

Beam Search là thuật toán phổ biến trong các kiến trúc seq2seq hiện đại. Trong bài viết này, hãy cùng tìm hiểu Beam Search là gì và nó khác gì với tìm kiếm tham lam.


Các mô hình seq2seq sử dụng kiến trúc bao gồm encoder và decoder . Encoder mã hóa chuỗi đầu vào và chuyển đến decoder . Decoder có nhiệm vụ sinh ra chuỗi đầu ra ứng với thông tin nhận được từ encoder .
Ví dụ, ta cần dịch một câu sang tiếng Anh. Chúng ta mong muốn chuỗi đầu ra không chỉ là một tập hợp lộn xộn của các từ mà là một câu hoàn chỉnh trong tiếng Anh có cùng ý nghĩa với câu đầu vào.

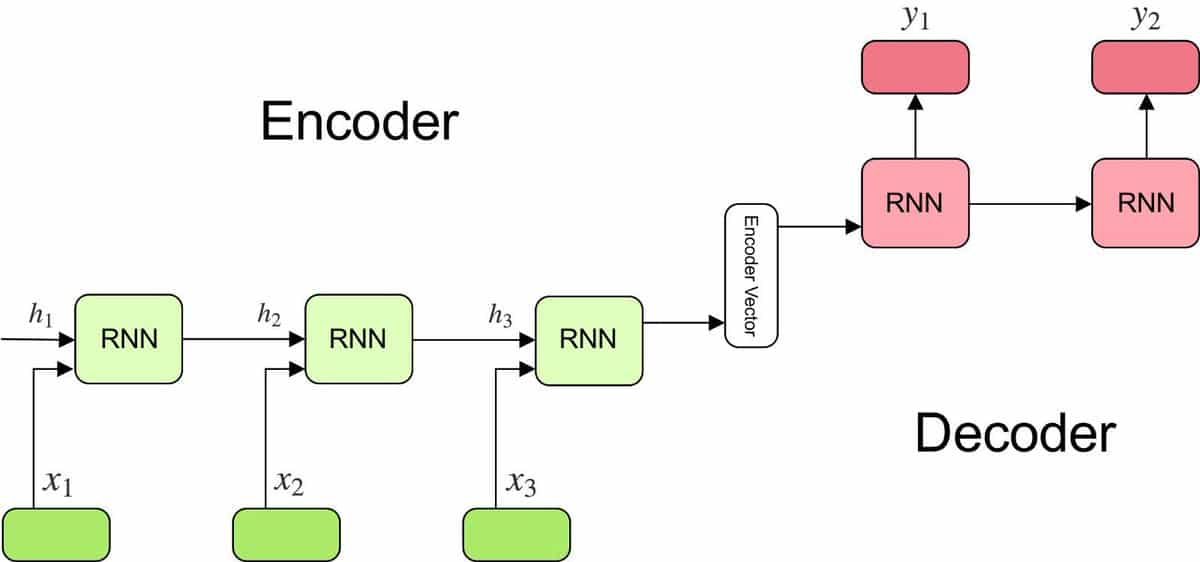
Cách thức đơn giản cho việc này là với một tập từ vựng trong ngôn ngữ đích (ví dụ có 10 nghìn từ), dựa trên câu đầu vào, ta tính xác suất của từng từ trong 10K từ đó.
Thuật toán tìm kiếm tham lam sẽ chọn ra ứng viên tốt nhất cho mỗi bước tính toán. Mặc dù vậy, ứng viên tốt nhất cho bước hiện tại không đảm bảo sẽ là ứng viên tốt nhất cho toàn bộ câu. Mục tiêu của chúng ta không phải là dịch word-by-word mà là tìm ra bản dịch tốt nhất cho toàn bộ câu đầu vào.
Beam search chọn ra một vài ứng viên cho mỗi bước tính toán dựa trên xác suất có điều kiện. Số lượng ứng viên là tham số mang tên Beam Width .
Hãy lấy một ví dụ, ta cần dịch câu “Tôi sẽ về thăm ba mẹ ở Việt Nam.”, giả sử chúng ta đặt beam width = 3 và tập từ vựng tiếng Anh chứa 10K từ.
Bước 1: Tìm ra 3 từ có xác suất lớn nhất ứng với đầu vào
- Khi đưa đầu vào được mã hóa vào decoder , mô hình sẽ dùng hàm softmax lên toàn bộ 10K từ.
- Trong 10K khả năng, mô hình lựa chọn 3 từ có xác suất lớn nhất.
- Lưu 3 từ có xác suất lớn nhất vào bộ nhớ. Ví dụ, 3 từ đó là I, My và We.
Khác với Beam Search, tìm kiếm tham lam sẽ luôn chọn ra một từ có xác suất cao nhất.
Bước 2: Tìm ra 3 cặp gồm từ đầu tiên và từ thứ hai có xác suất có điều kiện lớn nhất
- Lấy 3 từ (I, My, We) từ bước 1 bổ sung đầu vào cho bước 2
- Dùng hàm softmax lên 10K từ để tìm ra 3 từ tốt nhất cho bước 2. Việc lựa chọn này có xét đến xác suất có điều kiện giữa từ đầu tiên (bước 1) và từ thứ 2 (bước 2).
- Giả sử như 3 cặp có xác suất cao nhất là: “I am”, “My parents”, và “I will”. Chúng ta loại bỏ từ “We” vì nó không còn xuất hiện trong bước này.
- Tại mỗi bước, ta khởi tạo 3 bản sao của mạng để đánh giá đầu ra. Số lượng bản sao bằng với tham số beam width .
Bước 3: Xác định từ thứ 3 tương tự như bước 2
- Từ cặp từ đầu tiên “I am”, “My parents”, và “I will”, tìm ra từ thứ 3 với xác suất cao nhất.
- Giả sử ta có 3 ứng viên tốt nhất là “I am visiting”, “I will visit”, và “I am going”, ta loại bỏ “My parents” khỏi tập ứng viên.
Ta tiếp tục quá trình cho đến khi có được 3 ứng viên hoàn chỉnh với các xác suất có điều kiện tương ứng. Ta sẽ chọn ra ứng viên có xác suất cao nhất làm đầu ra cuối cùng.
| Câu | Xác suất |
| I am going to meet my parents in Vietnam. | 0.72 |
| I am visiting my parents in Vietnam. | 0.67 |
| I will visit Vietnam to meet my parents. | 0.62 |
Giá trị beam width càng lớn, khả năng chúng ta có được bản dịch tốt là cao hơn nhưng nó cũng tốn nhiều bộ nhớ và năng lực tính toán hơn. Việc đánh đổi giữa chất lượng và chi phí tính toán là vấn đề muôn thuở của Khoa học máy tính.
Hi vọng thông qua bài này, bạn đã hình dung sơ bộ khái niệm và cách thức hoạt động của beam search. Nếu bạn thích bài viết này, đừng ngại chia sẻ với những người quan tâm. Hãy thường xuyên truy cập website để ôn lại các kiến thức và cập nhật những tin tức mới nhất về lĩnh vực.