
Năm 2018, Google giới thiệu BERT, mô hình học sâu pre-trained lập kỷ lục với 11 kết quả state-of-the-art với các nhiệm vụ của Xử lý ngôn ngữ tự nhiên. Nó nhanh chóng nhận được sự quan tâm lớn của các nhà khoa học và công nghiệp trên toàn thế giới. Các công trình nghiên cứu sử dụng BERT tăng nhanh chưa từng thấy. Khi thế giới chưa hết kinh ngạc về BERT thì một mô hình pre-trained mới vượt trội hơn BERT đã xuất hiện. Nó mang tên XLNet.
Tháng 6 vừa rồi, các nhà nghiên cứu từ trường Đại học Carnegie Mellon hợp tác với Google Brain đã giới thiệu một mô hình pre-trained mới mang tên XLNet. Thông qua thực nghiệm, mô hình này cho kết quả vượt trội hơn BERT trong 20 nhiệm vụ trong trong đó có SQuAD, GLUE, và RACE.
Theo các tác giả, các mô hình pre-trained được xây dựng dựa trên phương pháp tự mã hóa khử nhiễu (AE) giúp giữ được thông tin về ngữ cảnh hai chiều tốt hơn những mô hình sử dụng phương pháp tự hồi quy (AR). Mặc dù vậy, trong phương pháp của mình, BERT phải giấu đi 15% số từ trong chuỗi đầu vào, điều này làm mất thông tin về quan hệ giữa các từ. Do đó có một sự khác biệt lớn giữa mô hình pre-trained và các phiên bản fine-tuning của nó.
Khắc phục vấn đề này, XLNet được xây dựng dựa trên phương pháp tự hồi quy (AR) tổng quát. Một cách dễ hiểu hơn, XLNet có thể thực hiện những việc sau:
- Học thông tin ngữ cảnh hai chiều sử dụng MLE với tất cả các chuỗi nhân tố có thể;
- Khắc phục những nhược điểm của BERT bằng phương pháp tự hồi quy.
Không chỉ vậy, XLNet cũng kết hợp tất cả các ưu điểm của mô hình tự hồi quy tốt nhất hiện nay, Transformer-XL.
Như một kết quả tất yếu, XLNet vượt qua BERT trên 20 nhiệm vụ và trở thành phương pháp state-of-the-art đối với 18 nhiệm vụ, bao gồm QA, NLI, phân tích tình cảm và xếp hạng tài liệu.
Các mô hình vượt qua BERT trong những tháng gần đây đơn thuần là những sửa đổi trên cơ sở của người khổng lồ này. Mặc dù vậy, về bản chất thì kiến trúc mô hình và các nhiệm vụ không có nhiều sự thay đổi. Với cách tiếp cân khác, các tác giả của XLNet phân tích ưu và nhược của mô hình pre-trained dựa trên tự hồi quy (AR) và tự mã hóa (AE) và đề xuất ra mô hình vượt trội này với hi vọng có thể kết hợp được tất cả những ưu điểm tốt nhất của hai phương pháp.
Thực tế, XLNet đã làm được điều đó. Nó là sự kết hợp những ưu điểm tốt nhất và hạn chế nhược điểm của cả hai mô hình AR và AE. Cụ thể như sau:
- Thứ nhất, thay vì chỉ sử dụng ngữ cảnh từ trái sang hoặc từ phải sang như mô hình ngôn ngữ AR thông thường, XLNet sử dụng MLE đối với tất cả các hoán vị có thể có của các nhân tố. Nhờ đó, ngữ cảnh cho từng vị trí bao gồm cả các từ bên phải và bên trái. Với MLE, việc dự đoán từ ở mỗi vị trí sẽ sử dụng thông tin ngữ cảnh từ tất cách những vị trí xung quanh (ngữ cảnh hai chiều).
- Thứ hai, như một mô hình AR cơ bản, XLNet không dựa vào phương pháp che giấu dữ liệu. Do đó, XLNet không gặp phải vấn đề về hiệu năng như BERT trong các mô hình fine-tuning. Ngoài ra, tự hồi quy cũng cung cấp một cách thức tự nhiên để xác định xác suất gộp của từ cần dự đoán thông qua quy tắc nhân. Do đó, mô hình không bỏ sót mối quan hệ giữa các từ như vấn đề của BERT.
Ngoài ra, XLNet cũng được cải tiến về thiết kế của kiến trúc cho việc huấn luyện mô hình:
- Dựa trên kiến trúc tiến bộ nhất của mô hình ngôn ngữ AR, XLNet kết hợp cơ chế tái phân đoạn cùng với lược đồ mã hóa quan hệ của Transformer-XL. Điều này giúp mô hình cải thiện được hiệu năng, đặc biệt trong các nhiệm vụ liên quan đến một chuỗi văn bản dài.
- Áp dụng thuần túy kiến trúc Transformer (-XL) cho mô hình ngôn ngữ dựa trên hoán vị là bất khả thi. Thứ tự của các nhân tố là ngẫu nhiên và không có mục tiêu rõ ràng. Để giải quyết vấn đề này, các tác giả xác định lại tham số của Transformer (-XL) để loại bỏ nhập nhằng.
Để hiểu rõ hơn về dự khác biệt giữa BERT và XLNet, ta hãy cùng xem xét ví dụ sau:
[New, York, is, a, city]
Giả sử, cả hai mô hình BERT và XLNet đều lựa chọn hai token [New, York] là mục tiêu dự đoán và đều sử dụng MLE để tối đa hóa log p(New York | is a city). Và giả sử thêm rằng, XLNet lấy mẫu thứ tự của các nhân tố là [is, a, city, New, York].
Trong trường hợp này, BERT và XLNet có các hàm mục tiêu như sau:
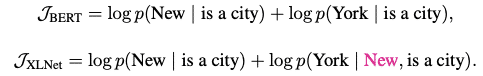
Lưu ý rằng, XLNet có thể ghi nhớ được sự phụ thuộc của cặp token (New, York), nhưng BERT không thể. Mặc dù trong ví dụ này, BERT có thể học được một số cặp như (New, city) hay (York, city), nhưng vẫn ít hơn số cặp phụ thuộc mà XLNet học được. Do đó, với cùng một dữ liệu huấn luyện, XLNet có thể nhận được nhiều tín hiệu hơn.
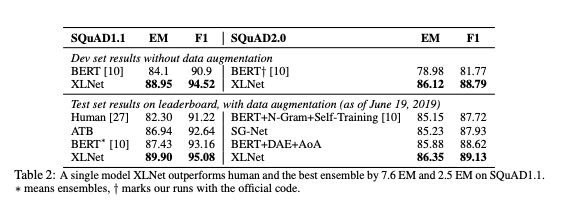
Bảng kết quả so sánh
Mô hình XLNet cho kết quả vượt trội kết quả của con người cũng như những mô hình Ensemble tốt nhất trên SQuAD 1.1 và 2.0.
Với bộ dữ liệu RACE, XLNet vượt trội hơn so với mô hình Ensemble tốt nhất với 7.6% độ chính xác. Điều này tương đương với một học sinh cải thiện được điểm số từ B lên A.

Bạn có thể tải mô hình Pre-trained và Code của XLNet tại đây.
Sau BERT, NLP ngày càng có nhiều những nghiên cứu mang tính đột phá hơn, đặc biệt trong năm 2019. Với đà này, chúng ta sẽ chứng kiến các cỗ máy có khả năng hiểu ngôn ngữ của con người trong thời gian rất ngắn.
Bạn đã sẵn sàng? Hãy theo dõi https://trituenhantao.io/ để có thêm nhiều bài viết về chủ đề này nhé!
-----