituenhantao.io tìm hiểu các điểm tương đồng và khác biệt để lựa chọn ra mô hình phù hợp nhất cho bạn.


BERT là mô hình transformer hai chiều được pre-trained với một lượng lớn dữ liệu văn bản và có thể được dùng để finetuning cho một nhiệm vụ cụ thể. Đóng góp chính giúp cho BERT tạo ra những kết quả vượt trội nằm ở kiến trúc transformer hai chiều và kỹ thuật huấn luyên với mô hình ngôn ngữ sử dụng mặt nạ (MLM ) và cơ chế dự đoán câu kế tiếp (NSP ).
Gần đây, một vài phương pháp được giới thiệu để cải tiến BERT trên phương diện dự đoán hoặc tốc độ tính toán (chứ không phải cả 2).
XLNet là một mô hình transformer hai chiều sử dụng phương pháp huấn luyện mô hình được nâng cấp so với BERT. Với dữ liệu huấn luyện lớn hơn, XLNET đạt kết quả vượt trội hơn BERT trên 20 nhiệm vụ ngôn ngữ.
Để cải thiện hiệu quả huấn luyện, XLNET sử dụng mô hình ngôn ngữ hoán vị, tức là các token được dự đoán theo một thứ tự ngẫu nhiên. Điều này khác với mô hình ngôn ngữ sử dụng mặt nạ, với 15% token được che đi để bắt mô hình phải dự đoán. Điều này cũng khác với mô hình ngôn ngữ thông thường, với các token được sắp xếp từ trái sang phải chứ không phải theo thứ tự ngẫu nhiên. Cách huấn luyện này giúp mô hình học được các quan hệ hai chiều cũng như quan hệ phụ thuộc giữa các từ. Bên cạnh đó, Transformer XL là kiến trúc cơ sở của XLNet cũng cho thấy hiệu quả tốt kể cả khi không dùng cách huấn luyện với hoán vị từ.
XLNet được huấn luyện với hơn 130GB dữ liệu text và 512 chip TPU trong 2 ngày rưỡi, các con số này đều lớn hơn so với BERT.
RoBERTa được giới thiệu bởi Facebook là một phiên bản được huấn luyện lại của BERT với một phương pháp huấn luyện tốt hơn với dữ liệu được tăng gấp 10 lần.
Để tăng cường quá trình huấn luyện, RoBERTa không sử dụng cơ chế dự đoán câu kế tiếp (NSP ) từ BERT mà sử dụng kỹ thuật mặt nạ động (dynamic masking), theo đó các token mặt nạ sẽ bị thay đổi trong quá trình huấn luyện. Sử dụng kích thước batch lớn hơn cho thấy hiệu quả tốt hơn khi huấn luyện.
Một điều quan trọng nữa, RoBERTa sử dụng 160GB văn bản để huấn luyện. Trong đó, 16GB là sách và Wikipedia tiếng Anh được sử dụng trong huấn luyện BERT. Phần còn lại bao gồm CommonCrawl News dataset (63 triệu bản tin, 76 GB), ngữ liệu văn bản Web (38 GB) và Common Crawl Stories (31 GB). Mô hình này được huấn luyện với GPU của Tesala 1024 V100 trong một ngày.
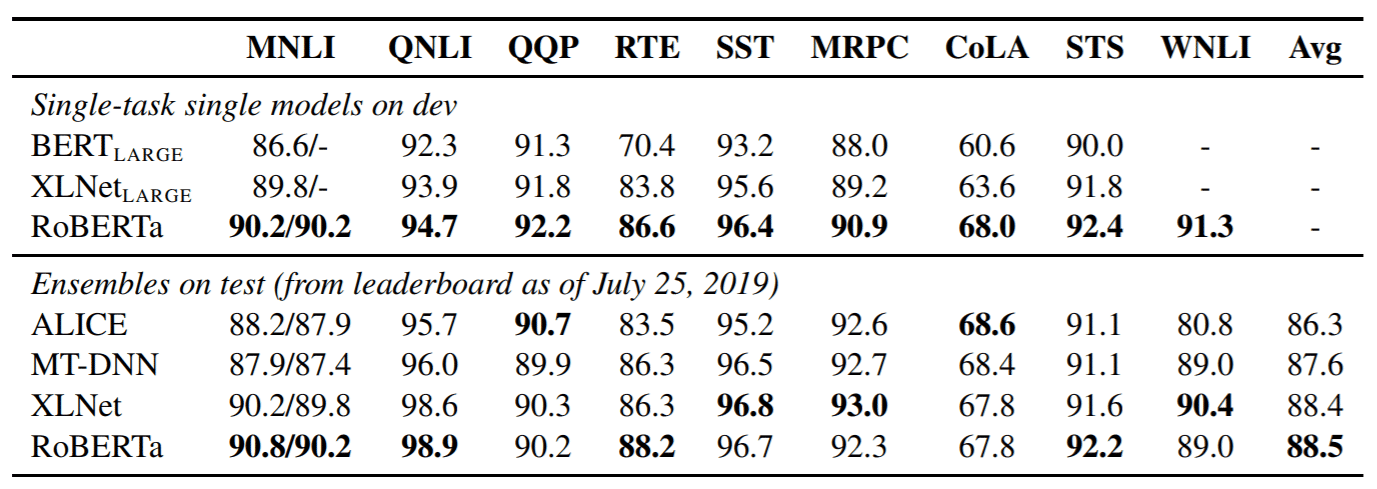
Kết quả là, RoBERTa vượt trội hơn cả BERT và XLNet trên dữ liệu đánh giá GLUE:

Mặt khác, để giảm thời gian tính toán (đào tạo, dự đoán) của BERT hoặc các mô hình liên quan, một lựa chọn tự nhiên là sử dụng một mạng nhỏ hơn để ước tính hiệu suất. Có nhiều cách tiếp cận có thể được sử dụng cho việc này nhưng đều dẫn đến hiệu quả dự đoán bị suy giảm.
DistilBERT học một phiên bản xấp xỉ của BERT, giữ lại 97% hiệu quả dự đoán nhưng chỉ sử dụng một nửa tham số. DistilBERT sử dụng kỹ thuật gọi là distillation , giúp xấp xỉ BERT như một giáo viên của DistilBERT. Ý tưởng ở đây là khi một mạng lớn đã được huấn luyện, phân bố xác xuất đầu ra của nó có thể được xấp xỉ bởi một mạng nhỏ hơn. Hàm loss được sử dụng trong xấp xỉ hậu nghiệm trong thống kê Bayes là Kulback Leiber divergence cũng được sử dụng khi huấn luyện DistilBERT.
Nếu bạn muốn tốc độ dự đoán nhanh và sẵn sàng đánh đổi một vài phần trăm hiệu quả dự đoán, DistilBERT là một lựa chọn đáng cân nhắc. Nhưng nếu bạn muốn tập trung vào hiệu quả của mô hình, tốt hơn bạn nên chọn RoBERTa của Facebook. Cách huấn luyện hoán vị của XLNet về mặt lý thuyết có thể nắm bắt tốt các ràng buộc trong câu nên có thể hoạt động tốt với các bài toán yêu cầu cao về ngữ nghĩa. Còn nếu bạn không yêu cầu quá cao về những khía cạnh trên thì BERT cũng là lựa chọn không hề tồi dành cho bạn.
Kết luận
Mọi sự cải tiến đều nằm ở việc tăng dữ liệu huấn luyện, tăng sức mạnh của phần cứng và tối ưu quá trình huấn luyện. Mặc dù mỗi cách có những giá trị riêng của nó, tất cả đều không vượt qua được sự đánh đổi kinh điển giữa hiệu quả và tốc độ.
Nếu bạn thấy bài viết này hữu ích, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập trituenhantao.io hoặc đăng ký (dưới chân trang) để nhận được những bài viết mới nhất và cập nhật nhất về chủ đề này!