Trong bài này, tôi sẽ cùng các bạn tìm hiểu về thuật toán cơ bản của phương pháp Supervised Learning (Học có giám sát) là thuật toán phân loại Naive Bayes. Bài viết được chia làm hai phần: phần đầu ta sẽ cùng tìm hiểu cách thức hoạt động của thuật toán Naive Bayes và phần tiếp theo ta sẽ sử dụng thư viện sklearn trên python để viết code thuật toán này và xem xét độ chính xác cho thuật toán.
Nào cũng bắt đầu nhé!
Đầu tiên, ta hãy xét một ví dụ sau. Hãy tưởng tượng chúng ta có hai người bạn là Alice và Bob. Và ta có những thông tin sau. Alice là người thường xuyên sử dụng những từ như:”love, great, wonderful” và Bob là người thường xuyên sử dụng những từ gồm: “dog, ball wonderful”.
Vào một ngày đẹp trời nào đó, bạn đột nhiên nhận được một email ẩn danh với nội dung: “I love beach sand. Additionally the sunset at beach offers wonderful view” . Khả năng là một trong hai người là Alice và Bob gửi email. Bạn có thể đoán được là ai với thông tin trên không?
Chính xác là Alice. Ta dựa theo những từ như “Love”, ” wonderful” được sử dụng.
Một trường hợp khác, ta nhận được mail với nội dung là: ” Wonderful Love. “. Bạn sẽ đoán là ai?
Đó chính là Bob. Nhưng nếu bạn không đoán ra được là ai, thì đừng quá lo lắng, trong trường hợp này, ta sẽ sử dụng Định lý Bayes.

Định lý Bases
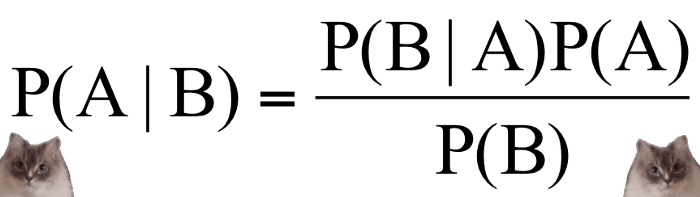
Công thức chỉ ra xác suất của A xảy ra nếu B cũng xảy ra, ta viết là P(A|B). Và nếu ta biết xác suất của B xảy ra khi biết A, ta viết là P(B|A) cũng như xác suất độc lập của A và B.
- P(A|B) là “xác suất của A khi biết B”
- P(A) là xác suất xảy ra của A
- P(B|A) là “xác suất của B khi biết A”
- P(B) là xác suất xảy ra của B
Ví dụ, P(lửa) là xác suất có lửa, P(khói) là xác suất ta nhìn thấy khói. Ta sẽ có những trường hợp sau:
P (Lửa | Khói) có nghĩa là tần suất có lửa khi chúng ta nhìn thấy khói. P (Khói | Lửa) có nghĩa là chúng ta thường thấy khói khi có lửa.
Công thức sẽ cho chúng ta biết được điều gì xảy ra tiếp theo nếu ta đã biết một điều.
Ví dụ: Một đám cháy nguy hiểm là có xác suất là 1% nhưng khói lại khá phổ biến là 10% (từ các nhà máy) và 90% đám cháy nguy hiểm tạo ra khói. Vậy ta có:
P (Lửa | Khói) = P (Lửa) P (Khói | Lửa) = 1% x 90% = 9% P (Khói) 10%
Trong trường hợp này, 9% khả năng thấy khói có nghĩa là có một đám cháy nguy hiểm.
Tương tự, bạn cũng có thể áp dụng với trường hợp của Bob và Alice chứ?
Phân loại Naive Bayes
Naive Bayes là một thuật toán phân loại cho các vấn đề phân loại nhị phân (hai lớp) và đa lớp. Kỹ thuật này dễ hiểu nhất khi được mô tả bằng các giá trị đầu vào nhị phân hoặc phân loại.
Thuật toán Naive Bayes tính xác suất cho các yếu tố, sau đó chọn kết quả với xác suất cao nhất.
Tuy nhiên, ta cần lưu ý giả định của thuật toán Naive Bayes là các yếu tố đầu vào được cho là độc lập với nhau.
Thuật toán này là một thuật toán mạnh mẽ trong các bài toán:
- Dự đoán với thời gian thực
- Phân loại Text/ Lọc thư rác
- Hệ thông Recommendation
Về mặt toán học, ta có thể viết như sau:
Nếu ta có một Class E và các điểm dữ liệu x1,x2,x3, etc.
Đầu tiên ta sẽ phải tính xác suất P(x1| E) , P(x2 | E) … (xác suất của x1 thuộc class E xảy ra) và sau đó ta sẽ chọn class có xác suất xảy ra x1 cao nhất.


Trên đây là toàn bộ lý thuyết về Phân loại Naive Bayes. Trong phần tiếp theo, tôi sẽ giới thiệu các bạn cách sử dụng thư viện sklearn trong Python và triển khai phân loại Naive Bayes để gắn nhãn email thành Spam hoặc không Spam.
Hi vọng bài viết giúp ích cho bạn.
Hãy theo dõi https://trituenhantao.io/ để có thêm nhiều bài viết mới nhé.
-----