Ở bài trước, ta thấy cả 2 thuật toán Topic Modeling đều đưa ra kết quả có những dữ liệu nhiễu hay những chủ đề khó có thể tìm được tên. Vậy ta sẽ thực hiện cải thiện mô hình. Ý tưởng của phần này, chúng ta sẽ xem xét kĩ lại hai ma trận mà NMF và LDA trả về, bao gồm cả thao tác hiển thị kết quả của mỗi chủ đề từ bước ban đầu khi các tập tài liệu dài được đưa vào là tập dữ liệu.
Ma trận kết quả của NMF và LDA
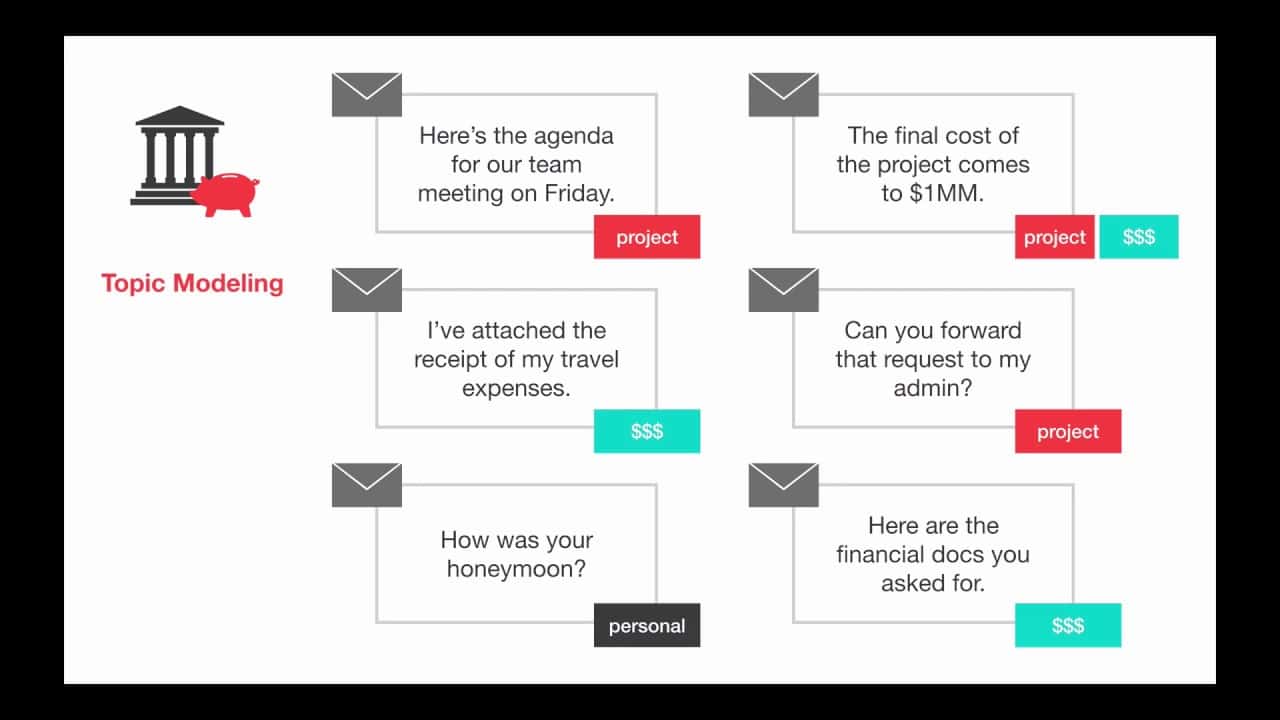
Đầu vào của NMF và LDA đều là túi ma trận từ (số tài liệu *số từ). Trong túi ma trận từ, tên tài liệu đươc biểu diễn dưới dạng hàng còn từ được từ được biểu diễn dưới dạng cột (như hình 1). Cả 2 thuật toán đều yêu cầu lựa chọn tham số “k” – số chủ đề. Đầu ra của 2 thuật toán là 2 ma trận: ma trận chủ đề cho tài liệu (số tài kiệu * số chủ đề “k”) và ma trận chủ đề cho từ (số chủ đề “k” * số lượng từ).
Tuy nhiên, hầu hết đầu ra của mô hình chủ đề chỉ sử dụng ma trân chủ đề từ và hiển thị các từ có trọng số cao nhất trong một chủ đề. Như vậy, ta có thể xác định tên chủ đề rõ hơn bằng cách hiển thị các tài liệu hàng đầu với một chủ đề.
Phân tích ma trận từ và tài liệu trọng tâm của mỗi chủ đề
Viết chương trình display_topics () mới giúp ta hiển thị cả ma trận chủ đề cho từ và ma trận chủ đề cho tài liệu như sau:
Tham số mô hình:
- Ma trận chủ đề cho từ (the words to topics matrix) (H)
- Ma trận chủ đè cho tài liệu (the topics to documents matrix) (W)
- Dữ liệu tài liệu (document)
- Số lượng từ quan trọng nhất (no_top_words)
- Số lượng tài liệu quan trọng nhất (no_top_document)
Phương thức này cho kết quả như sau: chủ đề, top những từ quan trọng nhất trong chủ đề, top những tài liệu quan trọng nhất trong chủ đề.
Ta sử dụng hàm argsort () để sắp xếp hàng/cột ma trận trả về theo thứ tự từ cao tới thấp.
def display_topics(H, W, feature_names, documents, no_top_words, no_top_documents):
for topic_idx, topic in enumerate(H):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
top_doc_indices = np.argsort( W[:,topic_idx] )[::-1][0:no_top_documents]
for doc_index in top_doc_indices:
print documents[doc_index]
Ta lấy ma trận chủ đề cho từ (H) và ma trận chủ đề cho tài liệu (W) của cả hai thuật toán NMF và LDA. Ta có thể dùng hàm fit () để lấy top những từ quan trọng trong chủ đề trong ma trận chủ đề cho từ. Tuy nhiên, với ma trận chủ đề cho tài liệu, sẽ có chút khó khăn hơn. Với thư viện Scikit Learn, hàm Transform () sẽ giúp ta lấy top những tài liệu quan trọng trong ma trận chủ đề cho tài liệu (W).
Ví dụ minh họa
Giả sử ta sử dụng bộ dữ liệu mẫu nhỏ dưới đây. Áp dụng thuật toán Topic Modeling, ta sẽ tìm chủ đề cho bộ dữ liệu này. Bộ dữ liệu này có hai chủ đề bao gồm giao diện người dùng (User Interfaces) và biểu đồ (Graphs/Trees). Bộ dữ liệu bao gồm 09 câu ngắn. Dưới dây là hướng dẫn cách thức thực hiện trên Python với 2 thuật toán NMF và LDA. Mục đích tìm ra 2 chủ đề, xuất kết quả ra top 4 từ quan trọng và 4 tài liệu quan trọng.
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import NMF, LatentDirichletAllocation
import numpy as np
def display_topics(H, W, feature_names, documents, no_top_words, no_top_documents):
for topic_idx, topic in enumerate(H):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
top_doc_indices = np.argsort( W[:,topic_idx] )[::-1][0:no_top_documents]
for doc_index in top_doc_indices:
print documents[doc_index]
# Single line documents from http://web.eecs.utk.edu/~berry/order/node4.html#SECTION00022000000000000000
documents = [
"Human machine interface for Lab ABC computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user-perceived response time to error measurement",
"The generation of random, binary, unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV: Widths of trees and quasi-ordering",
"Graph minors: A survey"
]
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
# LDA can only use raw term counts for LDA because it is a probabilistic graphical model
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, stop_words='english')
tf = tf_vectorizer.fit_transform(documents)
tf_feature_names = tf_vectorizer.get_feature_names()
no_topics = 2
# Run NMF
nmf_model = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf)
nmf_W = nmf_model.transform(tfidf)
nmf_H = nmf_model.components_
# Run LDA
lda_model = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
lda_W = lda_model.transform(tf)
lda_H = lda_model.components_
no_top_words = 4
no_top_documents = 4
display_topics(nmf_H, nmf_W, tfidf_feature_names, documents, no_top_words, no_top_documents)
display_topics(lda_H, lda_W, tf_feature_names, documents, no_top_words, no_top_documents)
Kết quả mô hình như sau:
Với mô hình NMF:
Topic 0:
trees graph minors survey
- Graph minors IV: Widths of trees and quasi-ordering
- The intersection graph of paths in trees
- The generation of random, binary, unordered trees
- Graph minors: A survey
Topic 1:
user time response interface
A survey of user opinion of computer system response time
Relation of user-perceived response time to error measurement
The EPS user interface management system
Human machine interface for Lab ABC computer applications
Với mô hình LDA:
Topic 0:
user response time computer
- A survey of user opinion of computer system response time
- Relation of user-perceived response time to error measurement
- The EPS user interface management system
- Human machine interface for Lab ABC computer applications
Topic 1:
trees graph human minors
- Graph minors IV: Widths of trees and quasi-ordering
- Graph minors: A survey
- The intersection graph of paths in trees
- Human machine interface for Lab ABC computer applications
Kết luận
Với bài toán Topic Modeling, việc xuất ra hết những từ/tài liệu quan trọng trong mỗi chủ đề không phải là điều tối ưu, đặc biệt với bộ dữ liệu lớn. Do vậy, giải pháp là ta chỉ hiển thị những từ/tài liệu thuộc top trong chủ đề. Điều này sẽ hữu ích nhất trong việc tìm được tên chủ đề. Ngoài ra, bạn có thể tham khảo công cụ trực quan LDAVis.
Nguồn: https://towardsdatascience.com
-----