
GPT – các mô hình sinh ngôn ngữ của OpenAI đã tạo ra một làn sóng mới trong xử lý ngôn ngữ tự nhiên. Các mô hình này có thể thực hiện các nhiệm vụ NLP khác nhau như trả lời câu hỏi, truy xuất văn bản, tóm tắt văn bản, v.v. mà không cần đến supervised training. Chúng cần rất ít hoặc không cần ví dụ để hiểu các nhiệm vụ và thực hiện tương đương hoặc thậm chí tốt hơn các mô hình state-of-the-art được huấn luyện có giám sát.

Trong bài viết này, chúng tôi sẽ giới thiệu về hành trình của các mô hình GPT để hiểu được chúng đã phát triển như thế nào trong khoảng thời gian chỉ 2 năm. Bài viết này sẽ phân tích các bài báo của GPT-1, GPT-2 và GPT3. Bài viết này giả định bạn đã quen với những kiến thức cơ bản cũng như thuật ngữ NLP và kiến trúc Transformer.
GPT-1: Improving Language Understanding by Generative Pre-Training
Trước công trình này, hầu hết các mô hình NLP state-of-the-art được huấn luyện chuyên biệt về một nhiệm vụ cụ thể như sentiment classification, textual entailment, v.v. sử dụng phương pháp supervised learning. Tuy nhiên, các mô hình supervised có hai hạn chế chính:
- Cần một lượng lớn dữ liệu được chú thích để học một nhiệm vụ cụ thể mà thường không dễ dàng có được.
- Không thể khái quát các nhiệm vụ khác với những gì đã được huấn luyện.
Paper này đề xuất học một mô hình ngôn ngữ chung sử dụng dữ liệu không được gắn nhãn và sau đó tinh chỉnh mô hình bằng cách cung cấp các ví dụ về các nhiệm vụ cụ thể.
Đối với unsupervised learning, GPT-1 sử dụng hàm loss cho mô hình ngôn ngữ chuẩn:
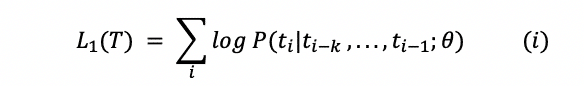
trong đó T là tập hợp các tokens trong dữ liệu unsupervised {t1,…, tn}, k là kích thước của cửa sổ context, θ là các tham số của mạng nơ-ron.
Hàm loss cho finetuning được thiết kế để dự đoán nhãn y dựa vào các đặc trưng x1, … xn .
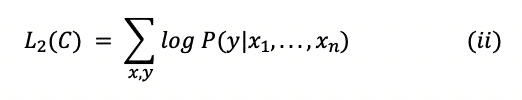
trong đó C là tập dữ liệu được gắn nhãn.
Thay vì chỉ tối đa hóa hàm mục tiêu được đề cập trong phương trình (ii), các tác giả kết hợp tối ưu hai hàm mục tiêu theo công thức:
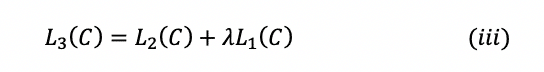
trong bài báo, λ có giá trị 0,5.
GPT-1 sử dụng BooksCorpus dataset chứa 7000 cuốn sách để huấn luyện mô hình ngôn ngữ. Corpus này chứa các đoạn văn bản liền kề lớn, giúp mô hình tìm hiểu các phụ thuộc trên phạm vi rộng.
GPT-1 đạt kết quả tốt hơn các mô hình state-of-the-art trên 9 trong số 12 nhiệm vụ mà các mô hình được so sánh. Quan trọng hơn, bài báo đã chứng minh rằng mô hình ngôn ngữ đóng vai trò trừu tượng hóa các khái niệm giúp cho GPT-1 có khả năng dự đoán zero-shot.
GPT-2: Language Models are Unsupervised Multitask Learners
Cải tiến của GPT-2 chủ yếu là sử dụng dataset lớn hơn và dùng mô hình nhiều tham số hơn. Chúng ta đã biết, hàm mục tiêu của mô hình ngôn ngữ được xây dựng dưới dạng P(output|input). Tuy nhiên, GPT-2 hướng đến việc học nhiều tác vụ bằng cách sử dụng cùng một mô hình unsupervised. Để đạt được điều đó, hàm mục tiêu được sửa đổi thành P(output|input, task).
Sửa đổi này được gọi là task conditioning, trong đó mô hình tạo ra output khác nhau với cùng một input cho các nhiệm vụ khác nhau.
Để tạo ra một tập dữ liệu lớn và chất lượng, các tác giả rà soát nền tảng Reddit và lấy dữ liệu từ các liên kết ngoài của các paper có uy tín. Tập dữ liệu kết quả được gọi là WebText, có 40GB dữ liệu văn bản từ hơn 8 triệu tài liệu. Tập dữ liệu này được sử dụng để huấn luyện GPT-2, nó lớn hơn nhiều so với tập dữ liệu của Book Corpus được sử dụng để huấn luyện GPT-1.
Các tác giả đã huấn luyện bốn mô hình ngôn ngữ với số các tham số lần lượt là 117 triệu (giống GPT-1), 345 triệu, 762 triệu và 1,5 tỷ tham số (GPT-2). Thông qua thực nghiệm, các mô hình sau có perplexity thấp hơn các mô hình trước, tức là có khả năng mô hình ngôn ngữ tốt hơn.
GPT-2 sau đó được đánh giá trên 8 bộ dataset và đạt kết quả tốt trên 7 bộ trong số chúng. Đối với tác vụ tóm tắt văn bản, GPT-2 hoạt động thậm chí chỉ ngang bằng hoặc kém hơn các cách tiếp cận cổ điển.
GPT-3: Language Models are Few-Shot Learners
GPT-3 có số tham số gấp 10 lần so với mô hình ngôn ngữ Turing NLG mạnh mẽ của Microsoft và gấp 100 lần so với GPT-2. Do có số lượng lớn các tham số và dataset phong phú, GPT-3 thực hiện tốt các tác vụ NLP với zero-shot và few-shot setting. Do dung lượng lớn, nó có khả năng viết các bài viết mà chúng ta khó có thể phân biệt với các bài viết của con người. Nó cũng có thể thực hiện các tác vụ nhanh chóng mà nó chưa bao giờ được huấn luyện một cách rõ ràng.
Trong few-shot setting, mô hình được cung cấp mô tả nhiệm vụ và nhiều ví dụ phù hợp với cửa sổ ngữ cảnh của mô hình. Trong one-shot setting, mô hình được cung cấp chính xác một ví dụ và trong zero-shot setting thì không có ví dụ nào được cung cấp. Với việc tăng dung lượng, khả năng của mô hình trong few, one và zero-shot cũng được cải thiện.
GPT-3 được huấn luyện trên sự kết hợp của năm kho tài liệu khác nhau là Common Crawl, WebText2, Books1, Books2 và Wikipedia.
GPT-3 chứng minh hiệu quả của mình trên một loạt các nhiệm vụ NLP. Ngoài ra, mô hình cũng được đánh giá về các tác vụ tổng hợp như cộng số học, giải mã từ, sinh tin tức, học và sử dụng từ mới v.v. Đối với những nhiệm vụ này, hiệu suất tăng lên cùng với sự gia tăng số lượng các tham số và mô hình hoạt động tốt hơn trong few-shot setting hơn là one hay zero-shot.
Bên cạnh sức mạnh của mình, GPT-3 tiềm ẩn nguy cơ lạm dụng khả năng tạo văn bản giống như con người để lừa đảo, gửi thư rác, truyền bá thông tin sai lệch hoặc thực hiện các hoạt động gian lận khác. Ngoài ra, văn bản do GPT-3 tạo ra có những thành kiến của ngôn ngữ mà nó được huấn luyện. Các bài báo được tạo bởi GPT-3 có thể có thành kiến về giới tính, dân tộc, chủng tộc hoặc tôn giáo. Do đó, điều cực kỳ quan trọng là phải sử dụng các mô hình như vậy một cách cẩn thận và xem xét văn bản được tạo ra trước khi sử dụng.
Hi vọng thông qua bài viết này các bạn đã hiểu thêm về hành trình của các mô hình GPT của OpenAI và có cho mình một số ý tưởng cho nghiên cứu của riêng bạn. Hãy chia sẻ bài viết với những người quan tâm và hãy thường xuyên truy cập website để có những thông tin mới và chuyên sâu về lĩnh vực.
-----